But what is a GPT? Visual intro to Transformers | Deep learning, chapter 5
Summary
TLDREl guion del video ofrece una explicación visual de cómo funciona una Generative Pretrained Transformer (GPT), una red neuronal clave en el avance de la inteligencia artificial. Se discute el proceso de 'pre-entrenamiento' en gran cantidad de datos y la capacidad de afinación en tareas específicas. El modelo de transformer, introducido por Google en 2017, está diseñado para traducir texto y generar nuevas secuencias de texto a partir de un snippet inicial. El video explora cómo se desglosa la entrada en 'tokens', se convierten en vectores y se procesan a través de bloques de atención y percepciones multicapas antes de generar una distribución de probabilidad para el token siguiente. Además, se menciona el uso de la función Softmax para normalizar valores en una distribución de probabilidad y cómo la 'temperatura' afecta la creatividad del texto generado. El guion prepara al espectador para comprender el mecanismo de atención, una pieza central en el éxito de los modelos de lenguaje modernos.
Takeaways
- 🧠 GPT significa Generative Pretrained Transformer, un modelo de bot que genera nuevo texto a través de aprendizaje masivo y ajuste fino en tareas específicas.
- 🤖 'Pretrained' se refiere a que el modelo aprendió de una gran cantidad de datos y puede ser afinado con más entrenamiento para tareas específicas.
- 🔑 La palabra 'Transformer' hace referencia a un tipo específico de red neuronal, el núcleo de la inteligencia artificial moderna.
- 🎨 Los transformers pueden utilizarse para construir diferentes modelos, desde audio a transcripciones, de texto a discurso sintético, e inclusive generación de imágenes a partir de descripciones textuales.
- 🌐 El modelo original de 'transformer' fue creado por Google en 2017 con el objetivo específico de traducir texto de un idioma a otro.
- 📚 El modelo de ChatGPT se entrena para tomar un trozo de texto y predecir lo que sigue, tomando la forma de una distribución de probabilidad sobre posibles siguientes trozos de texto.
- 🛠️ La predicción y muestreo repetidos es el proceso básico que ocurre cuando interactuamos con modelos de lenguaje grandes como ChatGPT.
- 🔍 La entrada de datos en un transformador se descompone en 'tokens', que pueden ser palabras, partes de palabras o combinaciones de caracteres comunes.
- 🔄 Los tokens se asocian con vectores que codifican su significado, y estos vectores pasan por bloques de atención y operaciones de perceptrón multicapa para actualizar su información.
- 📉 La función Softmax se utiliza para convertir una lista de números en una distribución de probabilidad válida, asegurando que los valores sean positivos y sumen 1.
- 🌡️ El 'temperature' en la función de distribución de probabilidad afecta la originalidad y la coherencia del texto generado; un valor más alto permite más variedad, mientras que un valor más bajo refuerza las palabras más probables.
Q & A
¿Qué significa la abreviatura GPT y qué representa cada palabra?
-GPT significa Generative Pretrained Transformer. 'Generative' se refiere a la capacidad de los bots para generar nuevo texto. 'Pretrained' indica que el modelo ha aprendido de una gran cantidad de datos y está preparado para ser ajustado o afinado en tareas específicas. 'Transformer' es un tipo específico de red neuronal que es la base de la revolución actual en Inteligencia Artificial.
¿Qué es un modelo transformer y cómo es clave en el avance de la IA?
-Un modelo transformer es una red neuronal de aprendizaje profundo que permite a los modelos procesar y generar texto, así como realizar otras tareas de lenguaje natural. Es fundamental en el avance de la IA porque permite a los modelos procesar grandes cantidades de datos y realizar tareas complejas de manera más eficiente y efectiva.
¿Cómo se relaciona un modelo transformer con la generación de texto o la traducción de idiomas?
-Un modelo transformer se entrena para tomar un fragmento de texto y predecir cuál sería el siguiente fragmento en la secuencia. Esta capacidad de predicción se puede utilizar para generar texto nuevo o para traducir texto de un idioma a otro, ya que el modelo puede aprender patrones y contextos lingüísticos a gran escala.
¿Qué es la función de los tokens en un modelo de transformer?
-Los tokens son piezas pequeñas en las que se divide la entrada. En el caso del texto, estos pueden ser palabras, partes de palabras o combinaciones de caracteres comunes. Estos tokens se asocian con vectores que codifican su significado, permitiendo que el modelo procese y comprenda el lenguaje.
¿Qué es un bloque de atención y cómo funciona dentro de un modelo transformer?
-Un bloque de atención es una operación en un modelo transformer que permite que los vectores se comuniquen entre sí y actualicen sus valores en función de la relevancia contextual. Esto ayuda al modelo a entender cómo las palabras en el contexto afectan el significado de otras palabras.
¿Qué es una multi-layer perceptron y cómo se relaciona con un modelo transformer?
-Una multi-layer perceptron, o capa de avance, es una operación en un modelo transformer donde los vectores no se comunican entre sí, sino que todos pasan por la misma operación en paralelo. Ayuda a interpretar y actualizar los vectores basándose en una serie de preguntas y respuestas.
¿Cómo se relaciona el concepto de 'embedding' con la representación de palabras en un modelo de transformer?
-El 'embedding' es el proceso de convertir palabras en vectores en un espacio de alta dimensión. Los vectores resultantes, conocidos como embeddings, tienen la capacidad de capturar el significado de las palabras y su contexto, lo que es fundamental para la predicción y generación de texto.
¿Qué es la función Softmax y cómo se utiliza en un modelo transformer?
-La función Softmax se utiliza para convertir una lista de números en una distribución de probabilidad válida. Es fundamental en modelos transformers para normalizar los valores de salida, asegurando que cada valor esté entre 0 y 1 y que la suma de todos ellos sea 1.
¿Cómo se relaciona el tamaño del modelo GPT-3 con su capacidad para generar texto?
-GPT-3 tiene 175 mil millones de parámetros, lo que le permite tener una gran capacidad de generación de texto. Cuanto más grande es el modelo, más datos puede procesar y más complejas son las relaciones y contextos que puede aprender, lo que resulta en una generación de texto más coherente y variada.
¿Qué es la matriz de 'Unembedding' y cómo se utiliza en la predicción del siguiente token?
-La matriz de 'Unembedding' es otra matriz utilizada en un modelo transformer para mapear el último vector del contexto a una lista de valores para cada token en el vocabulario. Es similar a la matriz de embedding, pero con el orden inverso y es utilizada para realizar la predicción del siguiente token en la secuencia.
¿Cómo se utiliza la temperatura en la función de distribución de probabilidad para influir en la generación de texto?
-La temperatura es un parámetro en la función de distribución de probabilidad que controla la variabilidad de las elecciones de palabras. Un valor alto de temperatura hace que la distribución sea más uniforme, permitiendo la elección de palabras menos probables, mientras que un valor bajo hace que las palabras más probables dominen la elección.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados
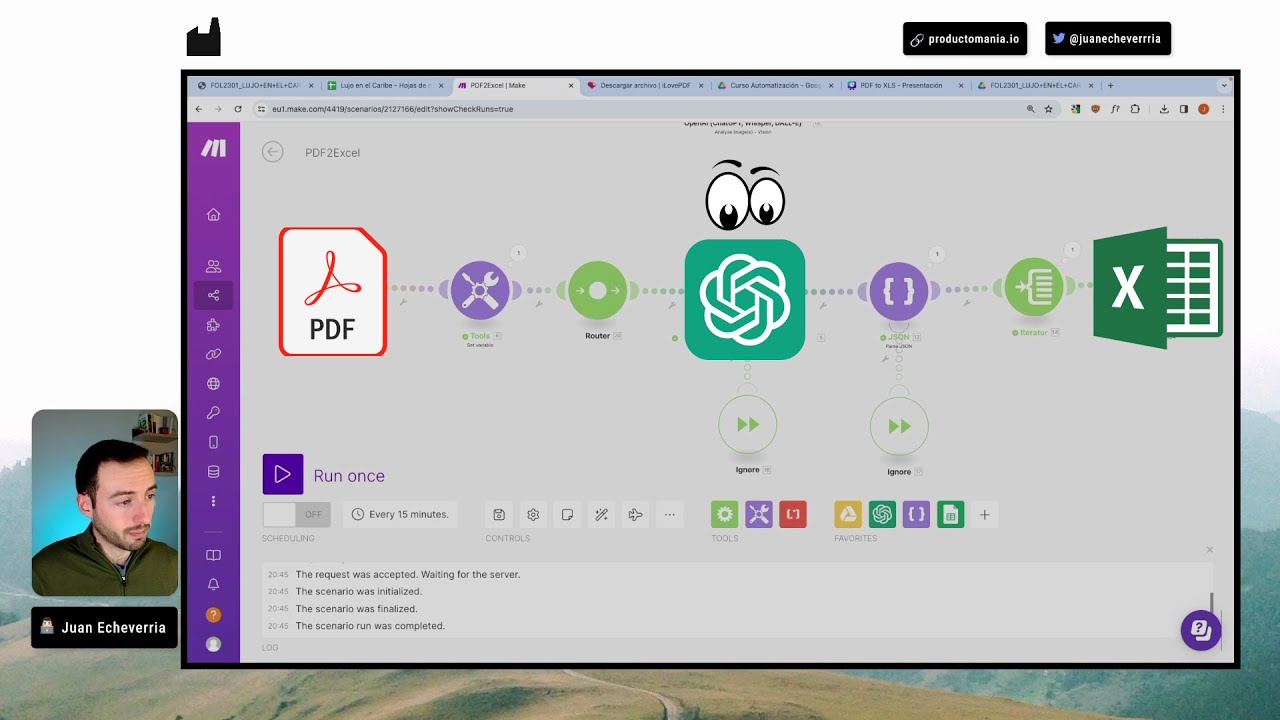
Cómo utilizar GPT4-VISION para EXTRAER INFORMACIÓN de un PDF

¿Qué es una Red Neuronal? ¿Cómo funcionan?

Todo LO QUE HA PASADO en el mundo de la IA GENERATIVA desde ChatGPT

Pytorch en 2 minutos

La EVOLUCIÓN de la Inteligencia Artificial 🤖 El Desarrollo de la IA en la HISTORIA🧩

Cómo funcionan las redes neuronales - Inteligencia Artificial

Así funciona la RADIO
5.0 / 5 (0 votes)