Intro to Data Lakehouse
Summary
TLDRThe data lake house emerges as a modern data management architecture, combining the storage capabilities of a data lake with the analytical strengths of a data warehouse. It addresses the limitations of traditional data warehouses and early data lakes by offering transaction support, schema enforcement, robust data governance, and the ability to handle diverse data types and workloads. This unified system supports AI, BI, real-time analysis, and end-to-end streaming, enhancing data exploration and predictive analytics without compromising flexibility.
Takeaways
- 📈 In the late 1980s, businesses began seeking data-driven insights for decision-making and innovation, leading to the development of data warehouses to manage and analyze high-volume data.
- 🔍 Data warehouses were designed to structure and clean data with predefined schemas, but they were not optimized for semi-structured or unstructured data, which became a limitation as data variety increased.
- 🚀 The early 2000s saw the rise of Big Data, prompting the creation of data lakes to accommodate the diverse data types and high-speed data collection, offering a more flexible storage solution than traditional data warehouses.
- 💡 Data lakes solved storage issues but introduced concerns about data reliability, slower analysis performance, and governance challenges due to their unstructured nature.
- 🔧 The complexity of managing multiple systems for data storage and analysis led to the development of the data lake house, which combines the benefits of data lakes with the analytical capabilities of data warehouses.
- 🛠️ Data lake houses support transactional data, enforce schema governance, and provide robust auditing and data governance features, addressing the shortcomings of early data lakes.
- 🔄 They offer decoupled storage and compute, allowing for independent scaling to meet specific needs and supporting a variety of data types and workloads.
- 🌐 Data lake houses use open storage formats like Apache Parquet, enabling diverse tools and engines to access data efficiently.
- 🤖 The architecture supports AI and BI applications, providing a single, reliable source of truth for data analysis and predictive modeling.
- 👥 It streamlines the work of data analysts, data engineers, and data scientists by providing a unified platform for data management and analysis.
- 📊 The data lake house is essentially a modernized data warehouse, offering all the benefits without sacrificing the flexibility and depth of a data lake.
Q & A
What is the primary purpose of a data lake house?
-The data lake house is designed to combine the benefits of a data lake, which can store all types of data, with the analytical power and controls of a data warehouse. It aims to provide a single, reliable source of truth that supports AI and BI applications, offering direct access to data for various analytical needs.
How did the evolution of data management lead to the creation of data warehouses in the late 1980s?
-In the late 1980s, businesses sought to leverage data-driven insights for decision-making and innovation. This need outgrew simple relational databases, leading to the development of data warehouses that could manage and analyze the increasing volumes of data being generated and collected at a faster pace.
What limitations did data warehouses have when it came to handling Big Data?
-Data warehouses were primarily designed for structured data with predefined schemas. They struggled with semi-structured or unstructured data, leading to high costs and inefficiencies when trying to store and analyze data that didn't fit the schema. Additionally, they were not optimized for the velocity and variety of data types that became common with the advent of Big Data.
What challenges did data lakes introduce in data management?
-While data lakes solved the storage issue for diverse data types, they introduced concerns such as lack of transactional support, questionable data reliability due to various formats, slower analysis performance, and challenges in governance, security, and privacy enforcement due to the unstructured nature of the data.
How does a data lake house address the shortcomings of traditional data warehouses and data lakes?
-A data lake house integrates the best of both worlds: it supports all data types like a data lake and provides transaction support, schema enforcement, data governance, and robust auditing like a data warehouse. It also offers features like decoupled storage from compute, open storage formats, and support for diverse workloads, making it a flexible and high-performance system.
What are some key features of data lake houses like the Databricks Lakehouse platform?
-Key features include ACID transaction support for concurrent read-write interactions, schema enforcement for data integrity, robust auditing and data governance, BI support for reduced insight latency, and end-to-end streaming for real-time reports. They also support diverse data types and workloads, allowing for data science, machine learning, and SQL analytics to use the same data repository.
How does the data lake house architecture benefit data teams?
-The data lake house architecture allows data analysts, data engineers, and data scientists to work in one location, streamlining their processes. It supports a variety of data applications, including SQL analytics, real-time analysis, and machine learning, and reduces the complexity and delay associated with managing multiple systems.
Why was there a need for a new data management architecture like the data lake house?
-The need arose because businesses required a single, flexible, high-performance system to support increasing data use cases for exploration, predictive modeling, and analytics. The existing complex technology stack environments with data lakes and data warehouses were costly and operationally inefficient, leading to only a small percentage of companies deriving measurable value from their data.
What is the significance of open storage formats like Apache Parquet in a data lake house?
-Open storage formats like Apache Parquet are standardized and allow a variety of tools and engines to access the data directly and efficiently. This interoperability is crucial for a data lake house, as it enables different analytical workloads to operate on the same data set without the need for data duplication or transformation.
How does the data lake house approach differ in handling data variety and velocity compared to traditional data warehouses?
-The data lake house is built to handle a wide range of data types and the high velocity at which data is generated and collected. Unlike traditional data warehouses, which were limited in their ability to process and analyze diverse data quickly, data lake houses are designed to manage and analyze both structured and unstructured data at scale, making them better suited for the modern data landscape.
What is the impact of the data lake house on the implementation of AI and actionable outcomes?
-The data lake house facilitates successful AI implementation by providing a unified platform where data can be stored, processed, and analyzed efficiently. It enables actionable outcomes by reducing the latency between data acquisition and insights, supporting a seamless flow of data for various analytical processes, and ensuring data quality and governance.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes
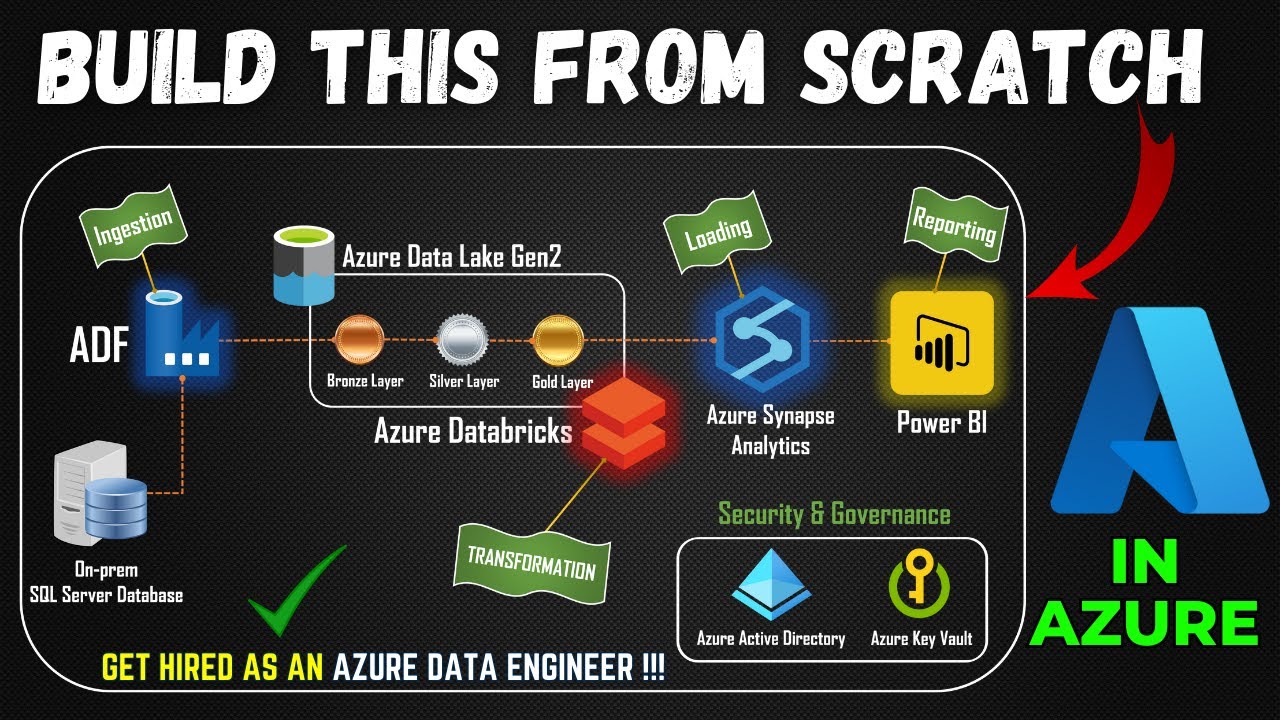
Part 1- End to End Azure Data Engineering Project | Project Overview

Data Warehouse vs Data Lake | Explained (non-technical)

51. Databricks | Pyspark | Delta Lake: Introduction to Delta Lake

What is Databricks? | Introduction to Databricks | Edureka

The Value of the Lakehouse: How T-Mobile Articulated the Benefit of a Modern Data Platform

IoT Architecture: Data Flow, Components, Working and Technologies Explained
5.0 / 5 (0 votes)
