【生成式AI】ChatGPT 可以自我反省!
Summary
TLDR本视频讨论了大型语言模型如ChatGPT的自我反省能力,通过具体例子展示了模型如何检查自身错误并进行修正。介绍了不同的技术如Constitutional AI、Dara和React,这些技术通过自我批判、相互讨论和反思行为,提高了模型的准确性和道德决策能力。视频强调了未来可能不再需要人工干预,而是通过大型语言模型自我帮助来提升性能。
Takeaways
- 🤖 ChatGPT有时会犯错,例如错误地介绍不存在的活动,如台大玫瑰花节。
- 🔍 可以通过要求ChatGPT检查自己输出的信息是否正确来促使其自我反省。
- 🌹 ChatGPT在被要求自我检查后,能够承认并更正错误信息,如台大玫瑰花节的错误。
- 📊 ChatGPT在解决问题时可能会犯逻辑错误,例如解方程式时出现计算失误。
- 🧠 即使ChatGPT未能立即发现错误,通过具体提示,它能够识别并修正错误。
- 📈 随着版本的更新,如从GPT3.5到GPT4,ChatGPT的自我反省能力有所增强。
- 🔗 反省能力的提升有助于构建更安全、更符合道德标准的AI,如Constitutional AI的概念。
- 🤔 通过自我批判和修改,语言模型可以在不需要额外人力的情况下提高答案质量。
- 💡 让两个语言模型相互讨论和批判可以进一步提高输出质量,如Dara论文中的方法。
- 🌟 通过在模型中加入思考(React)和反思(Reflection)的能力,可以显著提升解决问题的效率。
- 🔄 通过在上下文中学习(In-Context Learning),模型可以学习如何撰写检讨报告并应用于未来的任务中。
Q & A
如何让ChatGPT进行自我反省?
-可以通过直接要求ChatGPT检查自己输出的信息是否正确来促使其进行自我反省。例如,询问ChatGPT提供的信息后,再要求其确认信息的准确性。
ChatGPT在提供错误信息时会如何反应?
-ChatGPT在发现提供的信息与实际情况不相符时,会承认错误并尝试更正。例如,如果ChatGPT错误地介绍了不存在的台大玫瑰花节,它会在被要求检查信息后承认错误并提供正确的花卉节信息。
ChatGPT在解决数学问题时会出现哪些错误?
-ChatGPT在解决数学问题时可能会列出错误的方程式或者在解方程时犯错误,导致最终答案不正确。例如,在解决鸡兔同笼问题时,可能会因为方程式设置错误而得到错误的结果。
如何帮助ChatGPT更准确地解决问题?
-可以通过提供更详细的提示和指导来帮助ChatGPT更准确地解决问题。例如,在解决数学问题时,可以要求ChatGPT详细说明解题步骤,或者指出其解题过程中的具体错误。
什么是Constitutional AI?
-Constitutional AI是一种旨在创建不会说出伤人或有害句子的语言模型的目标。它通过在模型生成答案之前加入自我反省的步骤,确保生成的内容符合道德和社会规范。
Dara论文中提出的模型互相讨论的方法是什么?
-Dara论文中提出的方法是通过一个语言模型来检查另一个语言模型的输出,以此来提高答案的质量。其中一个模型负责生成答案,另一个模型负责挑出错误并提出改进意见。
React技术是如何帮助语言模型提高问题解决能力的?
-React技术通过结合reasoning(推理)和acting(行动),让语言模型在执行任务前进行思考,然后采取行动,并根据行动结果再次思考,以此循环来提高解决问题的准确性。
Reflection技术是如何影响语言模型的行为的?
-Reflection技术通过让语言模型在失败的任务后编写一份反思报告,然后在执行相同任务时参考这份报告来改变行为,从而提高任务完成的成功率。
为什么说大型语言模型的自我反省能力越来越像人类?
-大型语言模型的自我反省能力越来越像人类,因为它们不仅能够生成答案,还能够在事后检查并发现自身的错误,甚至根据以往的经验来改进未来的输出,这与人在解题时的行为模式相似。
在演算法中,NP问题是什么?
-NP问题是非确定性多项式时间问题,指的是那些可能没有多项式时间算法可以解决的问题,但它们的解可以在多项式时间内被验证。
如何理解ChatGPT的反省能力与人类解题时的反思行为的相似性?
-ChatGPT的反省能力与人类解题时的反思行为相似,因为都是在生成答案后进行再次检查和评估,以发现并纠正错误。这种能力使得ChatGPT在解决问题时更加准确,类似于人类在解题后回头检查答案的过程。
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
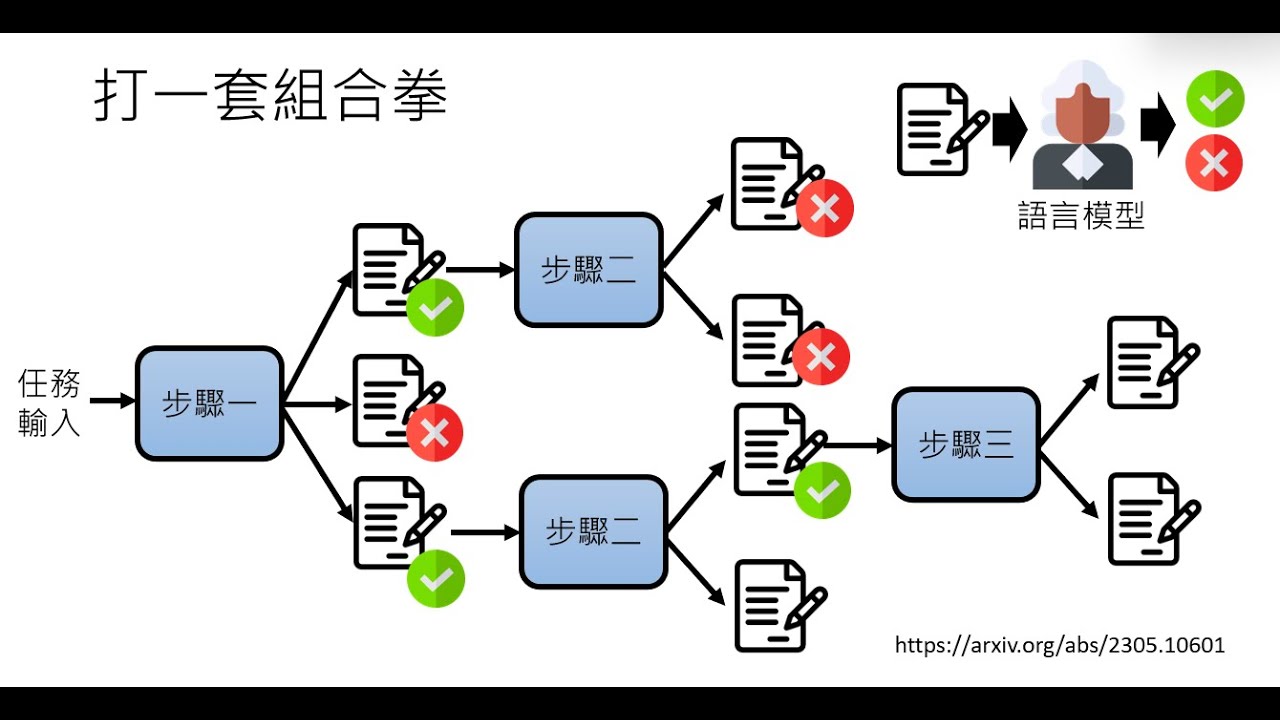
【生成式AI導論 2024】第4講:訓練不了人工智慧?你可以訓練你自己 (中) — 拆解問題與使用工具

Trying to make LLMs less stubborn in RAG (DSPy optimizer tested with knowledge graphs)

第2集-指南-ChatGPT提示工程师|AI大神吴恩达教你写提示词

How Did Dario & Ilya Know LLMs Could Lead to AGI?
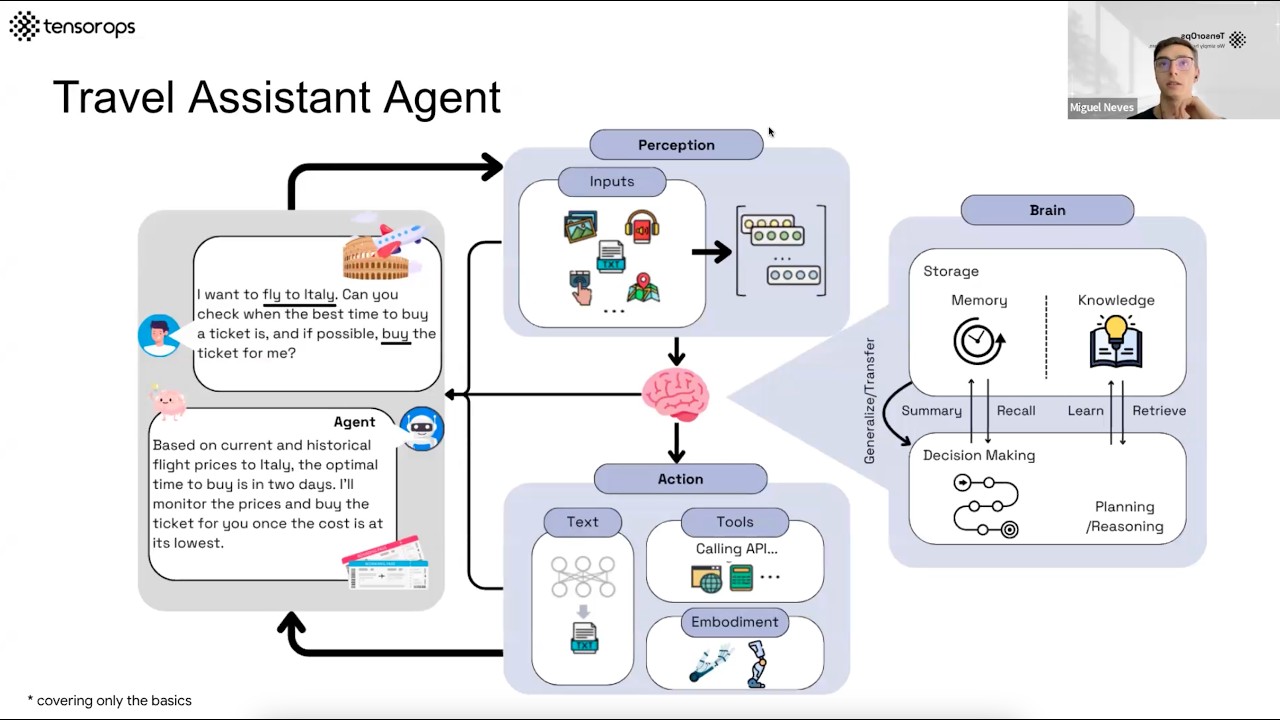
AI Agents– Simple Overview of Brain, Tools, Reasoning and Planning

Stream of Search (SoS): Learning to Search in Language
5.0 / 5 (0 votes)
