#22 Cluster Analysis - Properties, Categories Of Methods |DM|
Summary
TLDRIn this video, the speaker introduces the concept of cluster analysis in data mining, explaining it as the process of grouping similar objects together to form clusters. The speaker outlines the key properties of clustering, including scalability, usability with multiple data types, the ability to handle unstructured data, and interoperability. Additionally, six clustering methods are discussed, with a focus on the most common ones: partitioning (K-means), hierarchical (agglomerative and divisive), density-based (DBScan), and grid-based methods. Viewers are encouraged to stay tuned for future videos diving deeper into each method.
Takeaways
- 😀 Cluster analysis is a process of grouping similar objects together into clusters based on shared characteristics.
- 😀 The concept of clustering is a part of unsupervised machine learning, meaning no pre-labeled data is used.
- 😀 Cluster analysis involves grouping objects into clusters, ensuring that similar objects are placed together.
- 😀 A simple example of clustering is separating boys and girls in a classroom into two clusters.
- 😀 The key properties of cluster analysis include scalability, algorithm usability, dealing with unstructured data, and interoperability.
- 😀 Clustering scalability ensures that clusters can be formed regardless of data size (from MBs to TBs).
- 😀 Algorithms used in clustering should be versatile and work with various types of data, including discrete, continuous, and multimedia data.
- 😀 Cluster analysis can handle unstructured data, like graphs and trees, which do not follow a specific structure.
- 😀 Interoperability refers to the ability of cluster algorithms to function across different systems and platforms.
- 😀 Four common clustering methods are: Partitioning (e.g., K-means), Hierarchical (e.g., Agglomerative and Divisive), Density-based (e.g., DBSCAN), and Grid-based methods.
- 😀 The video promises separate tutorials for each of the clustering methods, including in-depth discussions on K-means, DBSCAN, and other algorithms.
Q & A
What is cluster analysis in data mining?
-Cluster analysis, or clustering, is the process of grouping similar objects together to form clusters. These objects are grouped based on their similar characteristics, and the result is called a cluster.
What are the main properties of clusters in cluster analysis?
-The main properties of clusters include clustering scalability (ability to handle data of any size), algorithm usability with multiple types of data (support for discrete, continuous, text, images, etc.), the ability to deal with unstructured data, and interoperability (ability to operate across different systems or environments).
Can cluster analysis be applied to all types of data?
-Yes, cluster analysis can be applied to various types of data, including discrete data, continuous data, images, videos, and unstructured data, such as graphs or trees.
What is meant by 'clustering scalability'?
-Clustering scalability refers to the ability of clustering algorithms to form clusters regardless of the data size. Whether the data is in megabytes, gigabytes, or terabytes, the algorithm should be able to handle it effectively.
What types of data can clustering algorithms handle?
-Clustering algorithms can handle multiple types of data, including grouped data (discrete and continuous), images, videos, and unstructured data such as text or graphs.
What does 'interoperability' in clustering mean?
-Interoperability in clustering means that the clustering algorithm can be used across different systems or environments. It ensures that the algorithm can work on different platforms and with different types of data.
What are the different methods used in cluster analysis?
-The six main methods used in cluster analysis are: partitioning method, hierarchical method, density-based method, grid-based method, model-based method, and constraint-based method.
Which clustering methods are most commonly used?
-The most common clustering methods are partitioning, hierarchical, density-based, and grid-based methods. These are the main methods discussed in the video.
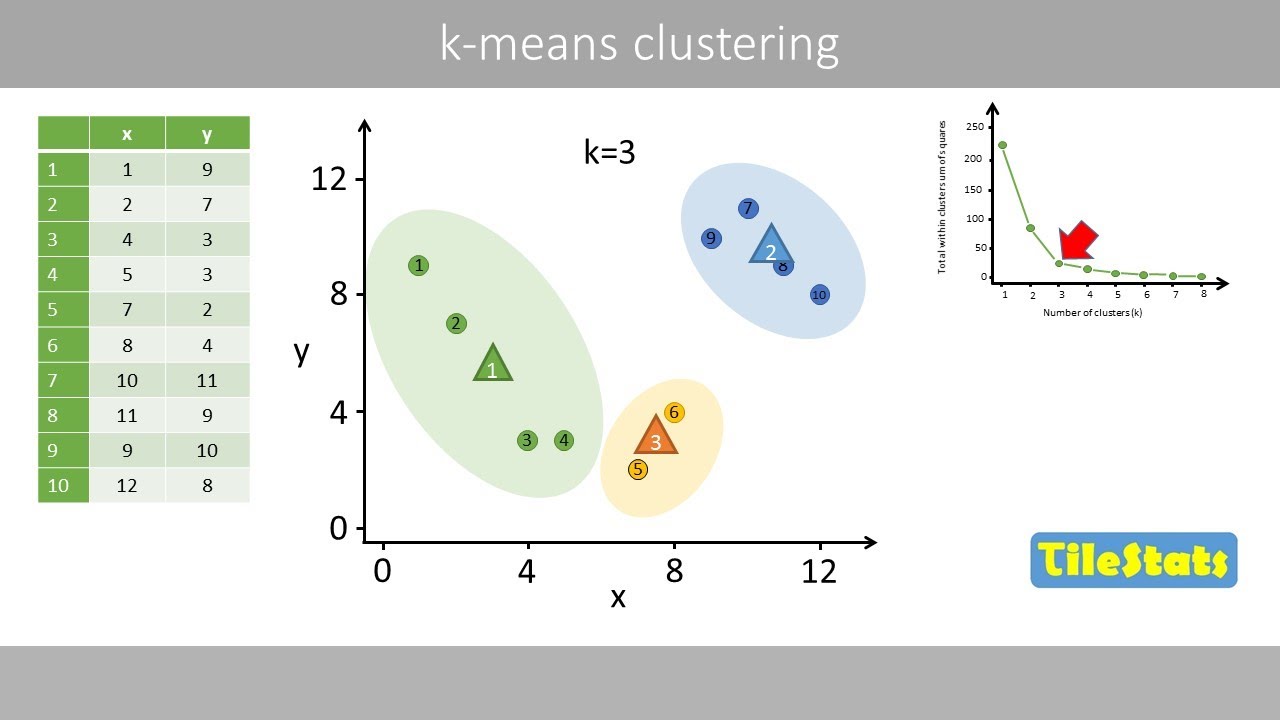
What is the k-means algorithm?
-The k-means algorithm is a partitioning method used for clustering. It divides data into 'k' clusters based on the mean of the data points in each cluster. It is one of the most popular methods for clustering.
What is the difference between agglomerative and divisive hierarchical methods?
-Agglomerative and divisive methods are both hierarchical clustering techniques. Agglomerative clustering starts with individual data points as their own clusters and merges them step by step. In contrast, divisive clustering begins with one large cluster and splits it into smaller ones progressively.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenant




5.0 / 5 (0 votes)
