002 Hadoop Overview and History
Summary
TLDRIn this informative session, Frank Kane introduces the Hadoop ecosystem, an open-source platform designed for distributed storage and processing of massive datasets across computer clusters. Hadoop's capabilities include fault-tolerant data storage and parallel processing, leveraging commodity hardware for scalability. Originating from Google's GFS and MapReduce concepts, Hadoop has evolved since its inception by Yahoo, with its mascot, a yellow elephant named after a toy, symbolizing the project's resilience and power in handling big data challenges.
Takeaways
- 🐘 Hadoop is an open-source software platform designed for distributed storage and processing of large datasets on a computer cluster.
- 🛠️ Hadoop is built to run on commodity hardware, which is readily available and can be rented from cloud service providers like Amazon Web Services or Google.
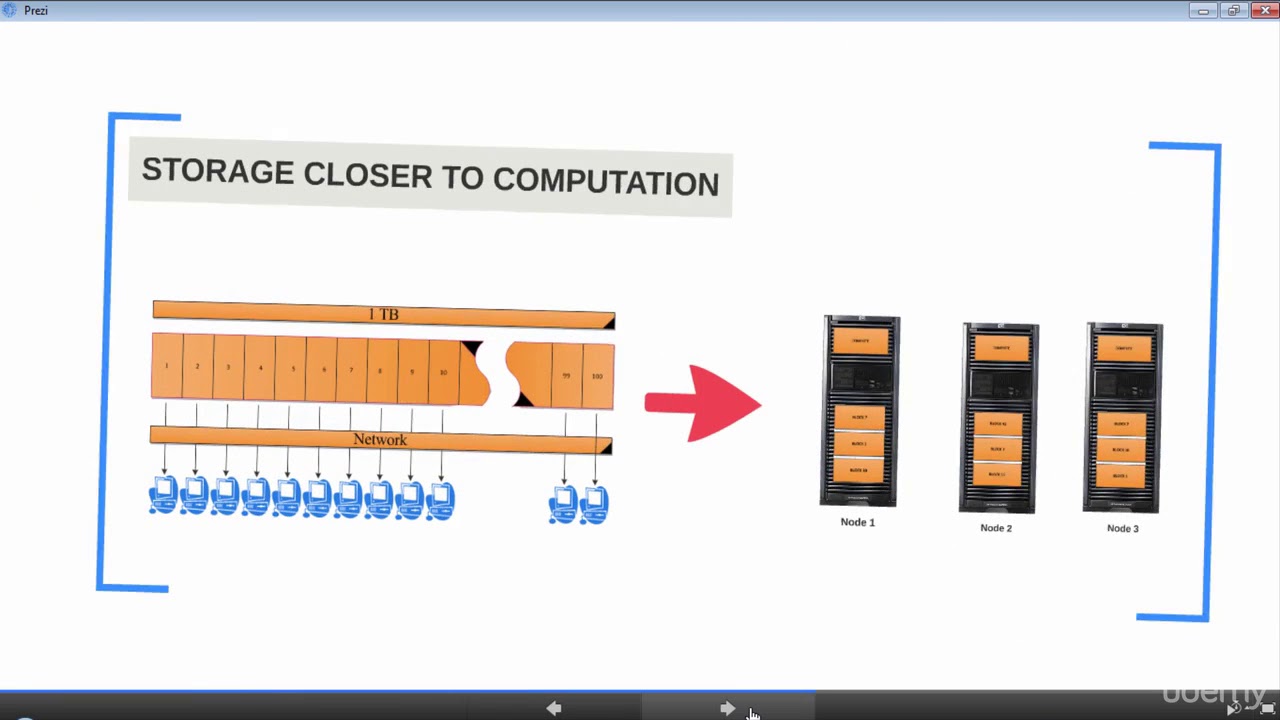
- 📚 Distributed storage in Hadoop allows for scalability by adding more computers to a cluster, and it provides a single view of the data across all hard drives.
- 🔄 Hadoop's distributed processing capability enables parallel processing of data across an entire cluster of computers, making it efficient for handling large datasets.
- 🔒 Hadoop ensures data resilience and reliability by keeping backup copies of data on different nodes in the cluster, allowing for automatic recovery in case of hardware failure.
- 📈 Hadoop was inspired by Google's papers on the Google File System (GFS) and MapReduce, which laid the foundation for Hadoop's distributed storage and processing mechanisms.
- 👶 The name 'Hadoop' comes from a stuffed yellow elephant toy of one of the creators, Doug Cutting, and the project's mascot is a yellow elephant.
- 🌐 Hadoop was originally developed by Yahoo, starting with the creation of a web search engine called Nutch, and has since evolved with contributions from various developers.
- 📈 Hadoop is suitable for handling very large datasets that cannot be managed by a single PC, providing a solution for companies dealing with massive amounts of data such as DNA information, sensor data, and web logs.
- 🔄 Hadoop's architecture supports horizontal scaling, allowing for linear increases in processing power and storage capacity by simply adding more computers to the cluster.
- 🕒 While Hadoop was initially designed for batch processing, the ecosystem has expanded to include technologies that enable interactive queries and high transaction rates for real-time applications.
Q & A
What is the definition of Hadoop according to Hortonworks?
-Hadoop is an open-source software platform for distributed storage and distributed processing of very large datasets on a computer cluster, built for commodity hardware.
What does 'open-source' mean in the context of Hadoop?
-Open-source means that Hadoop is freely available and modifiable, allowing users to access and contribute to its development.
Why is Hadoop designed to run on a cluster of computers instead of a single PC?
-Hadoop is designed to run on a cluster to leverage the combined power of multiple computers to handle and process big data more efficiently than a single PC could.
What is the significance of distributed storage in Hadoop?
-Distributed storage in Hadoop allows for the expansion of storage capacity by adding more computers to the cluster, and it ensures data redundancy and resilience by keeping backup copies of data across different nodes.
How does Hadoop handle data processing?
-Hadoop distributes the processing of data across the entire cluster of computers, allowing for parallel processing and the efficient handling of large datasets.
What is the origin of Hadoop's name and mascot?
-Hadoop is named after Doug Cutting's son's toy elephant. The project's mascot is also a yellow elephant, inspired by this stuffed toy.
What inspired the development of Hadoop's storage and processing systems?
-Hadoop's storage system was inspired by Google's published paper on the Google File System (GFS), and its processing system, MapReduce, was inspired by Google's MapReduce programming model.
Who originally developed Hadoop and why?
-Hadoop was originally developed by Yahoo, specifically by Doug Cutting and Tom White, as a part of their open-source web search engine project, after they were inspired by Google's papers on GFS and MapReduce.
Why is Hadoop's processing capability described as 'resilient'?
-Hadoop's processing capability is resilient because it can automatically recover from failures by using backup copies of data stored in different locations within the cluster.
What is the advantage of using Hadoop over traditional databases for big data?
-Hadoop offers advantages such as horizontal scaling, redundancy, fault tolerance, and the ability to process data in parallel across a cluster, which traditional databases may not efficiently handle with vertical scaling.
How has Hadoop evolved since its inception in 2006?
-Since 2006, Hadoop has evolved with continuous development and growth of its ecosystem, including the emergence of additional applications and systems built around it to support various data processing needs.
What are some of the use cases for Hadoop in handling big data?
-Hadoop can be used for handling large volumes of data such as DNA information, sensor data, web logs, trading information from the stock market, and more, where traditional systems may not scale effectively.
How does Hadoop address the issue of a single point of failure?
-Hadoop addresses the single point of failure by maintaining multiple copies of data across the cluster and automatically failing over to backup copies if the primary data becomes unavailable.
What is the significance of Hadoop's ability to handle batch processing and how has this evolved?
-Hadoop was initially designed for batch processing, suitable for tasks where immediate results are not critical. However, developments on top of Hadoop have made it capable of supporting interactive queries and high transaction rates, expanding its use cases beyond just batch processing.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video





5.0 / 5 (0 votes)