Training Data Vs Test Data Vs Validation Data| Krish Naik
Summary
TLDRThis YouTube video script discusses the critical concepts of training, validation, and test data in machine learning. It aims to clarify the confusion around these terms and their applications. The video uses examples, such as regression and classification problems, to explain the process of data preprocessing, feature engineering, and model training. It also covers hyperparameter tuning and the importance of using validation data to optimize model performance before testing with unseen data.
Takeaways
- 😀 The video is aimed at discussing the differences between training, validation, and test data sets in machine learning.
- 🔍 The script emphasizes the confusion many people face regarding when to use training, test, and validation data.
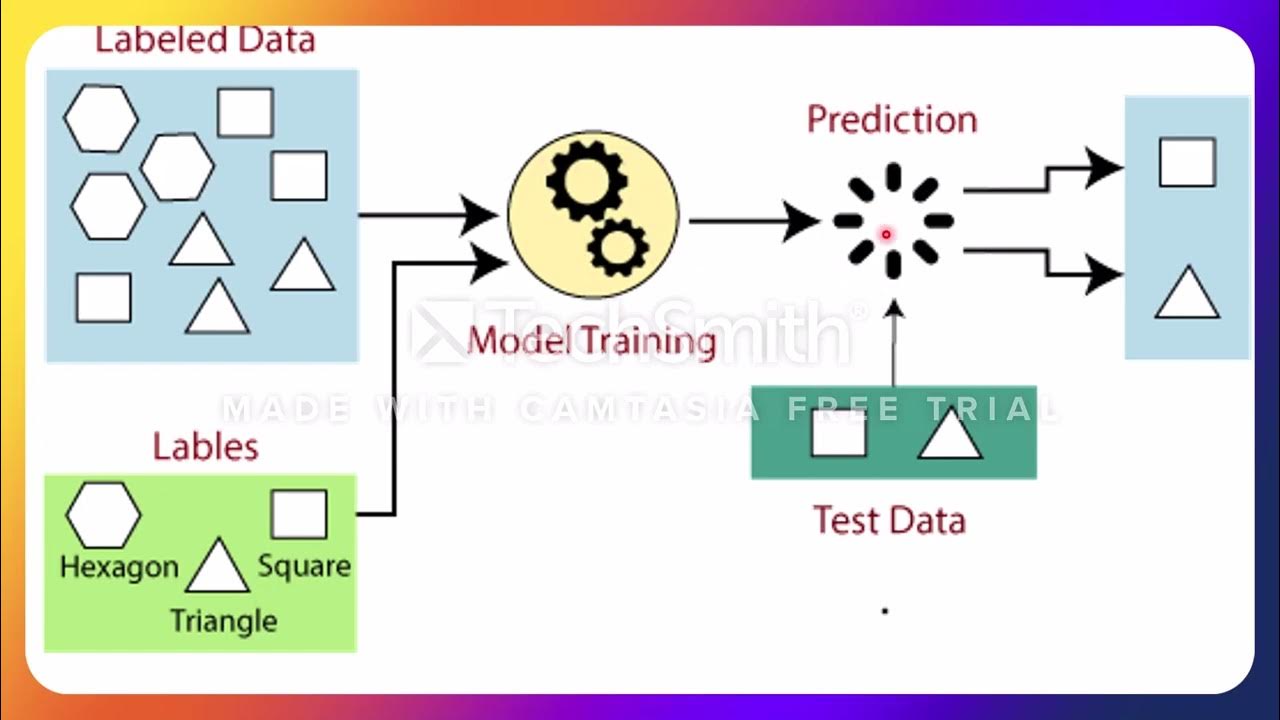
- 📈 It explains that training data is used to fit the model, test data is used to evaluate the model's performance on unseen data, and validation data is used for tuning hyperparameters.
- 🎯 The importance of preprocessing and feature engineering before model training is highlighted.
- 🔧 The script introduces the concept of splitting data into training and test sets, with a focus on the remaining data being used for validation.
- 📝 The video mentions that validation data helps in hyperparameter tuning and is crucial for avoiding overfitting.
- 🔄 Cross-validation is introduced as a method for model evaluation, which involves dividing the training data into 'k' folds for validation.
- 📊 The script explains that the performance of a model is assessed using various metrics, such as accuracy and confusion matrices.
- 🌐 The video also touches on the importance of feature selection and how it can impact model training and performance.
- 🔗 Lastly, the script encourages viewers to subscribe to the YouTube channel for more informative content on machine learning and data science.
Q & A
What is the primary focus of this video?
-The video focuses on explaining the difference between training, validation, and test datasets in machine learning, and how to use them effectively during model development.
What are the key types of problems in machine learning mentioned in the video?
-The video mentions two primary types of problems in machine learning: regression and classification, both of which are used in supervised learning.
What is the purpose of the training dataset?
-The training dataset is used to train the machine learning model. It helps the model learn patterns in the data by fitting the model to the provided features and outcomes.
When should the test dataset be used?
-The test dataset should be used after the model has been trained to evaluate its performance on unseen data. This helps assess the model's accuracy and generalization capability.
How does the validation dataset help in model development?
-The validation dataset is used during the hyperparameter tuning process. It helps optimize the model by allowing adjustments to be made before final testing, ensuring better performance.
What is cross-validation, and why is it important?
-Cross-validation is a technique where the training data is split into multiple subsets to train and validate the model on different portions of the data. It helps improve model reliability by ensuring the model's performance is consistent across different data samples.
What is the key difference between training, validation, and test datasets?
-The training dataset is used for learning patterns, the validation dataset is for tuning hyperparameters, and the test dataset is for evaluating the final model performance.
How is overfitting detected in machine learning models?
-Overfitting is detected when the model performs well on the training data but poorly on the test data. This indicates that the model has memorized the training data instead of generalizing well.
What is the significance of performance metrics like confusion matrix and recall?
-Performance metrics like the confusion matrix and recall are used to evaluate the accuracy, precision, and robustness of a model's predictions, especially in classification tasks.
What is hyperparameter tuning, and how does it affect the model?
-Hyperparameter tuning involves adjusting the model's settings (like learning rate, number of layers, etc.) to improve its performance. Proper tuning helps the model achieve better accuracy and generalization.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

Key Machine Learning terminology like Label, Features, Examples, Models, Regression, Classification

K Fold Cross Validation | Cross Validation in Machine Learning

Hindi-Types Of Cross Validation In Machine Learning|Krish Naik
L8 Part 02 Jenis Jenis Learning

Batch Machine Learning | Offline Vs Online Learning | Machine Learning Types

AI: Training Data & Bias
5.0 / 5 (0 votes)
