Statistical Learning: 12.3 k means Clustering
Summary
TLDRIn diesem Video wird das Thema Clustering behandelt, insbesondere K-means-Clustering. Es wird erklärt, wie Clustering-Techniken verwendet werden, um Daten in homogene Gruppen zu unterteilen, und wie K-means dabei funktioniert. Der Unterschied zwischen Clustering und Principal Component Analysis (PCA) wird ebenfalls hervorgehoben. Das Video geht auf die Bedeutung der Wahl der Clusteranzahl (K) ein und erklärt den K-means-Algorithmus, der auf der Minimierung der inneren Cluster-Variation basiert. Zudem wird das Problem von lokalen Minima im Algorithmus sowie der Nutzen mehrerer Initialisierungen zur Verbesserung der Ergebnisse angesprochen.
Takeaways
- 😀 Clustering ist eine Methode, um Daten in homogene Gruppen zu unterteilen, die ähnliche Eigenschaften teilen.
- 😀 Im Gegensatz zur Hauptkomponentenanalyse (PCA), die nach einer niedrigen Dimensionalität der Daten sucht, zielt Clustering darauf ab, Ähnlichkeiten zwischen den Beobachtungen zu erkennen.
- 😀 Ein praktisches Beispiel für Clustering ist die Segmentierung von Märkten, etwa die Einteilung von Kunden basierend auf Faktoren wie Einkommen, Beruf oder Entfernung zur nächsten Stadt.
- 😀 Zwei gängige Clustering-Methoden sind K-Means Clustering und hierarchisches Clustering. K-Means benötigt eine vorher festgelegte Anzahl an Clustern (K), während hierarchisches Clustering dies nicht tut.
- 😀 K-Means Clustering kann problematisch sein, wenn K zu groß gewählt wird, da es homogene Gruppen in kleinere, möglicherweise unpassende Cluster aufteilt.
- 😀 Der Erfolg von K-Means Clustering hängt stark von der Wahl des Werts für K ab, der in vielen Fällen eine schwierige Entscheidung ist.
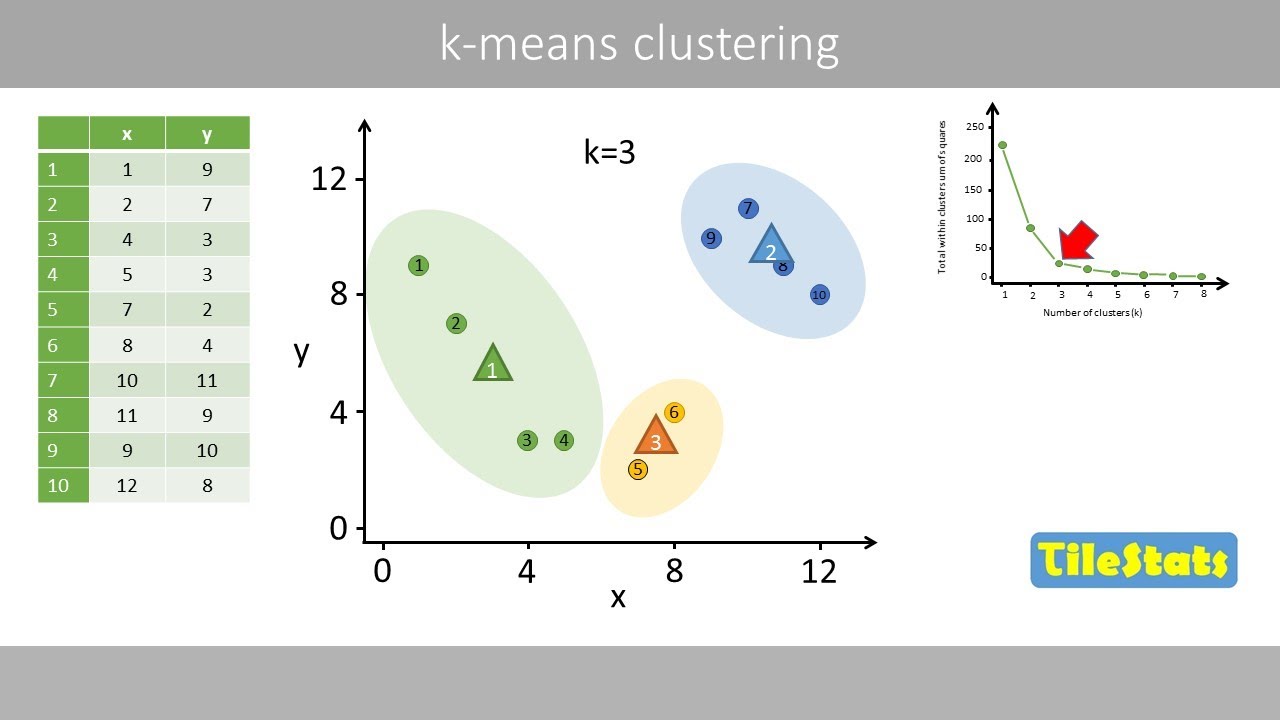
- 😀 K-Means arbeitet mit dem Konzept des 'Zentroids' – einem Mittelwert der Beobachtungen innerhalb eines Clusters, der zur Bildung neuer Cluster dient.
- 😀 Der Algorithmus von K-Means funktioniert iterativ: Zuerst werden zufällig Cluster zugewiesen, dann werden die Zentroids neu berechnet und die Datenpunkte neu zugewiesen, bis eine stabile Lösung erreicht wird.
- 😀 K-Means Clustering minimiert die 'Within-Cluster Variation' (WCV), also die Variation der Daten innerhalb eines Clusters, um die Ähnlichkeit innerhalb der Cluster zu maximieren.
- 😀 Der Algorithmus von K-Means garantiert ein lokales Minimum, jedoch nicht das globale Minimum, was bedeutet, dass er in ein lokales Tal der Funktion konvergieren kann, aber nicht unbedingt das niedrigste Tal findet.
Q & A
Was ist der Unterschied zwischen PCA (Hauptkomponentenanalyse) und Clustering?
-PCA sucht nach einer niedrigdimensionalen Darstellung der Daten, die einen Großteil der Varianz erklärt, während Clustering versucht, Beobachtungen in homogene Gruppen zu unterteilen, basierend auf der Ähnlichkeit der Datenpunkte.
Wie funktioniert das K-means Clustering?
-K-means Clustering funktioniert durch die wiederholte Zuweisung von Beobachtungen zu Clustern, Berechnung der Zentroiden für jedes Cluster und die erneute Zuweisung der Beobachtungen zu den nächstgelegenen Zentroiden. Dieser Prozess wird wiederholt, bis die Zuweisungen stabil sind.
Warum ist die Wahl von K im K-means Clustering wichtig?
-Die Wahl von K ist wichtig, weil sie bestimmt, in wie viele Gruppen die Daten unterteilt werden. Wenn K zu groß gewählt wird, kann dies dazu führen, dass Gruppen, die eigentlich homogen sind, unnötig aufgeteilt werden.
Was passiert, wenn man K in K-means zu hoch wählt?
-Wenn K zu hoch gewählt wird, kann der Algorithmus Gruppen in homogenen Bereichen der Daten aufteilen, was zu einer ungenauen Segmentierung führt, obwohl die tatsächliche Verteilung der Daten keine so viele Cluster erfordert.
Was versteht man unter 'innerer Clustervariation' (WCV) im Kontext von K-means?
-Die innere Clustervariation (WCV) misst die Streuung der Punkte innerhalb eines Clusters. Ein gutes Clustering minimiert diese Variation, indem es die Punkte in einem Cluster so dicht wie möglich um den Zentroiden gruppiert.
Wie wird die innere Clustervariation (WCV) berechnet?
-Die WCV wird berechnet, indem die quadratischen Abstände zwischen allen Paaren von Beobachtungen innerhalb eines Clusters summiert werden. Dabei wird die gesamte Variation innerhalb des Clusters erfasst.
Warum ist das K-means Clustering als 'alternierender Algorithmus' bezeichnet?
-K-means ist ein alternierender Algorithmus, weil er abwechselnd zwei Schritte ausführt: Zuerst werden die Datenpunkte den Clustern zugewiesen, und dann werden die Zentroiden neu berechnet, basierend auf den aktuellen Zuweisungen.
Was bedeutet es, dass K-means in einem lokalen Minimum endet?
-Das bedeutet, dass der Algorithmus eine Lösung erreicht, bei der der Optimierungsprozess gestoppt wird, aber diese Lösung nicht unbedingt die beste Lösung (globale Minimum) für das Problem darstellt.
Warum sollte man K-means mehrere Male mit unterschiedlichen Startpunkten ausführen?
-Da K-means nicht garantiert, das globale Minimum zu finden, kann es in ein lokales Minimum stecken bleiben. Mehrere Ausführungen mit verschiedenen Startpunkten helfen dabei, die beste Lösung zu finden.
Wie hilft das K-means Clustering bei der Marktsegmentierung?
-K-means kann verwendet werden, um Kunden in Segmente mit ähnlichen Merkmalen (z.B. Einkommen, Beruf, Entfernung zur Stadt) zu gruppieren. Diese Segmente können dann gezielt mit unterschiedlichen Werbemaßnahmen angesprochen werden, was die Marketingeffektivität erhöht.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade Now




5.0 / 5 (0 votes)
