Pooling and Padding in Convolutional Neural Networks and Deep Learning
Summary
TLDRThis tutorial video dives into the intricacies of pooling in convolutional neural networks (CNNs), a crucial component for feature extraction and dimensionality reduction. It explains the concept of pooling, focusing on max pooling and average pooling, and their respective roles in identifying the most significant features within an image. The video also covers the use of padding to maintain image dimensions during the pooling process, which is essential for preserving detail for further feature extraction in deeper layers of the CNN. Practical examples using TensorFlow and Keras illustrate how to implement max pooling with and without padding, and how to adjust stride parameters to control the dimensionality of the output. The presenter emphasizes the importance of understanding pooling and padding for optimizing neural network performance and efficiency, especially when dealing with complex applications.
Takeaways
- 📚 The video provides an introduction to pooling in convolutional neural networks (CNNs), focusing on max pooling and its application after convolutional layers.
- 🌟 Max pooling is used to extract the most important features from a given region in the image, typically by selecting the maximum value within a defined area, such as 2x2 or 3x3.
- 🔢 Average pooling is an alternative method that smoothens the information by taking the average value within the specified area, which can be useful when preserving background information is important.
- 🌐 Global pooling operates on the entire image, either using max or average pooling to produce a single value that can be used for classification tasks without a fully connected layer.
- 📉 Max pooling reduces the spatial dimensions of the image, which can help in downscaling while retaining important features, thus simplifying the network and improving computational efficiency.
- 🔄 Padding is a technique used to maintain the dimensionality of the image after pooling by adding zeros around the image's border, which can be particularly useful in preserving the resolution for subsequent layers.
- 🛠️ The video demonstrates how to implement max pooling and padding in a CNN using TensorFlow and Keras, showcasing how to adjust pool size, strides, and padding within the model architecture.
- ↔️ Striding is a parameter that determines how the pooling window moves across the image; a stride of one moves the window element by element, whereas a larger stride covers more ground with each step.
- ↕️ The choice between using padding or not depends on the desired outcome: using 'same' padding maintains the image dimensions, while 'valid' reduces them, which can be useful for feature extraction at lower resolutions.
- 🔍 The video emphasizes the importance of understanding how pooling and padding affect the CNN's performance, as they influence the network's ability to learn from and make predictions based on image features.
- 📈 By reducing the image dimensions and complexity through pooling, the network can focus on the most significant features, which can enhance training and prediction speeds.
Q & A
What is the main focus of the video?
-The video focuses on explaining the concepts of pooling and convolutional networks, specifically discussing different pooling methods such as max pooling, average pooling, and global pooling, as well as the use of padding in convolutional neural networks.
Why is pooling often used after convolutional layers in CNNs?
-Pooling is used after convolutional layers to downscale the image while retaining the most important features. It helps to reduce the complexity of the network, decrease the amount of parameters, and make the network more robust to variations in the input data.
What is the purpose of max pooling?
-Max pooling is used to extract the most important pixels or features from a given region in the image. It selects the maximum value within the pooling window and is useful for keeping only the most significant information while reducing the spatial dimensions of the representation.
How does average pooling differ from max pooling?
-Average pooling calculates the average value of all pixels within the pooling window, which helps to smooth out the information in the image. It is used when one wants to retain a more comprehensive representation of the image rather than just the most significant features.
What is global pooling and when might it be used?
-Global pooling is a type of pooling that considers the entire image at once. It is used to reduce the spatial dimensions to a single vector, which can be useful when the fully connected layers are not needed, or when a single feature is to be extracted from the entire image.
Why is padding used in max pooling layers?
-Padding is used to maintain the dimensions of the image after pooling. It adds zeros around the image, which allows the pooling operation to be performed at the edges of the image without losing spatial resolution.
What is the effect of using strides in max pooling?
-Strides determine how many pixels the filter moves over the image for each iteration. A larger stride value means the pooling operation will cover more pixels in each step, which can reduce the spatial dimensions of the output image more quickly.
How does the choice between 'same' and 'valid' padding affect the output dimensions of the image?
-Using 'same' padding keeps the output dimensions the same as the input dimensions after pooling, while 'valid' padding does not add any padding and thus reduces the output dimensions based on the pool size and stride.
What is the role of a fully connected layer in a CNN?
-A fully connected layer is typically the last layer in a CNN, where the high-level features extracted by the convolutional and pooling layers are used to make predictions or classifications. It takes the flattened output from the previous layers and applies a dense network structure for the final task.
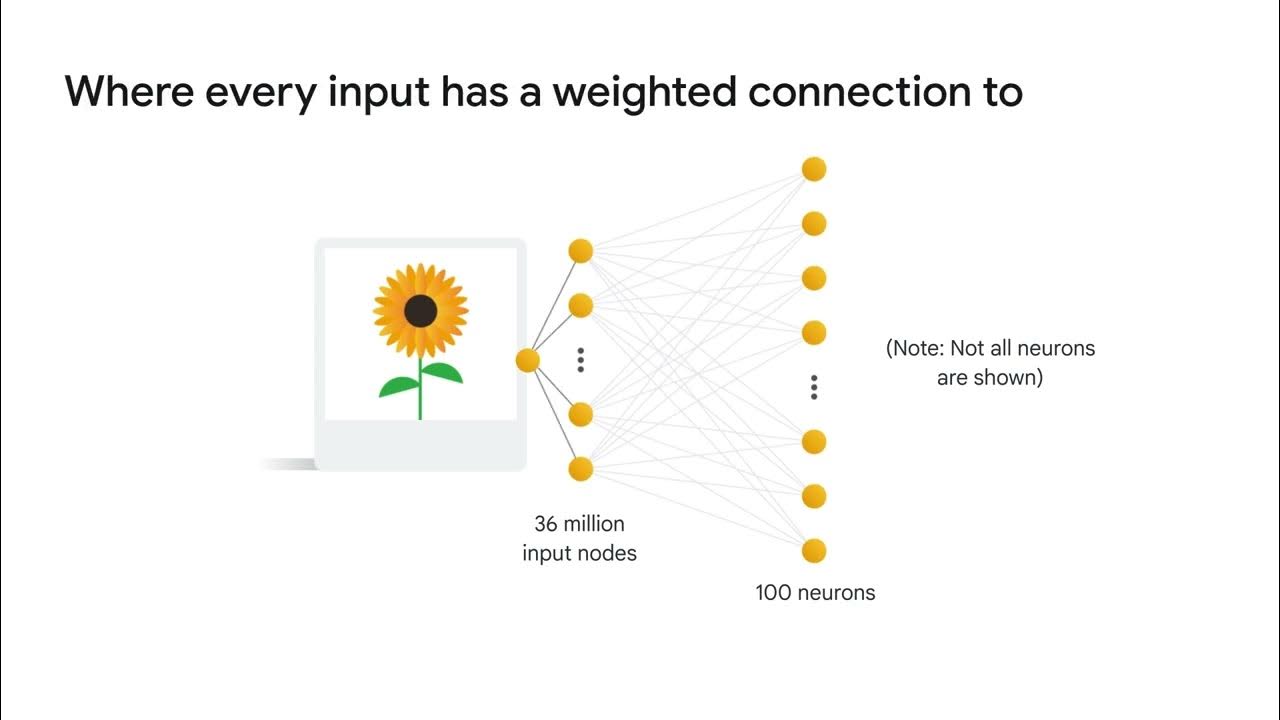
How does the complexity of CNNs differ from that of a standard ANN?
-CNNs are more complex than standard ANNs due to the additional layers and the presence of a large number of trainable parameters, such as the various filters used in convolutional layers, which the network learns during training.
What are some applications of CNNs mentioned in the video?
-The video mentions that CNNs are used in applications like autonomous driving by companies like Tesla, where they are utilized for tasks such as recognizing objects and making decisions based on visual input.
How can one join the community for discussing neural networks and deep learning?
-The video encourages viewers to join a Discord server, which is linked in the video description, to discuss topics related to neural networks, deep learning, computer vision, and to seek help or inspiration for their projects.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Visualizing CNNs
Convolutional Neural Networks
What is a convolutional neural network (CNN)?

Neural Networks Part 8: Image Classification with Convolutional Neural Networks (CNNs)

Convolutional Neural Networks Explained (CNN Visualized)

Simple explanation of convolutional neural network | Deep Learning Tutorial 23 (Tensorflow & Python)
5.0 / 5 (0 votes)