Mengenal Convolutional Neural Network (CNN)
Summary
TLDRThis video explains the fundamentals of Convolutional Neural Networks (CNNs), focusing on their use in image and video processing. It contrasts CNN's convolution layers with fully connected layers, highlighting the key differences in how they process data. The video delves into parameters like kernel size, stride, and padding, and explains their role in designing convolution layers. Additionally, it introduces various types of convolution layers (e.g., 1D, 2D, 3D) and their functions in AI research. Viewers are encouraged to subscribe for more insights into AI developments and convolution layers.
Takeaways
- 😀 Convolutional Neural Network (CNN) is a deep learning method commonly used to process image or video data.
- 😀 CNN consists of a convolution layer, unlike previous deep learning networks with fully connected layers.
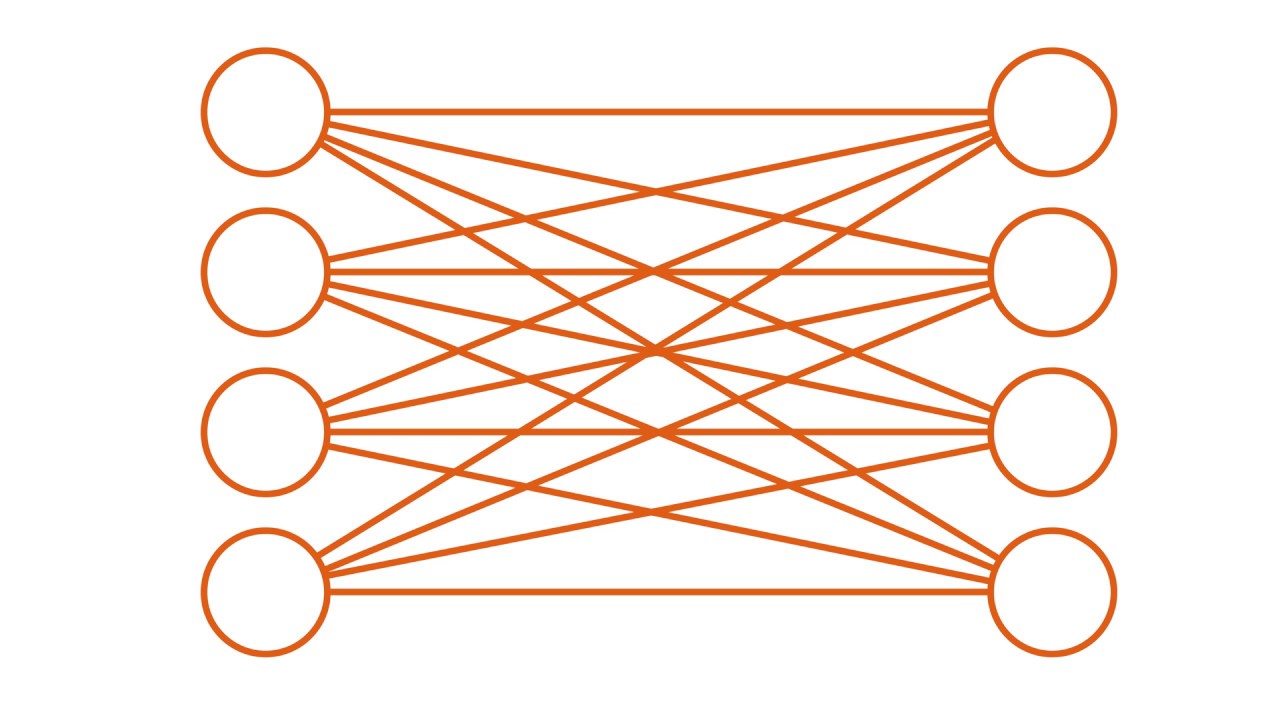
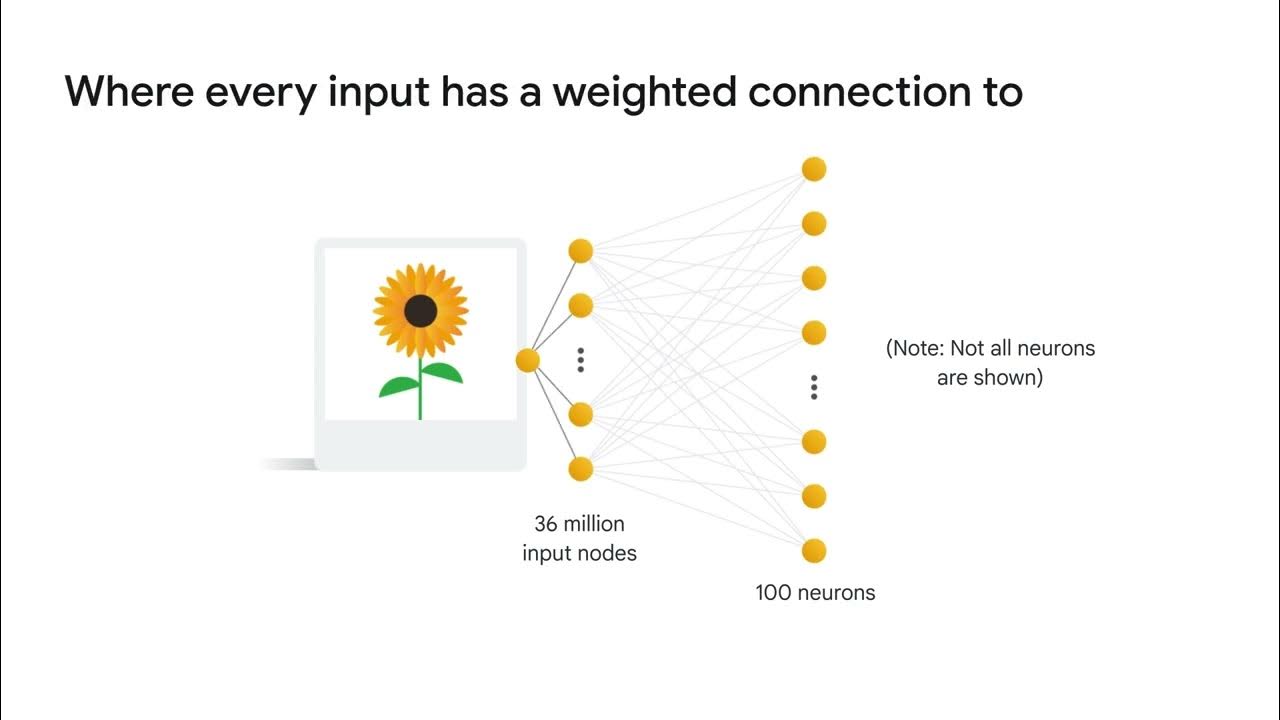
- 😀 A fully connected layer connects every pixel of the input image to each output, including all color channels.
- 😀 A convolution layer, on the other hand, processes input locally and shares parameters across different sections of the input.
- 😀 In CNN, kernel size defines how local the convolution layer is, with common sizes being 1x1, 3x3, or 5x5.
- 😀 The stride determines how far the kernel moves during convolution, which impacts the amount of input information skipped.
- 😀 Padding is added to the input to ensure the output size matches the input size, especially with larger kernel sizes.
- 😀 Padding is typically set to zero, and for a 3x3 kernel with stride 1, padding size of 1 ensures the output size remains the same.
- 😀 CNN models, like AlexNet, consist of both convolution layers and fully connected layers, where convolution layers extract features.
- 😀 The output from convolution layers is known as a feature map, which is later used for classification in fully connected layers.
- 😀 CNNs can use different types of convolution layers, such as 1D, 2D, 3D, dilated, transpose, depthwise, and deformable convolutions, with ongoing research into new types.
Q & A
What is the main difference between a fully connected layer and a convolution layer in CNN?
-A fully connected layer connects every pixel in the image to every output, whereas a convolution layer processes the image in small local regions and shares the same parameters across these regions.
What is the role of the convolution layer in CNNs?
-The convolution layer's main role is to extract features from the input image, resulting in a feature map that can be used for classification or other tasks.
What does the kernel size in a convolution layer refer to?
-The kernel size refers to the size of the filter that slides across the image during convolution, such as 1x1, 3x3, or 5x5.
What does stride mean in the context of a convolution layer?
-Stride refers to the step size by which the convolution filter moves across the image. A larger stride reduces the output size and the computational load.
Why is padding used in convolution layers?
-Padding is used to maintain the original size of the output by adding extra pixels around the image, preventing the output from becoming too small after convolution.
What is the significance of AlexNet in deep learning?
-AlexNet is a famous CNN that won the 2012 ImageNet competition, marking a significant milestone in the deep learning revolution. It consists of 5 convolution layers followed by 3 fully connected layers.
What is a feature map in CNN?
-A feature map is the result of applying a convolution operation on the input image, representing the extracted features at different spatial locations.
What are the different types of convolution layers mentioned in the video?
-The video mentions several types of convolution layers, including 1D, 2D, 3D convolutions, dilated convolutions, transpose convolutions, depthwise convolutions, and deformable convolutions.
What is the impact of using a smaller stride in a convolution layer?
-A smaller stride results in a finer resolution of the output since the filter moves step by step, capturing more detail from the input image.
How does the size of the kernel affect the output size in a convolution layer?
-A larger kernel size reduces the output size since the filter covers a larger area of the input image. To maintain the output size, padding is often added.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
What is a convolutional neural network (CNN)?

TUGAS PEMROSESAN CITRA DIGITAL (RESUME TENTANG KONVOLUSI)

ANN vs CNN vs RNN | Difference Between ANN CNN and RNN | Types of Neural Networks Explained

Neural Networks Part 8: Image Classification with Convolutional Neural Networks (CNNs)
Convolutional Neural Networks

Taxonomy of Neural Network
5.0 / 5 (0 votes)