Congestion Management in an Ethernet based network for AI Cluster Fabric
Summary
TLDRIn this presentation, experts from Drivet and Acton explore effective methods for managing congestion in large AI GPU clusters. They discuss two primary strategies: congestion avoidance through Distributed Disaggregated Chassis (DDC) and congestion control via endpoint scheduling. The session outlines network-related issues, such as packet drops and delays, and emphasizes optimizing GPU utilization by mitigating these bottlenecks. Through a series of lab experiments and comparisons using advanced testing tools, the team demonstrates the performance differences between these approaches, providing valuable insights on when to use each strategy depending on workload type, latency sensitivity, and resource allocation.
Takeaways
- 😀 Networking issues, such as packet drop, out-of-order delivery, and jitter, can lead to underutilization of GPUs in large AI GPU clusters.
- 😀 The goal in AI cluster networking is to maximize GPU utilization and prevent idle cycles caused by networking bottlenecks.
- 😀 Two main approaches to solving networking congestion are congestion avoidance (e.g., DDC) and congestion control (e.g., endpoint scheduling).
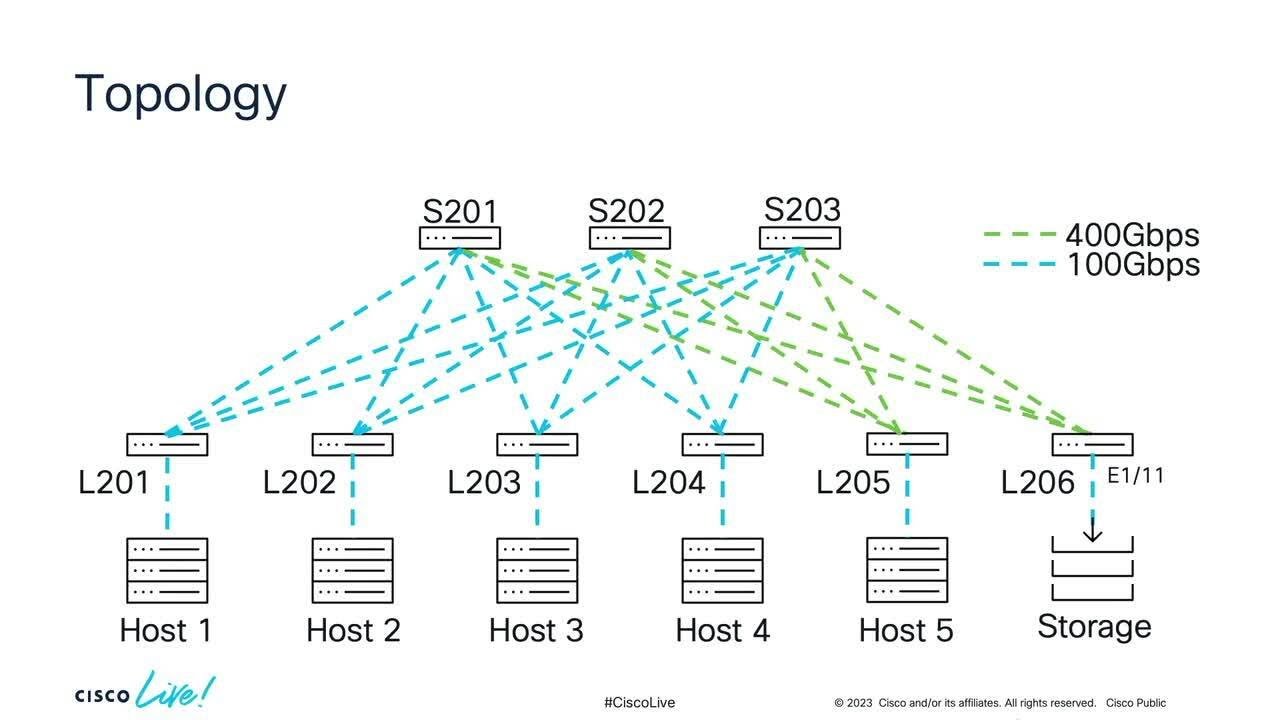
- 😀 DDC (Distributed Disaggregated Chassis) provides a congestion-avoidance solution by using a cell-based architecture that spreads packets evenly across the network fabric.
- 😀 Endpoint scheduling manages congestion at the end device (e.g., GPUs) level, where Nicks spread packets across the network to reduce congestion.
- 😀 AI clusters typically experience low entropy networking, leading to bottlenecks and elephant flows, where large flows cause congestion and packet loss.
- 😀 The experimental setup for congestion management includes both the DDC fabric and endpoint scheduling, testing performance and mitigation strategies.
- 😀 Testing in small lab environments helps users who can't afford large-scale infrastructure to experiment and gain hands-on experience with congestion management strategies.
- 😀 The testing setup uses Spirent tools to emulate and measure congestion, providing a consistent testing environment for both endpoint and fabric scheduling solutions.
- 😀 Tomahawk 5, a high-performance chip, is used in endpoint scheduling to explore dynamic load balancing, packet spray, and PFC tuning to optimize performance and reduce congestion.
- 😀 Fabric scheduling can perform better with less fine-tuning compared to endpoint scheduling, which requires more detailed configuration to reach optimal performance in certain environments.
- 😀 The choice between endpoint scheduling and fabric scheduling depends on workload characteristics, including job consistency and latency sensitivity, as well as resource availability for fine-tuning.
Q & A
What is the main issue discussed in the transcript regarding AI GPU clusters?
-The main issue discussed is congestion management in AI GPU clusters, specifically how networking bottlenecks can cause GPUs to remain idle due to inadequate networking resources.
What are the two primary approaches to resolving networking congestion in AI clusters mentioned in the script?
-The two primary approaches mentioned are: 1) Avoiding congestion altogether through Distributed Disaggregated Chassis (DDC) and 2) Mitigating congestion via congestion control at the endpoint level, specifically through endpoint scheduling.
How does DDC work to prevent congestion in the network fabric of an AI GPU cluster?
-DDC works by turning the entire architecture of top-of-rack and end-of-row switching into a single distributed network entity, which prevents packet drop and congestion by evenly distributing traffic across the fabric using a cell-based architecture.
What is the role of the network's fabric and how does it prevent congestion?
-The network fabric, through the use of cell-based architecture and mechanisms like scheduling and traffic management, ensures that packets are evenly distributed across the network, preventing congestion and packet loss.
What is the problem with low entropy environments in AI GPU clusters and how does it relate to congestion?
-Low entropy environments are characterized by large, uniform flows of data that travel the same path across the network, causing bottlenecks and congestion. These are commonly known as 'elephant flows,' and they lead to packet drops and network inefficiencies.
What factors should be considered when deciding between DDC and endpoint scheduling for congestion management?
-Factors include the nature of the workload, the scale of the AI cluster, whether the system is running similar or fluctuating workloads, and the required latency for different types of tasks (training vs. inference).
Why is fine-tuning required for endpoint scheduling and what does it involve?
-Fine-tuning is required to optimize performance, as endpoint scheduling involves multiple parameters (such as ECN, PFC, buffer sizes, and marking probabilities) that must be adjusted to avoid packet loss and ensure efficient use of resources.
What are the challenges associated with endpoint scheduling as discussed in the script?
-The challenges include managing packet order when using packet spraying, tuning the ECN parameters effectively, and the effort required to fine-tune the system for optimal performance.
What testing tools and methods were used to simulate and evaluate the congestion management strategies?
-The testing involved using Spirent's network testing tools in combination with Tomahawk 5 chips, Edgecore switches, and Broadcom's DNX architecture to simulate various congestion management strategies, such as dynamic load balancing and ECN tuning.
What were the findings regarding the performance of DDC and endpoint scheduling in terms of job completion time (JCT)?
-The results showed that scheduled fabric (DDC approach) outperformed endpoint scheduling (Tomahawk 5) in terms of job completion time (JCT) due to its simpler implementation and lower need for fine-tuning. However, fine-tuned endpoint scheduling could approach the performance of scheduled fabric in smaller-scale setups.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
Cisco Artificial Intelligence and Machine Learning Data Center Networking Blueprint

Streamlined AI Development with NVIDIA DGX Cloud

How An Internship Led To Billion Dollar AI Startup

Told You Nvidia Will 100x Now Mark My Words These Stocks Will 10x This Year

🔴 How to select Participants: Quantitative Research

Faster Than Fast: Networking and Communication Optimizations for Llama 3
5.0 / 5 (0 votes)