YOLOv10 Architecture Explained - A Complete Breakdown
Summary
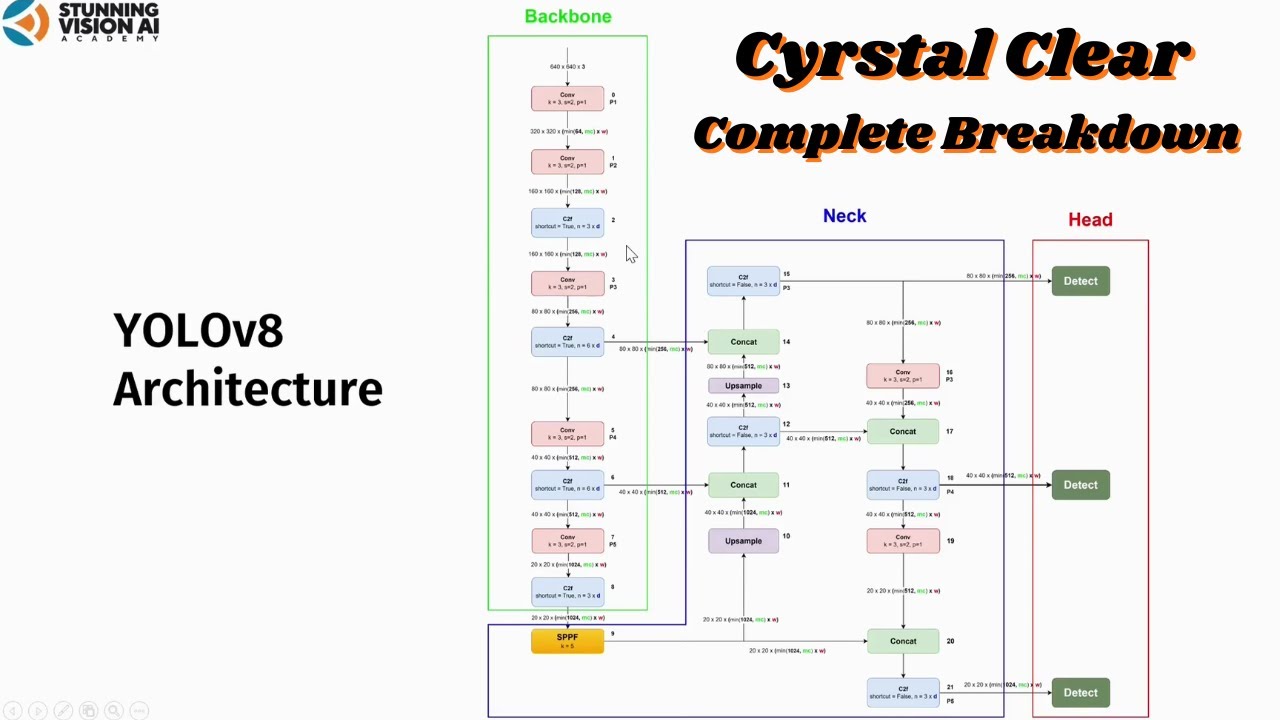
TLDRThis video provides a detailed breakdown of the YOLOv10 architecture, covering its core components: the backbone, neck, and head. It explores key blocks like convolutional layers, C2F blocks, and self-attention mechanisms, explaining their functions and how they contribute to efficient object detection. The video also delves into specialized techniques such as sparse pyramid pooling (SPF) and depthwise convolutions. With an emphasis on performance optimization, YOLOv10 is tailored for real-time, high-accuracy detection of objects of various sizes in images, making it a powerful tool in computer vision.
Takeaways
- 😀 YOLO v10 architecture requires understanding both the theory in the paper and the source code for full comprehension.
- 😀 The convolutional block is the core unit in YOLO v10, combining convolution, batch normalization, and activation functions like the Silo activation.
- 😀 The C2F block includes convolutional and bottleneck blocks, allowing for feature splitting and combining using concatenation.
- 😀 The C2F block's bottleneck blocks can either use a shortcut (skip connection) or not, depending on the configuration.
- 😀 CIB blocks in YOLO v10 involve depthwise convolutions and additional parameters, improving efficiency in feature extraction.
- 😀 SPF (Spatial Pyramid Pooling Fast) helps in generating fixed feature representations of objects of varying sizes without resizing the image.
- 😀 PSA (Partial Self-Attention) block is used to capture long-range dependencies in the image and helps improve detection across multiple scales.
- 😀 YOLO v10 has a Backbone, Neck, and Head structure, where the Backbone extracts features, the Neck combines them, and the Head makes predictions.
- 😀 The F1 Detect block is specialized for detecting small, medium, and large objects in the image and is located at the Head of the architecture.
- 😀 YOLO v10 is modular, with different variants (L, S, N) that adjust the depth, width, and channels based on the model's computational needs.
Q & A
What is the primary function of the YOLOv10 backbone?
-The primary function of the YOLOv10 backbone is to extract features from the input image, utilizing various convolutional blocks to process the image at different resolution levels.
What is the purpose of the C2F block in YOLOv10?
-The C2F block in YOLOv10 consists of convolutional blocks and bottleneck blocks, and it is used to refine the features extracted by the backbone by splitting and merging feature maps to enhance the model's ability to detect objects.
How does the CIB block differ from the C2F block in YOLOv10?
-The CIB block is a variant of the C2F block, replacing bottleneck blocks with CIB blocks and incorporating large kernel convolution when the LK parameter is true, making it more suitable for processing complex features.
What role does the SC Down block play in YOLOv10?
-The SC Down block performs downsampling by reducing the resolution of feature maps, while also reducing computational burden by processing each channel separately through depthwise convolution.
What is the function of the SPF (Spatial Pyramid Fast Pooling) block?
-The SPF block generates a fixed feature representation for objects of various sizes without resizing the image, preserving spatial information and enabling efficient multi-scale object detection.
What is the PSA block used for in YOLOv10?
-The PSA (Partial Self-Attention) block is used to model global relationships between distant features in the image, helping the model understand the contextual dependencies across the entire image.
What does the F1 Detect block specialize in within YOLOv10?
-The F1 Detect block specializes in generating predictions for different object sizes (small, medium, and large) by processing feature maps at various resolutions and producing bounding box and class predictions.
How does YOLOv10 handle varying object sizes in an image?
-YOLOv10 handles varying object sizes by using multiple detection blocks (F1 Detect) that specialize in detecting small, medium, and large objects. These blocks process feature maps from different resolutions for more accurate object detection.
What parameters control the architecture's variance in YOLOv10?
-In YOLOv10, the architecture's variance is controlled by three parameters: depth multiple, width multiple, and max channels. These parameters determine the number of blocks used and the output channel sizes at each stage of the model.
What is the function of the upsampling layer in YOLOv10's neck?
-The upsampling layer increases the feature map resolution by using the nearest neighbor method. This is done to match the feature map resolution of earlier blocks, ensuring proper concatenation of feature maps from different stages in the neck.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes





5.0 / 5 (0 votes)
