DP-203: 11 - Dynamic Azure Data Factory
Summary
TLDRThe video script offers a detailed tutorial on creating dynamic pipelines in Azure Data Factory (ADF) to efficiently copy data from multiple tables in an Azure SQL database to a data lake. It demonstrates the process of setting up a generic linked service, dynamic datasets, and leveraging expressions for flexibility. The tutorial guides through building a 'for each' loop and copy activity to iterate over tables, automatically generating directories and CSV files for each table's data, showcasing the power of ADF's dynamic capabilities.
Takeaways
- 🌟 The video discusses creating a dynamic pipeline in Azure Data Factory (ADF) to copy data from multiple tables in an Azure SQL database to a data lake.
- 🔗 It emphasizes the importance of using dynamic linked services and datasets to avoid hardcoding specific database instances or tables, thus improving the flexibility of the pipeline.
- 🛠 The tutorial starts by connecting to an Azure SQL database using Management Studio and retrieving a list of all tables for processing.
- 🔍 A 'Lookup' activity is introduced to query the database for table names, which is a key component for handling multiple tables dynamically.
- 📚 The script explains how to create generic datasets that can represent any data from an SQL database, rather than creating specific datasets for each table.
- 🔑 Parameters such as server name and database name are used to make the connection to the SQL database dynamic, allowing the pipeline to connect to any database at runtime.
- 🔄 The 'For Each' activity is used to iterate over the list of tables retrieved by the lookup activity, enabling the pipeline to process each table in turn.
- 🚀 The 'Copy Data' activity within the 'For Each' loop is configured to use dynamic queries to pull data from the current table being iterated over.
- 🗂 The target dataset is made dynamic to save data into a data lake with a directory structure that includes server name, database name, and ingestion date.
- 📝 The tutorial suggests enhancing the pipeline by using incremental queries to copy only new or updated data instead of retrieving all rows every time.
- 💡 The presenter concludes by highlighting the power of expressions in ADF for creating flexible and dynamic data processing pipelines, and encourages viewers to practice and explore these capabilities.
Q & A
What is the main topic discussed in the video script?
-The main topic discussed in the video script is creating dynamic pipelines in Azure Data Factory (ADF) to copy data from multiple tables in an Azure SQL database to a data lake.
Why is it not ideal to create a separate pipeline for each table in Azure Data Factory?
-Creating a separate pipeline for each table is not ideal because it leads to a non-scalable design with potentially hundreds of datasets and pipelines, which is not efficient or maintainable.
What is a linked service in the context of Azure Data Factory?
-A linked service in Azure Data Factory is a connection string that points to a specific resource, such as an instance of an Azure SQL database, and is used to connect to that resource within ADF.
How can a linked service be made dynamic in Azure Data Factory?
-A linked service can be made dynamic by parameterizing it to accept values such as server name and database name at runtime instead of hardcoding them at design time.
What is a dataset in Azure Data Factory and how can it be made dynamic?
-A dataset in Azure Data Factory represents the structure of the data in a source or a destination. It can be made dynamic by creating a generic dataset that can represent any data read from a SQL database without being tied to a specific table or query at design time.
What is the purpose of the lookup activity in the dynamic pipeline discussed in the script?
-The purpose of the lookup activity in the dynamic pipeline is to query the database for a list of all tables that need to be processed, allowing the pipeline to iterate over and process each table dynamically.
How does the 'For Each' activity in ADF work within the context of the script?
-The 'For Each' activity in ADF is used to iterate over a list of elements, such as the list of tables returned by the lookup activity. Inside the 'For Each' loop, a copy activity is executed for each table to copy its data to the data lake.
What is the significance of using dynamic expressions in the pipeline activities?
-Dynamic expressions allow for flexibility and scalability in the pipeline. They enable the pipeline to adapt to different scenarios at runtime, such as connecting to different databases or tables without the need for hardcoding values.
What are some limitations or potential improvements for the dynamic pipeline discussed in the script?
-Some limitations include the use of hardcoded SQL authentication credentials, which is not secure, and the lack of incremental data loading logic, which could lead to unnecessary data transfers if all rows are fetched every time.
How can the structure of the data lake be improved according to the script?
-The structure of the data lake can be improved by adding a dataset name in the path, organizing files not only by server, database, and date, but also by the specific dataset or table name, making it easier to locate and manage data.
What is the final outcome of executing the dynamic pipeline as described in the script?
-The final outcome is that the pipeline dynamically connects to an Azure SQL database, retrieves a list of all tables, and then iterates over each table to copy its data into corresponding CSV files in the data lake, organized by server, database, schema, and table names.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифПосмотреть больше похожих видео

DP 203 Dumps | DP 203 Real Exam Questions | Part 2

84. Databricks | Pyspark | Azure Data Factory + Azure Databricks: Execute Notebook Via ADF
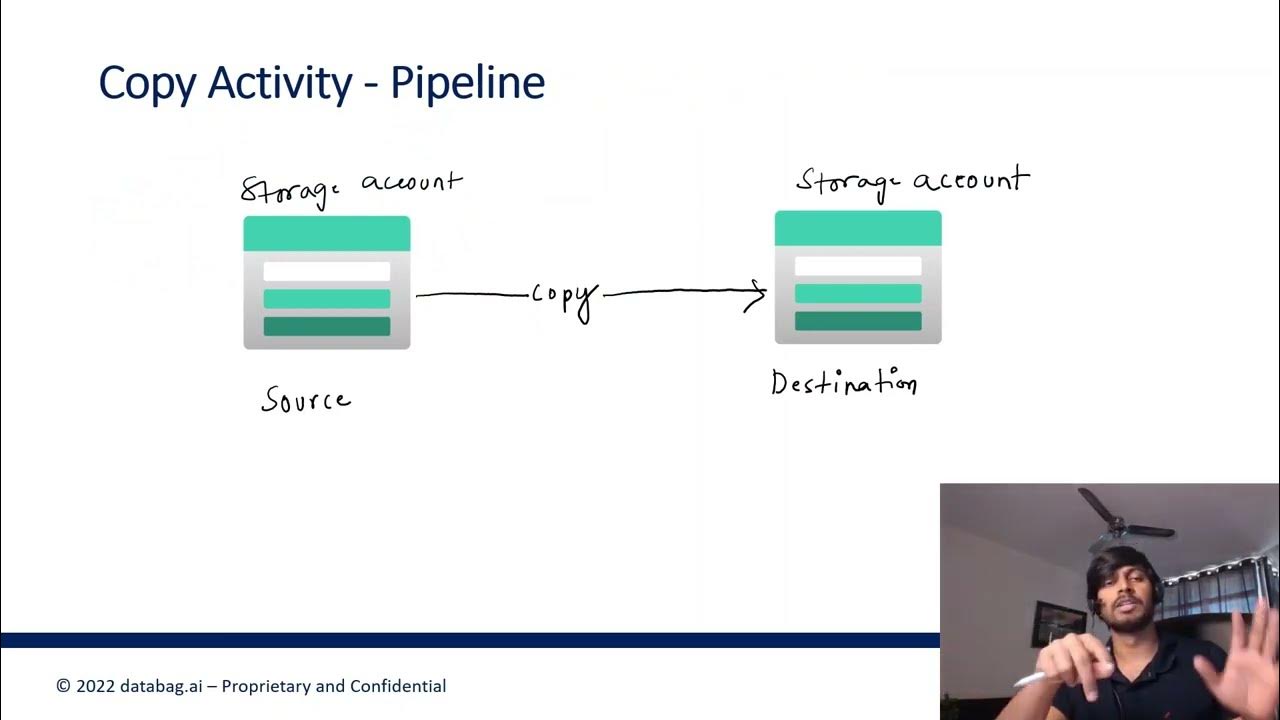
Azure Data Factory Part 3 - Creating first ADF Pipeline
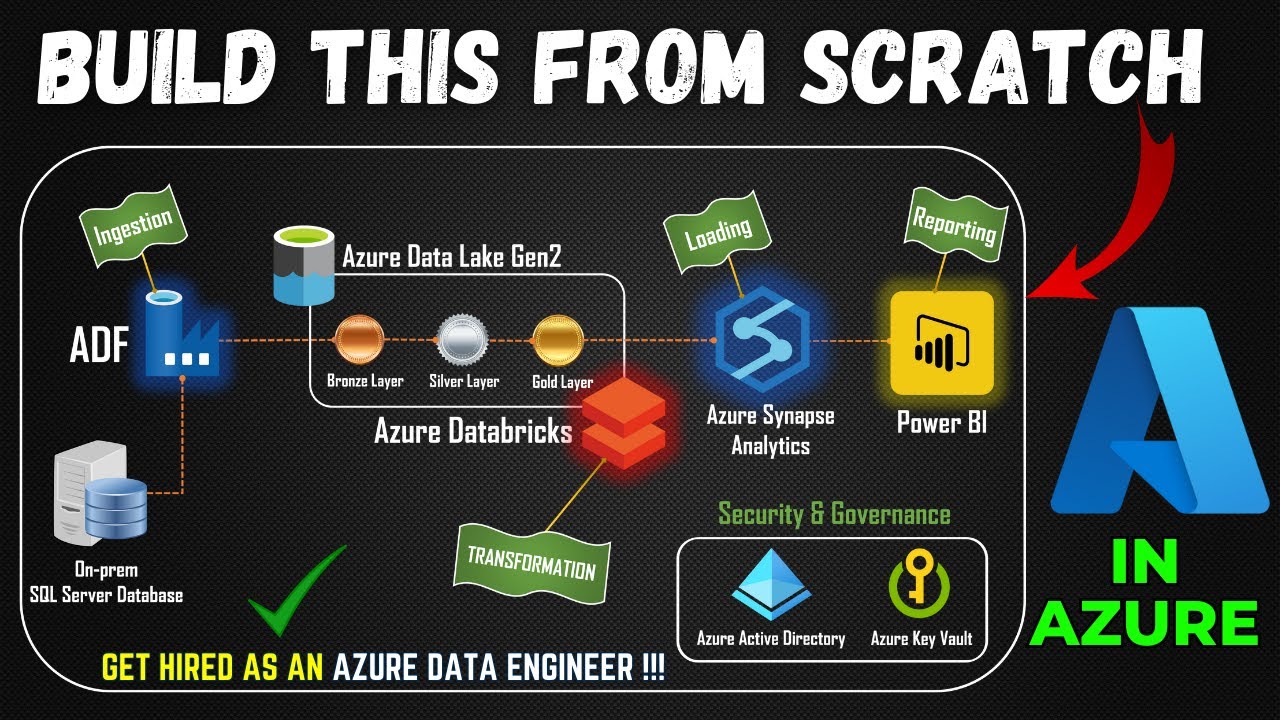
Part 1- End to End Azure Data Engineering Project | Project Overview

23.Copy data from multiple files into multiple tables | mapping table SQL | bulk

DP-900 Exam EP 03: Data Job Roles and Responsibilities
5.0 / 5 (0 votes)
