R Squared or Coefficient of Determination | Statistics Tutorial | MarinStatsLectures
Summary
TLDRThis video provides an insightful overview of R-squared, the coefficient of determination, highlighting its role in measuring how well a regression model fits observed data. It explains how R-squared is derived from Pearson's correlation coefficient and outlines its calculation through the total sum of squares, distinguishing between explained and unexplained variability. The concept of adjusted R-squared is introduced to account for additional predictors in multiple regression. Lastly, the video addresses the limitations of R-squared, emphasizing the need for validation methods like cross-validation to accurately assess model performance.
Takeaways
- 😀 R-squared (coefficient of determination) measures how well a regression model fits observed data.
- 📊 It is calculated as the square of Pearson's correlation coefficient (r).
- 📈 An R-squared value closer to 1 indicates a better fit for the model.
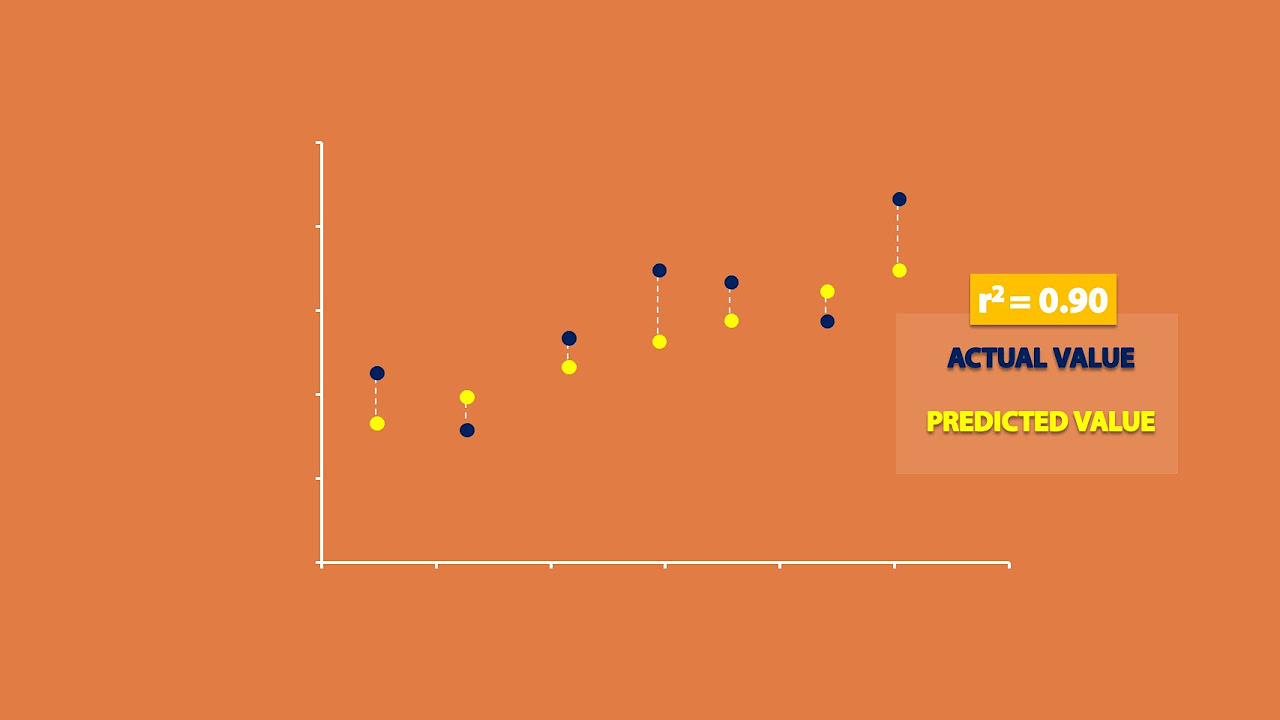
- 💡 R-squared explains the percentage of variability in the dependent variable (Y) that is explained by the independent variable (X).
- 📉 The total variability in Y can be broken down into 'explained' and 'unexplained' variability.
- 🔍 The total sum of squares (SST) measures overall variability, while sum of squares explained (SSR) and sum of squares unexplained (SSE) represent the contributions of the model.
- 📏 The relationship between these sums is expressed as SST = SSR + SSE.
- 🎯 Adjusted R-squared accounts for the number of predictors in a model, providing a more accurate measure of fit in multiple regression scenarios.
- ⚠️ R-squared is limited because it measures the model's ability to predict the data used to fit it, not new data.
- 🔄 Validation techniques like cross-validation help assess a model's predictive power on unseen data.
Q & A
What is R-squared, and what does it measure?
-R-squared, also known as the coefficient of determination, measures how well a regression model fits observed data. It indicates the percentage of variability in the dependent variable that is explained by the independent variable(s).
How is R-squared calculated in the context of simple linear regression?
-In simple linear regression, R-squared is calculated as the square of Pearson's correlation coefficient between the observed values and the predicted values of the dependent variable.
What does an R-squared value of 0.61 signify?
-An R-squared value of 0.61 means that approximately 61% of the variability in the dependent variable (e.g., head circumference) can be explained by the independent variable (e.g., gestational age).
What is the range of values that R-squared can take?
-R-squared values range from 0 to 1, where values closer to 1 indicate a better fit of the model to the observed data.
How does the concept of total sum of squares relate to R-squared?
-The total sum of squares represents the total variability in the dependent variable. R-squared is calculated as the ratio of the explained sum of squares (variability explained by the model) to the total sum of squares.
What are the components of the total variability in the context of regression?
-Total variability can be divided into two components: the variability explained by the regression model (sum of squares explained) and the unexplained variability (sum of squares error).
What is adjusted R-squared, and why is it important?
-Adjusted R-squared modifies the R-squared value by adding a penalty for the number of independent variables in the model. It is particularly important in multiple linear regression to avoid overfitting.
What is the limitation of using R-squared as a measure of model fit?
-One limitation of R-squared is that it uses the same data to build the model and to calculate the R-squared value, which can create a circular reasoning effect. It may not accurately reflect how well the model performs on unseen data.
What is a common alternative approach to validate a regression model?
-Cross-validation is a common alternative approach. It involves splitting the dataset into training and testing sets to assess how well the model performs on data it hasn't seen before.
How can adding irrelevant variables affect R-squared?
-Adding irrelevant variables to the model can artificially inflate R-squared values, as even random data can show some correlation with the dependent variable in a sample.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

METODE NUMERIK 11 REGRESI LINIER

Uji Regresi Linier Sederhana Dengan SPSS | Pembahasan Lengkap!

APA ITU KOEFISIEN DETERMINASI (r²) ? | CONTOH DAN PEMBAHASAN PADA OUTPUT SPSS #StudyWithTika
Regression and R-Squared (2.2)
Tutorial Uji Asumsi Klasik (Prasyarat) Beserta Uji Regresi Berganda Dengan SPSS

Teori Regresi Linier Sederhana (Part 2) - Statistika Parametrik
5.0 / 5 (0 votes)