How to chat with your PDFs using local Large Language Models [Ollama RAG]
Summary
TLDRIn this tutorial, viewers learn how to create a local retrieval-augmented generation (RAG) system for processing sensitive documents like PDFs. The presenter guides users through ingesting files, creating vector embeddings, and storing them in a vector database, enabling effective querying without internet access. By utilizing tools like LongChain and Chroma DB, the tutorial emphasizes secure and interactive document handling. Future plans include developing a user-friendly Streamlit app to simplify the process for non-coders, alongside exploring advanced techniques such as agents for improved functionality.
Takeaways
- 😀 The speaker explains the purpose of the video, which is to showcase document processing using LangChain and Vector databases.
- 📄 The Global Corporation Barometer 2024 report analyzes the state of global corporations across five key pillars.
- 🌍 The five pillars of global cooperation identified in the report are trade, capital, innovation technology, climate and natural capital, health and wellness, and peace and security.
- ⚙️ The initial attempt to run the program faced technical issues, highlighting the need for sufficient computational resources, ideally a GPU.
- 💡 The speaker successfully queried the Vector database, obtaining a coherent summary of the report's content.
- 🔄 Various tools can be used interchangeably for document processing, including LangChain and Llama Index, although users can opt for direct coding as well.
- 🔍 The concept of agents in document processing is introduced, with the speaker expressing interest in exploring this topic further.
- 🛠️ Future plans include developing a Streamlit app to create a more user-friendly interface for interacting with uploaded PDFs.
- 📊 The speaker emphasizes the importance of customization in developing applications, suggesting it can enhance user experience.
- 🤝 Audience engagement is encouraged, with the speaker inviting feedback and suggestions for future video topics.
Q & A
What is the primary focus of the global corporation barometer 2024 report?
-The report provides an analysis of the state of global corporations across five key pillars: trade, capital, innovation, technology, climate, natural capital, health and wellness, and peace and security.
How did the speaker describe their experience running the code for the analysis?
-The speaker mentioned that running the code consumed a lot of resources, leading to issues where the video broke and could not be saved. They learned that having a GPU would enhance performance, but they managed to run it on their system without one.
What are the five pillars of global cooperation as outlined in the report?
-The five pillars are trade, capital, innovation technology, climate and natural capital, health and wellness, and peace and security.
Why does the speaker believe their approach to summarizing the document is effective?
-The speaker found that by asking variations of questions about the document, they could generate a comprehensive summary that captured the essence of the report.
What does the speaker plan to do next with the analysis code?
-The speaker intends to convert the analysis into a user-friendly Streamlit app, allowing users to upload PDF files and interact with the content without needing to understand the underlying code.
What challenges did the speaker face when working with the document?
-The speaker faced challenges related to resource consumption, which affected the performance of the code and caused issues with saving their work.
How does the speaker suggest making the analysis accessible to non-coders?
-By developing a Streamlit app, the speaker aims to provide an interface that simplifies interaction with the analysis, making it accessible for users without coding knowledge.
What potential does the speaker see in using agents within the analysis?
-The speaker is interested in the idea of assigning agents to documents, which could allow for more tailored queries and responses when interacting with the content.
Why did the speaker choose to work offline for the document analysis?
-The speaker highlighted that the analysis can be performed offline, as long as all necessary imports are completed, allowing for more flexibility in their workflow.
What does the speaker hope to achieve by sharing their coding process?
-The speaker aims to educate viewers and encourage them to explore similar projects, inviting feedback on what topics they'd like to see covered in future videos.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示
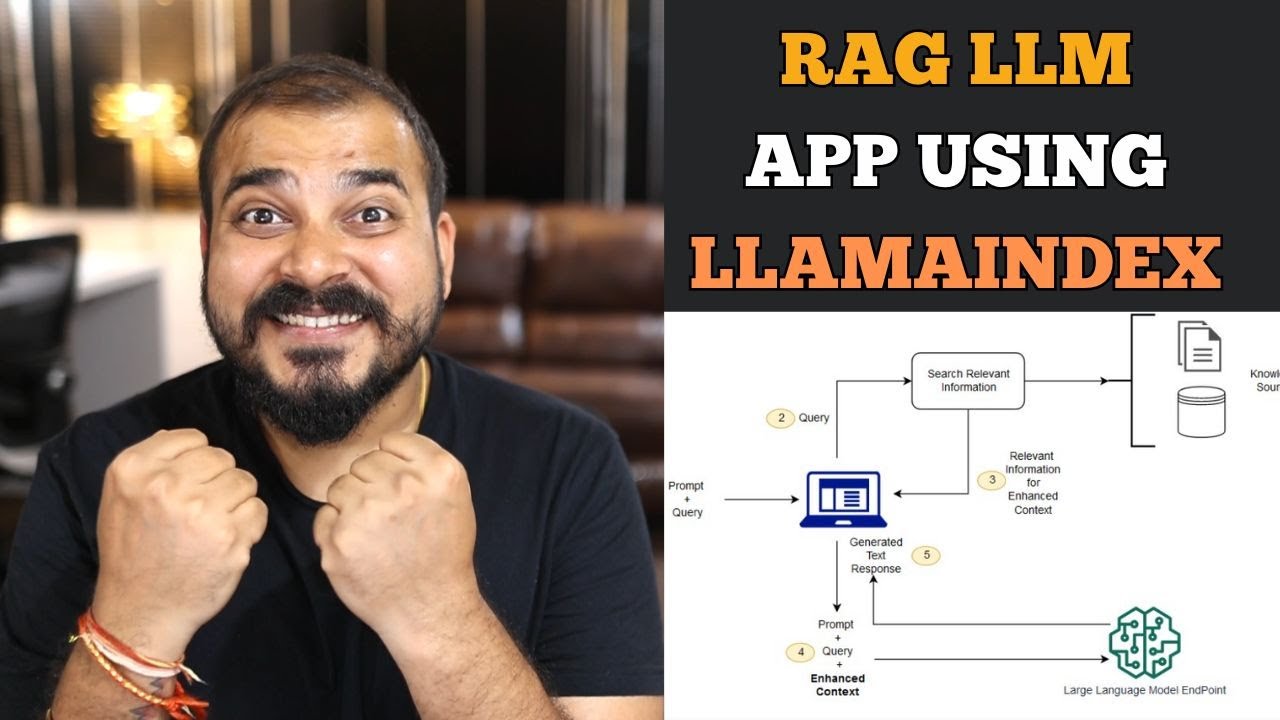
End to end RAG LLM App Using Llamaindex and OpenAI- Indexing and Querying Multiple pdf's
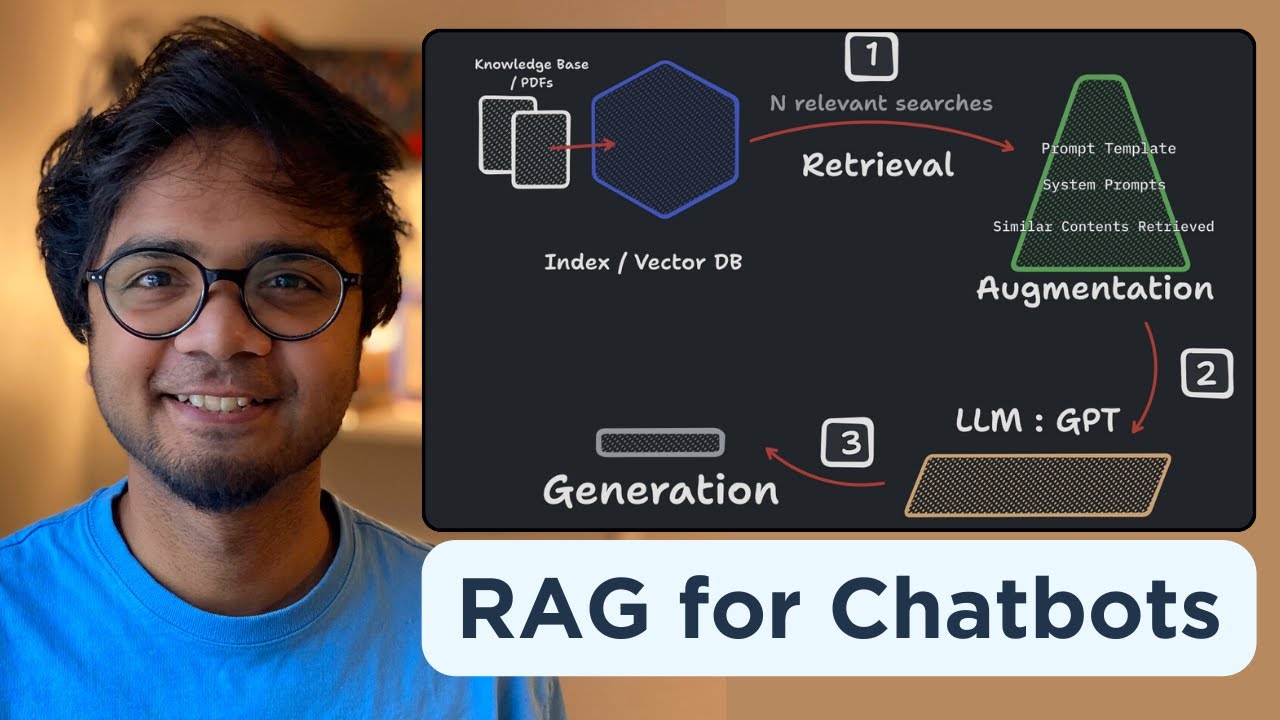
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Step-by-Step Guide to Building a RAG LLM App with LLamA2 and LLaMAindex

Build Smarter PDF Assistants: Advanced RAG Techniques using Deepseek & LangChain

Agentic RAG: Make Chatting with Docs Smarter

Unstructured” Open-Source ETL for LLMs
5.0 / 5 (0 votes)
