Neural Networks Part 8: Image Classification with Convolutional Neural Networks (CNNs)
Summary
TLDRIn this StatQuest episode, Josh Starmer explains the fundamentals of image classification using Convolutional Neural Networks (CNNs). He illustrates how CNNs reduce input size, handle pixel correlations, and tolerate image shifts for better classification. Using a tic-tac-toe example, he demonstrates the process of applying filters, creating feature maps, and utilizing max pooling to recognize images of 'X' and 'O'. The video simplifies complex concepts, making machine learning accessible and engaging.
Takeaways
- 🧠 Convolutional Neural Networks (CNNs) are used for image classification tasks, such as distinguishing between the letters 'X' and 'O' in a game of tic-tac-toe.
- 🔍 CNNs are designed to handle the challenges of image recognition, including large image sizes, pixel shifts, and correlated pixel patterns.
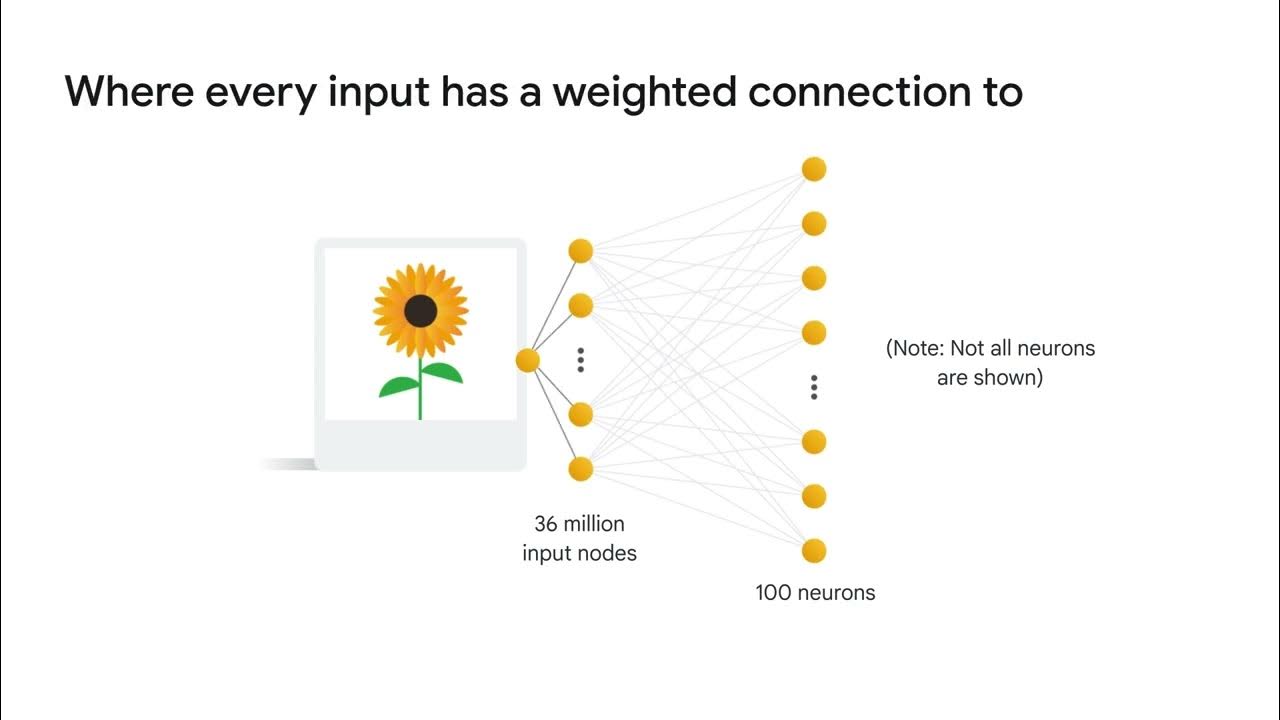
- 🔢 A simple neural network for a 6x6 pixel image would require estimating a large number of weights, which is impractical for larger images.
- 🖼️ CNNs reduce the number of input nodes by using filters that slide over the image and compute dot products to create feature maps.
- 🔄 The process of applying a filter to an image is known as convolution, which is fundamental to how CNNs are named and operate.
- 🎚️ After applying filters, CNNs often use a ReLU (Rectified Linear Unit) activation function to introduce non-linearity and help in learning complex patterns.
- 🔑 Max pooling is a technique used in CNNs to reduce the spatial size of the representation, focusing on the most activated features.
- 🔄 CNNs are robust to small shifts in the input image due to the overlapping nature of the filters and pooling operations.
- 📊 The final layer of a CNN typically consists of a fully connected neural network that uses the output from the feature maps to make a classification decision.
- 🎉 Despite their complexity, CNNs are built upon the simple operations of filtering, activation, and pooling, making them versatile for various image classification tasks.
Q & A
What is the primary purpose of using convolutional neural networks (CNNs)?
-Convolutional neural networks are primarily used for image classification and other tasks that involve processing grid-like data.
Who is the presenter in the StatQuest video about CNNs?
-The presenter in the StatQuest video about CNNs is Josh Starmer.
What are the prerequisites for understanding the content of the video?
-Understanding the main ideas behind neural networks, backpropagation, the ReLU activation function, and neural networks with multiple inputs and outputs are prerequisites for the video.
Why does the computer need to determine whether Statsquatch drew an 'X' or an 'O' in the tic-tac-toe game?
-The computer needs to determine whether Statsquatch drew an 'X' or an 'O' to play tic-tac-toe effectively and to respond accordingly in the game.
How does a CNN reduce the number of input nodes compared to a traditional neural network?
-A CNN reduces the number of input nodes by using filters that slide over the input image and create feature maps, which are then reduced further through pooling, resulting in fewer inputs to the subsequent layers.
What is a filter in the context of convolutional neural networks?
-A filter in CNNs is a small matrix, typically 3x3 pixels, that slides over the input image to detect features. The values of the filter are learned during training using backpropagation.
What is the significance of the term 'convolution' in convolutional neural networks?
-The term 'convolution' refers to the process of sliding the filter over the input image and computing the dot product between the filter and the overlapping pixels, which is a key operation in CNNs.
How does a CNN tolerate small shifts in the image?
-CNNs tolerate small shifts in the image because the filters detect features regardless of their exact position in the input, allowing the network to recognize features even when they are slightly offset.
What is the role of the ReLU activation function in a CNN?
-The ReLU activation function in a CNN is used to introduce non-linearity into the model by setting all negative values to zero and leaving positive values unchanged, which helps in learning complex patterns.
What is max pooling and how does it help in CNNs?
-Max pooling is a technique where the maximum value in a region of the feature map is selected, reducing the spatial size of the representation and making the model less sensitive to the exact location of features.
How does the CNN handle the classification of an image of the letter 'O'?
-The CNN classifies an image of the letter 'O' by applying filters to the input image, creating a feature map, applying ReLU, performing max pooling, and finally using a traditional neural network to classify the image based on the activated features.
What is the purpose of the bias term in the context of CNN filters?
-The bias term in CNN filters is added to the dot product result before the activation function to allow the model to learn patterns that are not perfectly centered at the origin in the input space.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video




5.0 / 5 (0 votes)