Azure Data Factory Part 3 - Creating first ADF Pipeline
Summary
TLDRThis video tutorial guides viewers through creating their first Azure Data Factory pipeline. It covers the basics of setting up an ADF instance, creating storage accounts, and utilizing copy activities to transfer data from a source to a destination. The host explains the importance of linked services and datasets, and demonstrates the process of building and triggering a pipeline. The session concludes with a successful data transfer example, offering a foundational understanding of Azure Data Factory's capabilities for ETL processes.
Takeaways
- 😀 The video is part of a series on Azure Data Factory, focusing on creating a pipeline for data transfer.
- 🔧 The session covers the creation of an Azure Data Factory instance as a prerequisite for building pipelines.
- 📂 It demonstrates the process of creating storage accounts and organizing data within them into source and destination directories.
- 🔄 The primary task of the pipeline is to copy data from a source to a destination using a copy activity.
- 🔗 The importance of linked services in connecting to data sources within Azure Data Factory is emphasized.
- 📝 The video explains the role of data sets in mapping the exact data to be used in the pipeline.
- 🛠️ The tutorial walks through the steps of creating a pipeline, including naming it and selecting the copy data activity.
- 📁 It shows how to create and configure data sets for both input and output, specifying the file format and storage locations.
- 🔑 The process of setting up a linked service with authentication details for accessing the storage account is detailed.
- 🔄 The video discusses the concept of integration runtime, which acts as a bridge between data sets and activities.
- 🚀 The final steps include publishing changes, triggering the pipeline manually, and monitoring its execution.
Q & A
What is the main focus of the video series part three?
-The main focus of the video series part three is to create the first Azure Data Factory pipeline, which involves copying data from a source to a destination using a copy activity within Azure Data Factory.
What are the top-level components within Azure Data Factory mentioned in the previous lecture?
-The top-level components within Azure Data Factory mentioned in the previous lecture include pipelines, activities, datasets, integration runtimes, and triggers.
What is the first step in creating an Azure Data Factory pipeline?
-The first step in creating an Azure Data Factory pipeline is to create an Azure Data Factory (ADF) instance in Microsoft Azure.
What is the purpose of a storage account in the context of this video?
-In the context of this video, the purpose of a storage account is to provide a location to store files that will be used as the source and destination in the data copying process within the Azure Data Factory pipeline.
What is a linked service in Azure Data Factory?
-A linked service in Azure Data Factory acts as a connection string, connecting the data factory to external resources such as storage accounts, databases, and other services.
What is the role of integration runtime in the Azure Data Factory pipeline?
-Integration runtime acts as a bridge between the data factory and the data sources. It is used for activities like copying data from one location to another within the pipeline.
What type of activity is used in the pipeline to copy data from source to destination?
-A copy activity is used in the pipeline to copy data from the source to the destination.
How can you create a new dataset in Azure Data Factory?
-You can create a new dataset in Azure Data Factory by going to the 'Datasets' section and clicking on 'New' or by clicking on the 'Dataset' option when creating a new pipeline.
What is the difference between an input dataset and an output dataset in the context of this video?
-In the context of this video, an input dataset refers to the source data location from which the data will be copied, while an output dataset refers to the destination data location where the data will be copied to.
What does publishing changes in Azure Data Factory mean?
-Publishing changes in Azure Data Factory means submitting the saved changes to the ADF service, making them available for execution in the cloud.
How can you run or trigger the pipeline after it has been created and published?
-You can run or trigger the pipeline by using the 'Trigger Now' option, which allows for a manual trigger to start the pipeline execution.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
Azure Data Factory Part 6 - Triggers and Types of Triggers
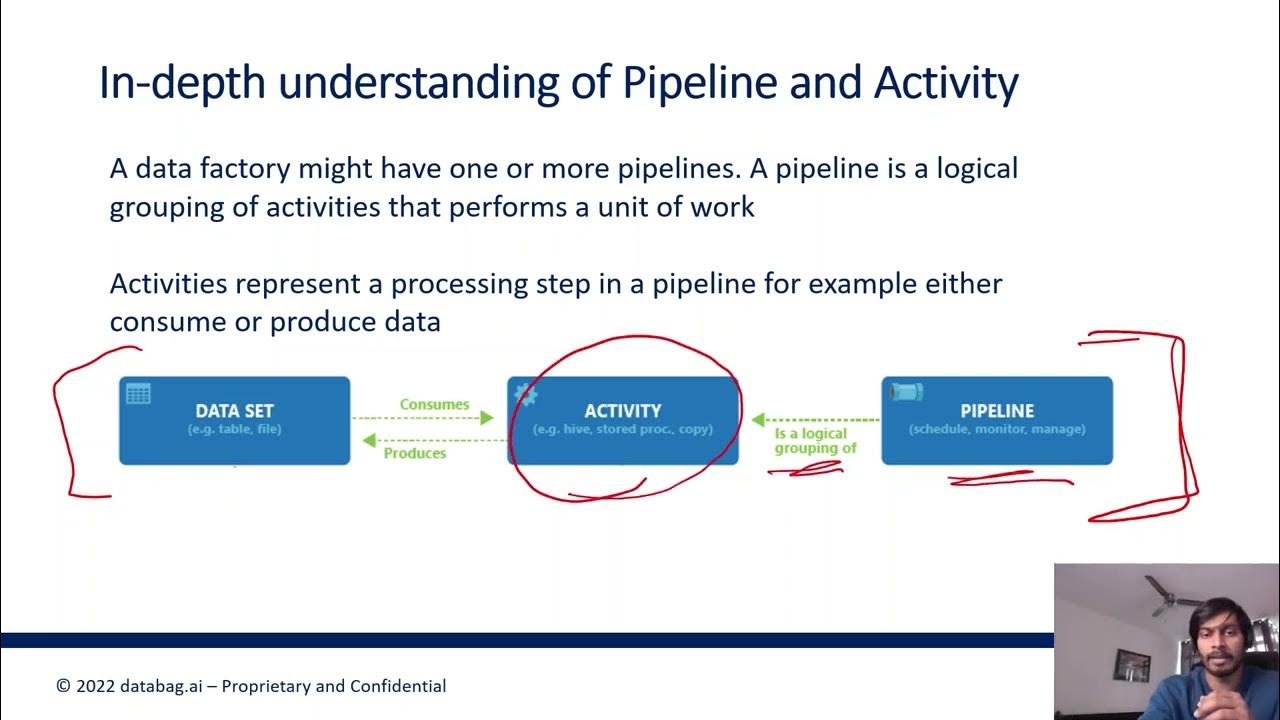
Azure Data Factory Part 5 - Types of Data Pipeline Activities

#16. Different Activity modes - Success , Failure, Completion, Skipped |AzureDataFactory Tutorial |

DP-203: 11 - Dynamic Azure Data Factory

Part 8 - Data Loading (Azure Synapse Analytics) | End to End Azure Data Engineering Project

23.Copy data from multiple files into multiple tables | mapping table SQL | bulk
5.0 / 5 (0 votes)