100+ Statistics Concepts You Should Know
Summary
TLDRThis video introduces statistics as a means to control information and make sense of randomness in data. It covers key statistical concepts like types of data, probability distributions, measures of central tendency and variation, hypothesis testing, sampling distributions, confidence intervals, regression modeling, experimental design, parametric vs nonparametric models, prediction, machine learning models, causal inference, counterfactuals, robust statistics, and recommendations for learning statistics like R programming and simulation.
Takeaways
- 😀 Statistics helps us analyze data and make sense of randomness and uncertainty
- 📊 There are two main types of data: quantitative (numbers) and qualitative (words)
- 🎲 Probability theory describes the inherent randomness in data
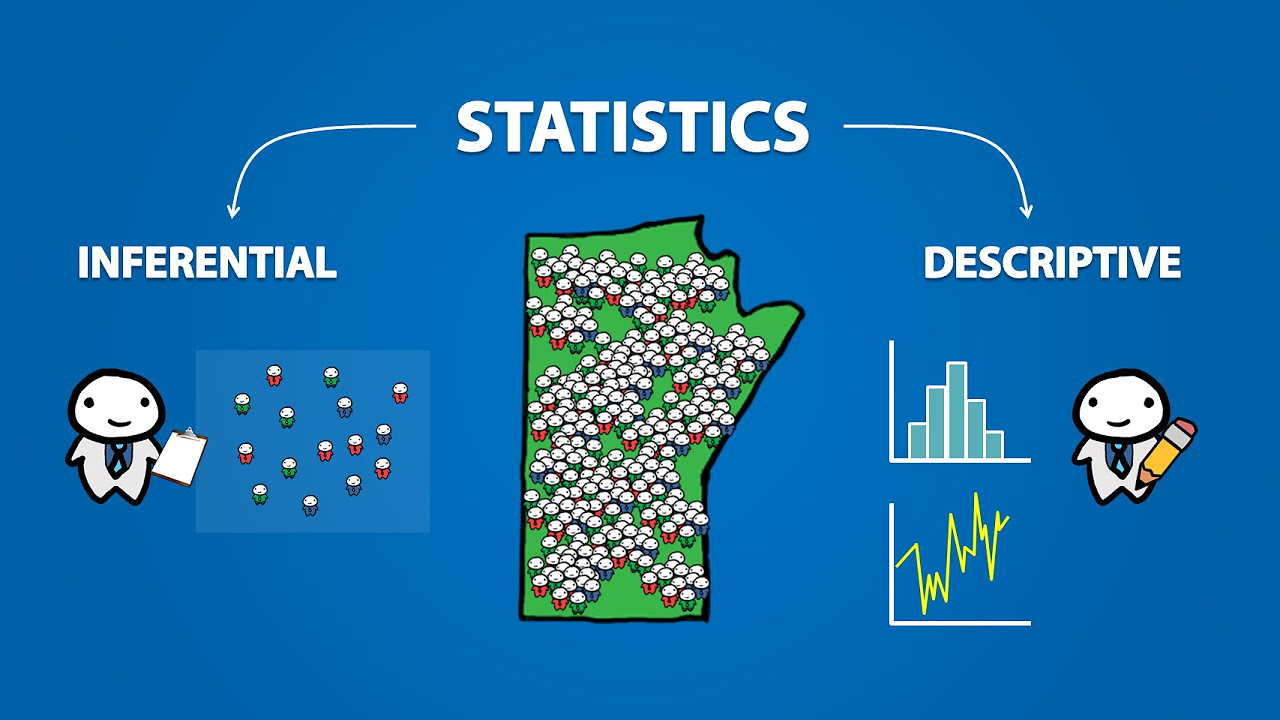
- 📈 Descriptive statistics summarize and describe the properties of data
- 🌡️ Inferential statistics allow us to make conclusions about populations from samples
- 🧪 Experiment design and data collection methods impact the conclusions we can draw
- 😯 Machine learning uses statistics to make predictions from data
- 🤯 Modern statistics tackles very complex, high-dimensional data analysis problems
- 📐 Assumptions are crucial in statistics - models can fail if assumptions are violated
- 👩💻 Statistical programming languages like R help analyze data and test models
Q & A
What is the main purpose of statistics?
-The main purpose of statistics is to make sense of data and information despite the presence of randomness. It aims to uncover patterns, relationships, and insights from data.
What are the two main types of data?
-The two main types of data are quantitative data (numerical data) and qualitative data (categorical or text data).
What is a random variable and what does its probability distribution describe?
-A random variable is a variable that can take on different values probabilistically. Its probability distribution describes the probabilities associated with each potential value.
What is the difference between descriptive and inferential statistics?
-Descriptive statistics summarize and describe the actual data collected, while inferential statistics make inferences about an unobservable larger population based on a sample of data.
What is the purpose of hypothesis testing?
-Hypothesis testing is used to make decisions about hypotheses/claims made about a population. It allows us to conclude whether we have enough evidence to reject the initial hypothesis.
What are Type I and Type II errors in hypothesis testing?
-Type I error occurs when we reject a true null hypothesis. Type II error occurs when we fail to reject a false null hypothesis.
What is the difference between observational and experimental studies?
-Experimental studies involve randomization and manipulation of conditions, allowing causality conclusions. Observational studies do not involve manipulation, only observation.
What is semi-parametric modeling?
-Semi-parametric modeling involves using both parametric components (with a finite number of parameters) and non-parametric components (without a predefined structure) in a model.
Why is programming important for statisticians?
-Programming allows statisticians to implement statistical techniques, analyze data, run simulations to test models, automate tasks, and more effectively work with data.
What advice is offered to those wanting to get started with statistics?
-The video advises learning a statistical programming language like R, running simulations to test models, and recognizing that building statistical skills requires hard work over time.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

What Is Statistics: Crash Course Statistics #1

Statistika NonParametrik : Uji Runtun (Run Test) - PART 1

Statistika Kelas 8 [Part 1] - Menganalisis Data

Understanding The Data Life Cycle with DataBrew
Introduction to Statistics (1.1)

Sample and Population in Statistics | Statistics Tutorial | MarinStatsLectures
5.0 / 5 (0 votes)