YOLOv8 Architecture Detailed Explanation - A Complete Breakdown
Summary
TLDRThis video provides a detailed breakdown of the YOLO v8 architecture, explaining its core components, including convolutional blocks, c2f blocks, bottleneck blocks, and the detect block. The architecture is designed to efficiently extract features, combine them, and make object predictions. Key parameters like depth multiple, width multiple, and max channels are discussed in the context of feature extraction and output generation. With a focus on real-time object detection, YOLO v8 offers improvements in speed and accuracy, leveraging spatial pyramid pooling and advanced convolution techniques.
Takeaways
- 😀 YOLO F8 architecture is primarily composed of several key blocks: Convolutional Block, C2F Block, SPF Block, and Detect Block.
- 😀 The Convolutional Block includes 2D Convolution, Batch Normalization, and SEU (Swish/sigmoid) activation functions fused together.
- 😀 The C2F Block splits feature maps into two paths: one going through a Bottleneck Block and the other to the Concatenate Block.
- 😀 Bottleneck Blocks in YOLO F8 are similar to ResNet but lack shortcuts, making them simpler and more efficient.
- 😀 The SPF Block (Spatial Pyramid Pooling Fast) is a speed-optimized version of spatial pyramid pooling, which helps to handle objects at various scales without resizing images.
- 😀 YOLO F8 uses an anchor-free approach for predictions, meaning object detection happens directly within grid cells.
- 😀 The Detect Block in YOLO F8 predicts bounding boxes and class labels, with two separate tracks for each: one for box predictions and one for class predictions.
- 😀 YOLO F8 uses three main parameters to define the variant: Depth Multiple, Width Multiple, and Max Channels. These adjust the network's depth, width, and output channels.
- 😀 The backbone of YOLO F8 is a series of convolutional layers designed to extract features at various resolutions, starting from a high-resolution input image.
- 😀 YOLO F8's Neck section combines feature maps from the backbone and prepares them for detection by upsampling and concatenating feature maps from earlier layers.
Q & A
What is the YOLOv8 architecture and how is it structured?
-The YOLOv8 architecture is divided into three main parts: the backbone, neck, and head. The backbone is responsible for feature extraction, the neck combines features from different layers, and the head makes final predictions for object detection, including bounding boxes and class predictions.
What are the key components of the convolutional block in YOLOv8?
-A convolutional block in YOLOv8 consists of a 2D convolutional layer, batch normalization, and a ReLU activation function. These components are fused together to form the block.
What does the C2F block do in the YOLOv8 architecture?
-The C2F block in YOLOv8 includes a convolutional block followed by a bottleneck block. The resulting feature maps are split, with one part going to a bottleneck block and the other to a concatenation block. It is designed to optimize feature extraction with deep learning layers.
How is the bottleneck block related to the ResNet block?
-The bottleneck block in YOLOv8 is similar to the ResNet block but without the shortcut connection. It is a sequence of convolutional blocks designed to process and refine feature maps.
What is the function of the Spatial Pyramid Pooling Fast (SPF) block in YOLOv8?
-The SPF block in YOLOv8 is designed to generate fixed-size feature representations for objects of various sizes in an image, without resizing the image or losing spatial information. It speeds up the spatial pyramid pooling process.
How does the YOLOv8 detect objects without using anchors?
-YOLOv8 is an anchor-free model, meaning it doesn't rely on anchor boxes for object detection. Instead, predictions are made directly from grid cells, with separate tracks for bounding box predictions and class predictions.
What are the 'depth multiple', 'width multiple', and 'max channels' parameters in YOLOv8?
-The 'depth multiple' parameter determines the number of bottleneck blocks in the C2F block. The 'width multiple' and 'max channels' parameters control the output channel sizes, with the width multiple scaling the output based on the base output channel and max channels providing an upper limit.
What is the purpose of padding in YOLOv8's convolutional operations?
-Padding in YOLOv8 is used to add values around the input image to ensure that the convolutional process doesn't reduce the spatial dimensions too much. There are different types of padding, such as zero-padding (default) and replication padding, which extends edge values.
How does the upsampling and concatenation (concatenate) operations work in YOLOv8?
-The upsampling operation increases the resolution of feature maps, which are then combined with feature maps from previous layers using concatenation (concapt). The concatenation sums the channels of the two feature maps without changing the resolution.
What is the role of the detect block in YOLOv8?
-The detect block in YOLOv8 is where object detection takes place. It specializes in predicting bounding boxes and class labels for objects. YOLOv8 has three separate detect blocks that focus on detecting small, medium, and large objects, respectively.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

YOLOv10 Architecture Explained - A Complete Breakdown

YOLO11 Architecture - Detailed Explanation

Learn CSS BEM (and avoid these common mistakes)

FPGA Architecture | Configurable Logic Block ( CLB ) | Part-1/2 | VLSI | Lec-75

Fabric Modding Tutorial - Minecraft 1.20: Custom Loot Tables | #5
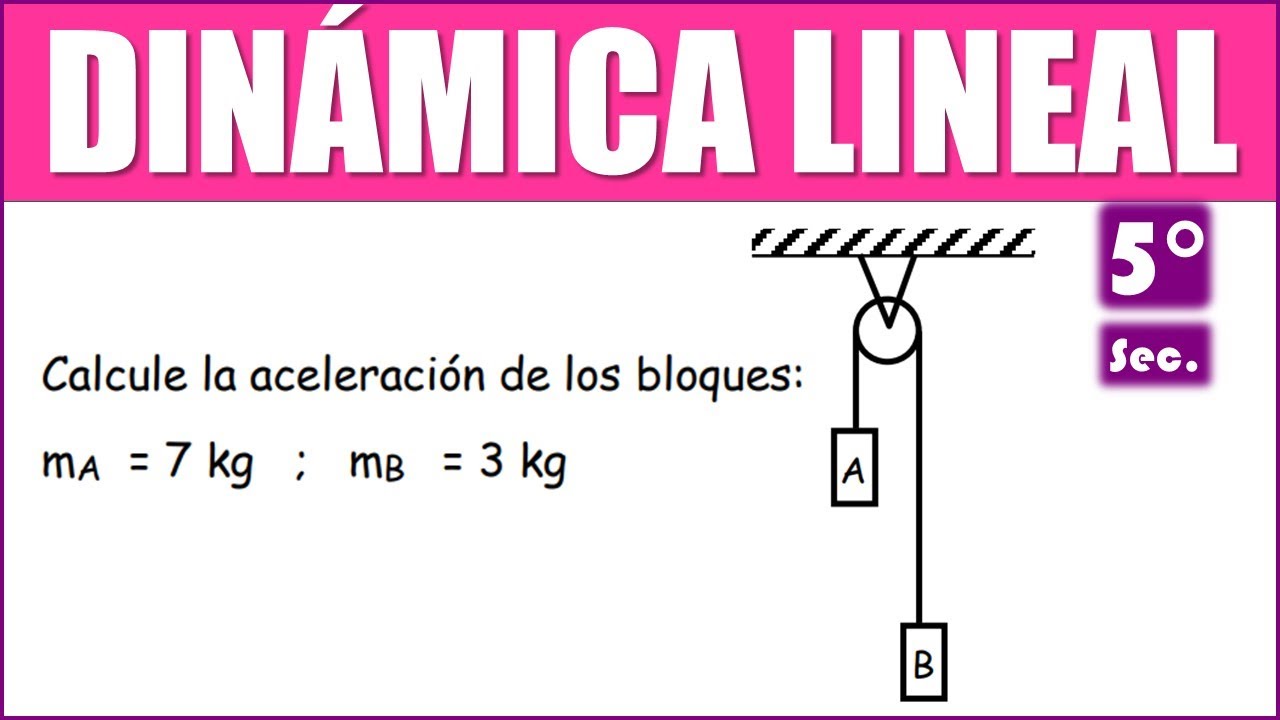
Calcule la aceleración de los bloques: mA = 7 kg ; mB = 3 kg
5.0 / 5 (0 votes)