Notation and Formulas for Summary Statistics
Summary
TLDRThis video explains how to numerically summarize data through measures of central tendency (mean, median, mode) and dispersion (range, variance, standard deviation). It emphasizes the difference between population and sample data and the importance of understanding these distinctions in statistical analysis. The mean, while commonly used, is sensitive to outliers, making the median a more reliable measure in some cases. The video also highlights the formulas for standard deviation and variance, including the differences between sample and population calculations, and introduces essential tools like Excel for data analysis.
Takeaways
- 😀 Data summaries, both visually and numerically, are essential for understanding data, but one number can never fully summarize an entire data set.
- 😀 The average (mean) does not always represent the full picture of data and can be skewed by outliers, which is why it's important to understand measures of central tendency and dispersion.
- 😀 Measures of central tendency (mean, median, mode) tell you the typical value of a data set, while measures of dispersion (range, standard deviation, variance) tell you how spread out the data is.
- 😀 The size of the data set is represented by the symbol 'N' for populations and 'n' for samples. This distinction is critical when analyzing data.
- 😀 The mean is represented by 'μ' (mu) for populations and 'x̄' (x-bar) for samples. Both require adding up all values and dividing by the number of values.
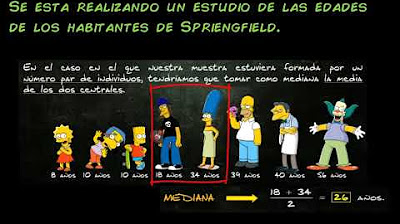
- 😀 The median, unlike the mean, is not sensitive to outliers and is found by sorting the data and identifying the center value.
- 😀 The mode is the value that occurs most often in the data set, and it's the simplest measure of central tendency.
- 😀 Range is a basic measure of dispersion, calculated by subtracting the minimum value from the maximum value, but it doesn't capture all the variation within the data.
- 😀 Standard deviation and variance both measure the spread of data. The standard deviation averages the squared differences from the mean, while variance is simply the square of the standard deviation.
- 😀 The sample standard deviation differs slightly from the population standard deviation due to the use of 'n-1' instead of 'n' in the denominator to correct for bias in estimating the population standard deviation.
Q & A
What is the main goal of summarizing data numerically?
-The main goal of numerically summarizing data is to represent the data set using numbers that provide a clearer, simpler overview of the information. These numbers, though not perfect, give insight into the data’s general trends and patterns.
Why is the average (mean) considered imperfect for summarizing data?
-The average (mean) is considered imperfect because it is sensitive to outliers. If there are extreme values in the data set, they can significantly affect the mean, making it not fully representative of the data.
What is the difference between the mean of a population and a sample?
-The mean of a population is denoted by the Greek letter 'mu' (μ), while the mean of a sample is represented as 'x-bar' (x̄). Although both are calculated by summing the data values and dividing by the count, the symbols differ based on whether you're dealing with a population or a sample.
What is the median, and how does it differ from the mean?
-The median is the center value of a sorted data set, or the average of the two middle values if there is an even number of data points. Unlike the mean, the median is not sensitive to outliers and better represents the central tendency when the data is skewed.
What does the mode represent in a data set?
-The mode represents the value that occurs most frequently in a data set. It is the simplest measure of central tendency, but it might not always be useful if there are no repeated values or multiple modes.
What is the range, and how is it calculated?
-The range is a measure of dispersion that indicates how spread out the data values are. It is calculated by subtracting the minimum value from the maximum value in the data set.
How does standard deviation help describe the spread of data?
-Standard deviation measures the average distance of data points from the mean. A low standard deviation indicates that most data points are close to the mean, while a high standard deviation means the data is more spread out.
What is the difference between population and sample standard deviation?
-The population standard deviation uses 'σ' (sigma) and divides by 'N', the total number of data points. The sample standard deviation uses 's' and divides by 'n - 1' instead of 'n' to account for the degrees of freedom and provide a better estimate for the population.
What is variance, and how does it relate to standard deviation?
-Variance is the square of the standard deviation. It represents the average of the squared deviations from the mean, and it helps quantify how spread out the data is. To find the standard deviation from the variance, you simply take the square root.
Why is it important to understand the difference between a population and a sample in statistics?
-Understanding the difference between a population and a sample is crucial because statistical methods like mean and standard deviation use different formulas depending on whether you are working with a full population or a sample. Incorrectly applying these formulas can lead to inaccurate results and conclusions.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

Descriptive Statistics: FULL Tutorial - Mean, Median, Mode, Variance & SD (With Examples)

Descriptive Statistics [Simply explained]

Range, variance and standard deviation as measures of dispersion | Khan Academy

2.5 Medidas descriptivas
ESTADISTICA DESCRIPTIVA.- PARAMETROS DE CENTRALIZACION Y DISPERSION.

03. Cómo describir una variable numérica | Curso de SPSS
5.0 / 5 (0 votes)
