Deep Learning: In a Nutshell
Summary
TLDRThis script delves into the relationship between deep learning and machine learning, highlighting that deep learning is a subset of the latter. It explains the fundamental concepts of machine learning, such as algorithms, loss functions, and the importance of gradient descent for optimization. The script further clarifies the role of activation functions in introducing non-linearity to neural networks, enabling them to handle complex data. The video concludes by emphasizing the distinct capabilities of machine learning and deep learning, with the latter's versatility in tasks like image classification and natural language processing.
Takeaways
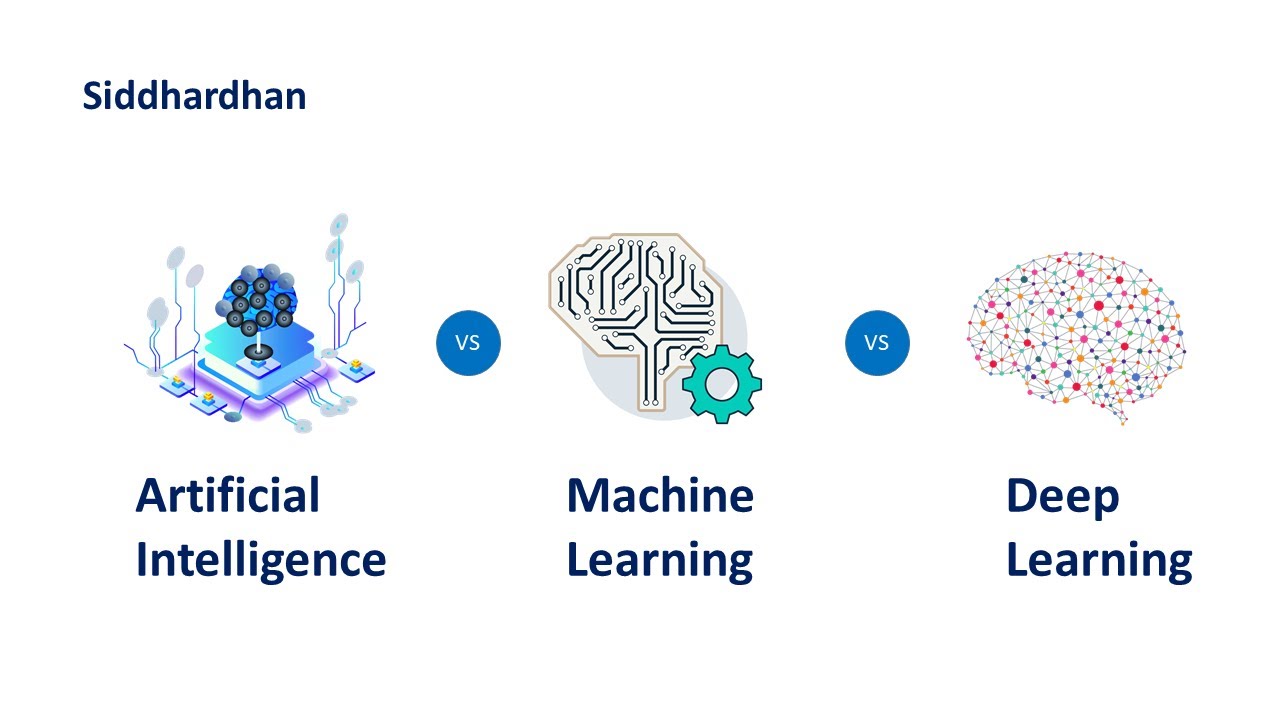
- 🧠 Deep learning is a subset of machine learning, derived from its principles.
- 🔢 Machine learning algorithms use a loss function to measure prediction error and optimize it for higher accuracy.
- 📉 The mean squared error is a common loss function used in linear regression to calculate the difference between predictions and actual values.
- 🔍 Gradient descent is a key optimization technique in machine learning, used to minimize the loss function by iteratively adjusting parameters.
- 🔧 Deep learning often employs advanced variants of gradient descent, such as Adam, for optimization.
- 🔄 The initialization of parameters in machine learning models is crucial as it can affect the convergence to global or local minima.
- 🌟 Keras provides various initializers to help find efficient starting points for model parameters.
- 💡 Activation functions introduce non-linearity into neural networks, allowing them to model complex patterns in data.
- 📊 Sigmoid is an example of an activation function that maps inputs to a range between 0 and 1, useful for logistic regression.
- 🔗 Deep learning builds upon fundamental machine learning concepts, such as neurons and activation functions, to create complex models.
- 🚀 Deep learning's flexibility with activation functions, initializers, regularizers, and optimizers allows it to tackle more complex tasks than traditional machine learning.
Q & A
What is the relationship between deep learning and machine learning?
-Deep learning is a subset of machine learning, meaning it is derived from the principles of machine learning and focuses on neural networks with many layers.
What is the fundamental role of an algorithm in machine learning?
-The fundamental role of an algorithm in machine learning is to take input 'X', make predictions, and, in the case of supervised learning, compare these predictions with actual output 'y' to measure accuracy and optimize itself to reduce errors.
How does a loss function contribute to the optimization of a machine learning model?
-A loss function measures the error made by the algorithm. It informs the model how far off its predictions are from the actual values, and the optimizer uses this information to adjust the model parameters and minimize the loss.
What is the mean squared error, and how is it used in linear regression?
-The mean squared error is a loss function used in linear regression that calculates the average of the squares of the differences between the predicted and actual values. It is used to quantify the error and guide the optimization process.
How does gradient descent work in optimizing the loss function?
-Gradient descent is an optimization algorithm that iteratively moves in the direction of the steepest descent as defined by the negative of the gradient to minimize the loss function.
What is the significance of the starting point in gradient descent?
-The starting point in gradient descent is significant because it can lead to different local or global minima. A poor starting point may cause the algorithm to get stuck in a local minimum, while a good starting point can help find the global minimum more efficiently.
What are some advanced optimizers used in deep learning apart from gradient descent?
-Advanced optimizers used in deep learning include successors of gradient descent, such as Adam, which can provide more efficient ways to minimize the loss function compared to traditional gradient descent.
How does a neural network's structure relate to the fundamental concepts of machine learning?
-A neural network's structure is built upon the fundamental concepts of machine learning, such as neurons performing calculations similar to linear regression, with the addition of non-linearity introduced by activation functions.
What is the purpose of an activation function in a neural network?
-The purpose of an activation function in a neural network is to introduce non-linearity to the model, allowing it to learn and fit more complex patterns in the data.
What is the difference between epochs and max_iter in the context of machine learning and deep learning?
-Epochs and max_iter both refer to the number of iterations or passes through the entire dataset during training. In machine learning, it is often referred to as max_iter, while in deep learning, it is called epochs.
Why is machine learning not considered equal to deep learning, despite their similarities?
-Machine learning is not equal to deep learning because while machine learning can handle tabular data, deep learning is designed to handle more complex tasks such as image classification, natural language processing, and other tasks that require understanding intricate patterns in large datasets.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade Now



5.0 / 5 (0 votes)