Delete Nodes From Linked List Present in Array - Leetcode 3217 - Python
Summary
TLDRIn this coding tutorial, the focus is on solving the problem of deleting nodes from a linked list that are present in an array. The video demonstrates the use of a hash set for efficient lookup, which reduces the time complexity to O(n+m). A dummy node is introduced to simplify the removal process, and a two-pointer approach is explained to iterate through the list and remove the nodes. The tutorial also covers a one-pointer alternative for deletion. The video concludes with a live coding session, showcasing the efficiency of the solution.
Takeaways
- 📝 The video tutorial focuses on solving the problem of deleting nodes from a linked list based on values present in an array.
- 🔍 The presenter suggests using a hash set for constant time lookups to determine if a node's value exists in the given array.
- 🔑 The idea is to iterate through each node of the linked list and remove it if its value is found in the hash set.
- 🔁 The tutorial introduces the concept of a 'dummy node' to simplify the process of node deletion in a linked list.
- 💡 The presenter explains that with a dummy node, you can handle edge cases like deleting the head of the list more easily.
- 🔭 The video demonstrates a two-pointer approach to traverse and modify the linked list, keeping track of the current and previous nodes.
- ⏱️ The time complexity of the algorithm is discussed as O(n + m), where n is the length of the linked list and m is the size of the array.
- 💾 Space complexity is noted as O(n) due to the additional hash set data structure used for lookups.
- 👨💻 The presenter provides a step-by-step coding example in Python, emphasizing the importance of not skipping nodes during deletion.
- 🔄 An alternative single-pointer approach is also discussed, showing adaptability in solving the problem with different methods.
- 📢 The tutorial ends with a call to action for viewers to subscribe for more content on data structures, system design, and related topics.
Q & A
What problem is the video tutorial addressing?
-The video tutorial is addressing the problem of deleting nodes from a linked list that are present in a given array.
What is the expected outcome if all nodes in the linked list are removed?
-If all nodes in the linked list are removed, the head of the remaining list could be null, indicating an empty list.
Why does the tutorial suggest using a hash set for lookup?
-The tutorial suggests using a hash set for lookup because it provides constant time complexity for lookups, making the process more efficient compared to linear scans.
What is the role of a dummy node in linked list problems?
-A dummy node simplifies the process of modifying a linked list, especially when dealing with edge cases such as removing the head of the list or nodes from the beginning.
How does the tutorial propose to remove a node from the linked list?
-The tutorial proposes using a two-pointer approach where one pointer keeps track of the previous node and the other of the current node, adjusting the pointers to effectively remove the current node if its value is in the hash set.
What is the time complexity of the algorithm described in the tutorial?
-The time complexity of the algorithm is O(n + m), where n is the number of nodes in the linked list and m is the size of the array.
What is the space complexity of the algorithm?
-The space complexity of the algorithm is O(n), which is due to the additional space used by the hash set to store the values from the array.
Why does the tutorial mention not shifting the previous pointer when a node is deleted?
-Shifting the previous pointer when a node is deleted could lead to skipping a node in the list, which is incorrect behavior for the problem at hand.
What alternative method does the tutorial suggest for solving the problem?
-The tutorial suggests an alternative method using only one pointer, which simplifies the code by always moving the pointer one step ahead.
How does the tutorial ensure that the original order of the nodes is maintained after deletions?
-The tutorial ensures that the original order is maintained by only adjusting the pointers to skip over the nodes that are to be deleted, without changing the order of the remaining nodes.
What additional resources does the tutorial mention for further learning?
-The tutorial mentions a free newsletter and upcoming system design videos as additional resources for further learning on data structures, system design, and more.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados

Data Structures in Python: Doubly Linked Lists -- Delete Node
Struktur Data Pertemuan 4

doubly linked list: #1 Konsep dan Deklarasi Node

Can you ? Virtusa Important Coding Questions | Virtusa Online Assessment Test 2025 | Tekno UF
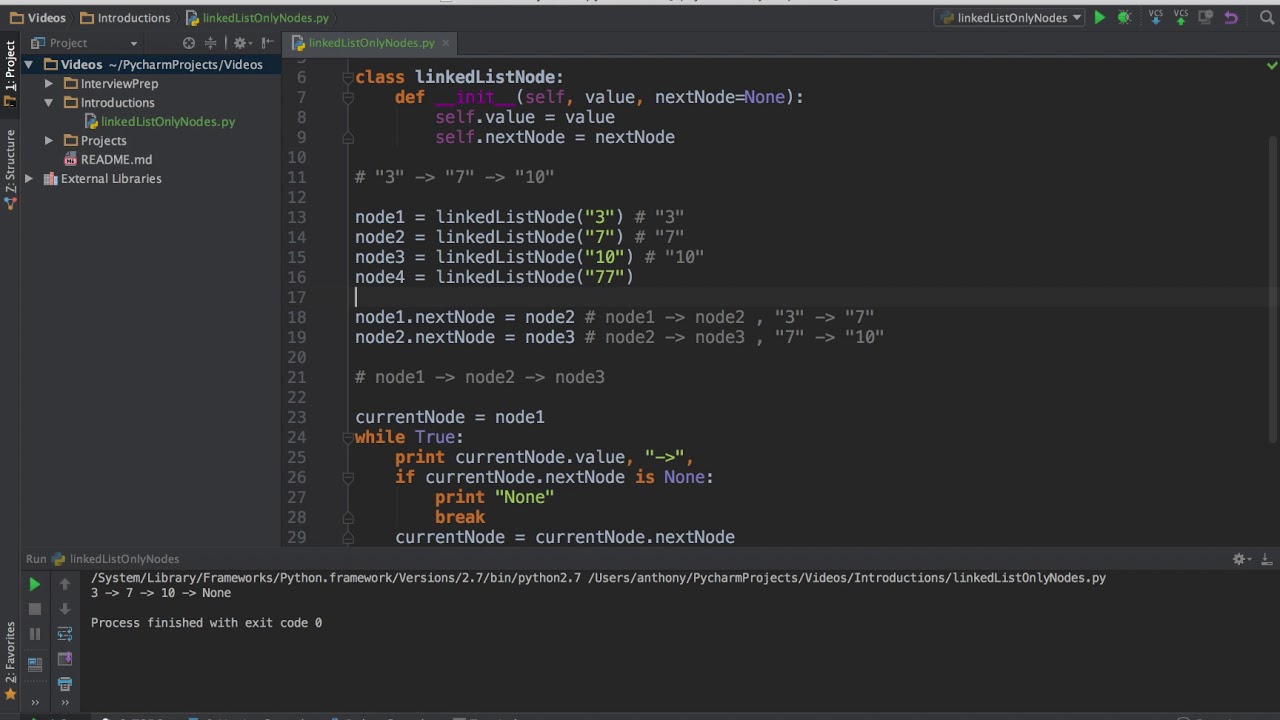
2 Simple Ways To Code Linked Lists In Python

Deleting the Entire Single Linked List
5.0 / 5 (0 votes)
