Fine-Tuning BERT for Text Classification (Python Code)
Summary
TLDRIn this video, the speaker discusses the fine-tuning of smaller language models like BERT for specific tasks, emphasizing the efficiency of adapting pre-trained models through additional training. The process of fine-tuning, contrasted with the challenges of developing massive models, is explained alongside concepts like masked language modeling and next sentence prediction. The speaker also highlights the importance of text classification and shares an example of fine-tuning BERT to identify fishing URLs. Additionally, techniques for model compression, such as distillation and quantization, are introduced to optimize performance without sacrificing efficiency.
Takeaways
- 😀 Fine-tuning smaller language models like Bert can enhance performance on specific tasks, such as classifying phishing URLs.
- 📚 Pre-trained models are trained on large datasets using self-supervised learning, allowing them to understand context without labeled data.
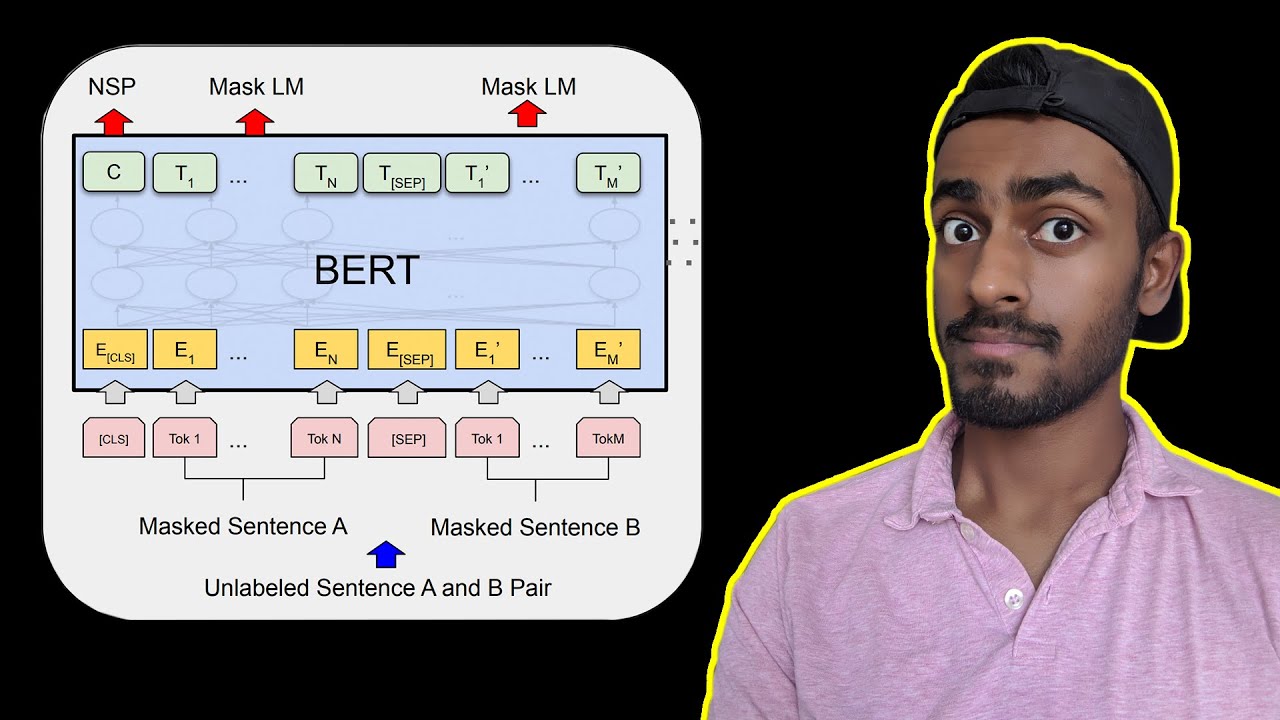
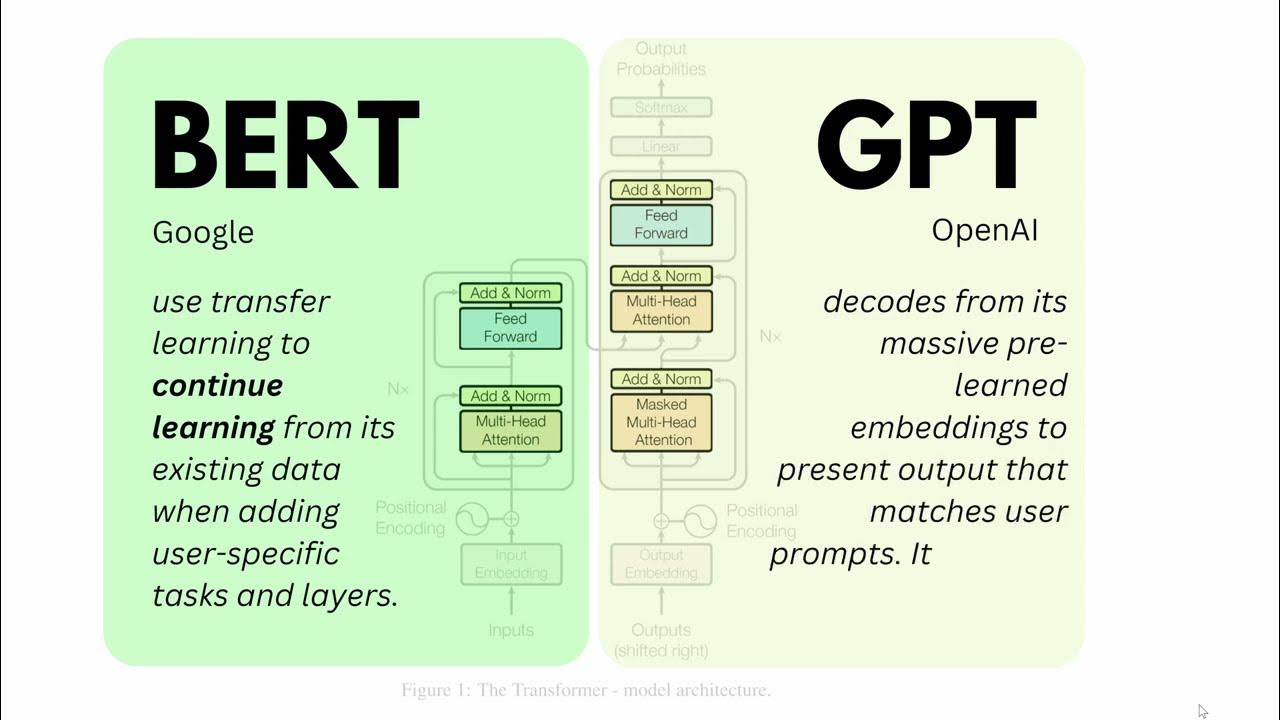
- 🧩 Masked language modeling (used in Bert) predicts masked words based on context from both sides of a sentence, unlike causal language modeling (used in GPT).
- 🔍 Fine-tuning is essential to adapt pre-trained models for specific applications, such as spam detection or sentiment analysis.
- ⚖️ Balancing between training on new data and retaining knowledge from pre-trained models is crucial to avoid overfitting.
- 🔄 Model compression techniques like distillation and quantization can significantly reduce memory usage while maintaining or improving performance.
- 📈 Model distillation involves training a smaller model (student) to replicate the behavior of a larger model (teacher), leading to a more efficient model.
- 🔧 Quantization reduces the precision of the model weights, enabling faster computations and lower memory requirements without drastically impacting accuracy.
- 🎯 The implementation of these techniques allows deployment in resource-constrained environments, enhancing accessibility and usability.
- 🙌 The video encourages viewers to explore further learning resources and highlights the importance of community support in data science.
Q & A
What is the main focus of the video?
-The video primarily focuses on fine-tuning a pre-trained BERT model for the specific task of URL classification, detailing the step-by-step process involved.
What does fine-tuning a model entail?
-Fine-tuning involves adapting a pre-trained model, like BERT, to perform a specific task by training it further on a labeled dataset.
What is BERT, and why is it used?
-BERT stands for Bidirectional Encoder Representations from Transformers. It is used due to its ability to understand the context of words in relation to all other words in a sentence, making it effective for various NLP tasks.
How is the training dataset structured in the example?
-The training dataset consists of 3,000 URLs, divided into 70% for training, 15% for validation, and 15% for testing.
What is the purpose of the tokenizer in the BERT model?
-The tokenizer converts text into integer sequences that the BERT model can process, facilitating the model's understanding of the input data.
Why are most parameters in the base BERT model frozen during training?
-Most parameters are frozen to reduce computational costs and prevent overfitting, allowing only the final layers to be adjusted during training.
What evaluation metrics are used to assess model performance?
-The evaluation metrics used include accuracy and the Area Under the Curve (AUC) score, which help gauge the model's effectiveness in classification tasks.
What results were observed during model training?
-The training loss decreased, indicating that the model learned effectively, while the validation loss remained stable, suggesting no overfitting occurred. The model achieved an accuracy of around 0.89 and an AUC score of approximately 0.95.
What are model compression techniques mentioned in the video?
-The video discusses model distillation and quantization as techniques for reducing a model's memory footprint by up to 7x without sacrificing performance.
How can fine-tuning improve a pre-trained model's performance?
-Fine-tuning allows the model to learn specific patterns and nuances from the new dataset, leading to better performance on the targeted task compared to using the model without adaptation.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Lecture 3: Pretraining LLMs vs Finetuning LLMs
BERT Neural Network - EXPLAINED!

Introduction to large language models
BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM
LLM Foundations (LLM Bootcamp)
Stanford XCS224U: NLU I Contextual Word Representations, Part 1: Guiding Ideas I Spring 2023
5.0 / 5 (0 votes)