LLM Foundations (LLM Bootcamp)
Summary
TLDRThe transcript discusses the Transformer architecture and its significance in machine learning, highlighting its use in models like GPT, T5, and BERT. It explains the concept of attention mechanisms, the role of pre-training and fine-tuning, and the evolution of large language models (LLMs). The talk also touches on the challenges of machine learning, such as the complexity of natural language processing and the importance of data sets in training. The presenter provides insights into the future of AI, emphasizing the potential of models that combine reasoning with information retrieval.
Takeaways
- 🌟 The talk introduces the Transformer architecture and its significance in the field of machine learning, highlighting its adaptability across various tasks.
- 🤖 The distinction between traditional programming (Software 1.0) and the machine learning mindset (Software 2.0) is explained, emphasizing the shift from algorithmic to data-driven approaches.
- 📈 The三种主要的机器学习类型被概述:无监督学习、监督学习和强化学习,各自适用于不同的数据结构和目标。
- 🧠 The inspiration behind neural networks and deep learning is drawn from the brain's structure and function, with the perceptron model being a key building block.
- 🔢 Computers process inputs and outputs as numerical vectors or matrices, requiring text to be tokenized and converted into numerical representations.
- 🏋️♂️ The training process of neural networks involves backpropagation, where the loss function guides the adjustment of weights to improve predictions.
- 🔄 The importance of splitting data into training, validation, and test sets is emphasized for model evaluation and to prevent overfitting.
- 📚 The concept of pre-training and fine-tuning is introduced, where a large model is trained on general data and then further trained on specific tasks.
- 🌐 The rise of model hubs like Hugging Face demonstrates the growing accessibility and sharing of pre-trained models and datasets.
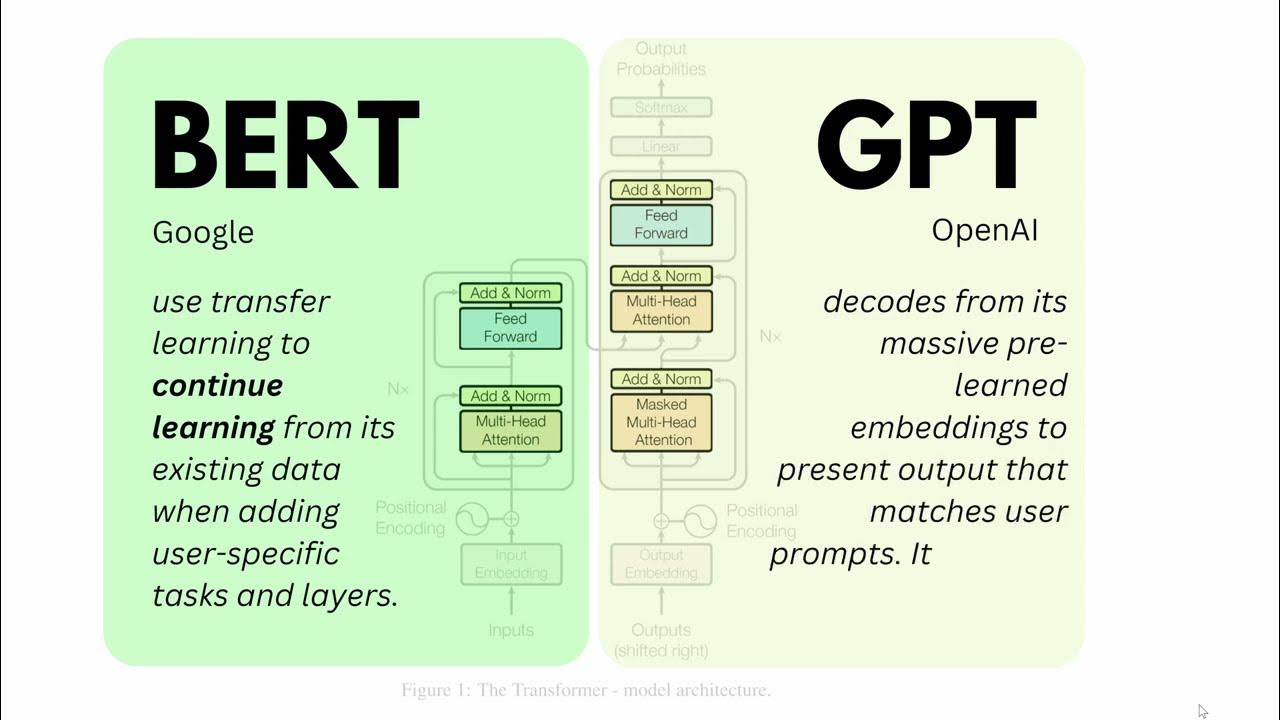
- 🔄 The Transformer model's architecture, including its encoder and decoder components, is explained, along with the concept of attention mechanisms.
- 🚀 The continuous growth and development of language models like GPT-3 and its successors are highlighted, showcasing the trend towards larger models with more parameters.
Q & A
What are the four key topics discussed in the transcript?
-The four key topics discussed are the Transformer architecture, notable large language models (LLMs) such as GPT, details of running a Transformer, and the foundations of machine learning.
What is the difference between software 1.0 and software 2.0 in the context of programming?
-Software 1.0 refers to traditional programming where a person writes code for a robot to take input and produce output based on algorithmic rules. Software 2.0, on the other hand, involves writing a robot that uses training data to produce another robot, which then takes input data and produces output. The second robot is not algorithmic but is driven by parameters learned from the training data.
What are the three main types of machine learning mentioned in the transcript?
-The three main types of machine learning are unsupervised learning, supervised learning, and reinforcement learning.
How do neural networks and deep learning relate to the brain?
-Neural networks and deep learning are inspired by the brain. They attempt to mimic the way neurons in the brain receive inputs, process them, and produce outputs. The concept of a perceptron, which is a model of a neuron, is used to create neural networks by stacking perceptrons in layers.
What is the significance of GPUs in the advancement of deep learning?
-GPUs, which were originally developed for graphics and video games, are highly efficient at performing matrix multiplications. Since neural networks and deep learning involve大量的 matrix multiplications, the application of GPUs has significantly accelerated the training and development of these models.
What is the role of the validation set in machine learning?
-The validation set is used to prevent overfitting in machine learning models. It allows developers to evaluate the model's performance on unseen data during training and adjust the model as needed, ensuring that the model generalizes well to new data.
How does the Transformer architecture handle the issue of input and output sequence lengths?
-The Transformer architecture uses a mechanism called attention, which allows the model to weigh the importance of different parts of the input sequence when predicting the next token in the output sequence. This mechanism enables the model to handle variable lengths of input and output sequences effectively.
What is the purpose of positional encoding in the Transformer model?
-Positional encoding is added to the input embeddings to provide the model with information about the order of the tokens within the sequence. Since the Transformer architecture does not inherently consider the order of tokens, positional encoding helps the model understand the sequence's structure and the relative positions of the tokens.
What is the concept of pre-training and fine-tuning in machine learning models?
-Pre-training involves training a large model on a vast amount of data to learn general representations. Fine-tuning then involves further training this pre-trained model on a smaller, more specific dataset to adapt the model for a particular task or domain.
How does the concept of instruction tuning enhance the capabilities of large language models?
-Instruction tuning involves fine-tuning a pre-trained model on a dataset of instructions and desired outputs. This process improves the model's ability to follow instructions and perform tasks in a zero-shot or few-shot context, without the need for additional examples or prompts.
What is the significance of including code in the training data for large language models?
-Including code in the training data has been found to improve the performance of large language models on non-code tasks. It enhances the model's understanding of logical structures and problem-solving, which can be beneficial for a wide range of applications.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

The History of Natural Language Processing (NLP)

Introduction to Generative AI n explainable AI

Stanford CS25: V1 I Transformers United: DL Models that have revolutionized NLP, CV, RL

W05 Clip 4
BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM

What Is Transfer Learning? | Transfer Learning in Deep Learning | Deep Learning Tutorial|Simplilearn
5.0 / 5 (0 votes)