Hindi-Types Of Cross Validation In Machine Learning|Krish Naik
Summary
TLDRIn this video, the host introduces various types of data validation techniques used in machine learning, emphasizing their importance in model training and interview preparation. The discussion covers methods like leave-one-out cross-validation, hold-out cross-validation, fold cross-validation, stratified cross-validation, and time-series validation. The host explains the significance of each method and its potential disadvantages, such as time consumption and overfitting. Practical examples and tips are provided, making the video highly informative for viewers looking to strengthen their understanding of validation techniques in machine learning.
Takeaways
- 😀 Data science and machine learning require a clear understanding of various concepts, such as types of pollution, for successful implementation.
- 😀 It's important to know about different types of pollution as they are common interview questions in the field of data science.
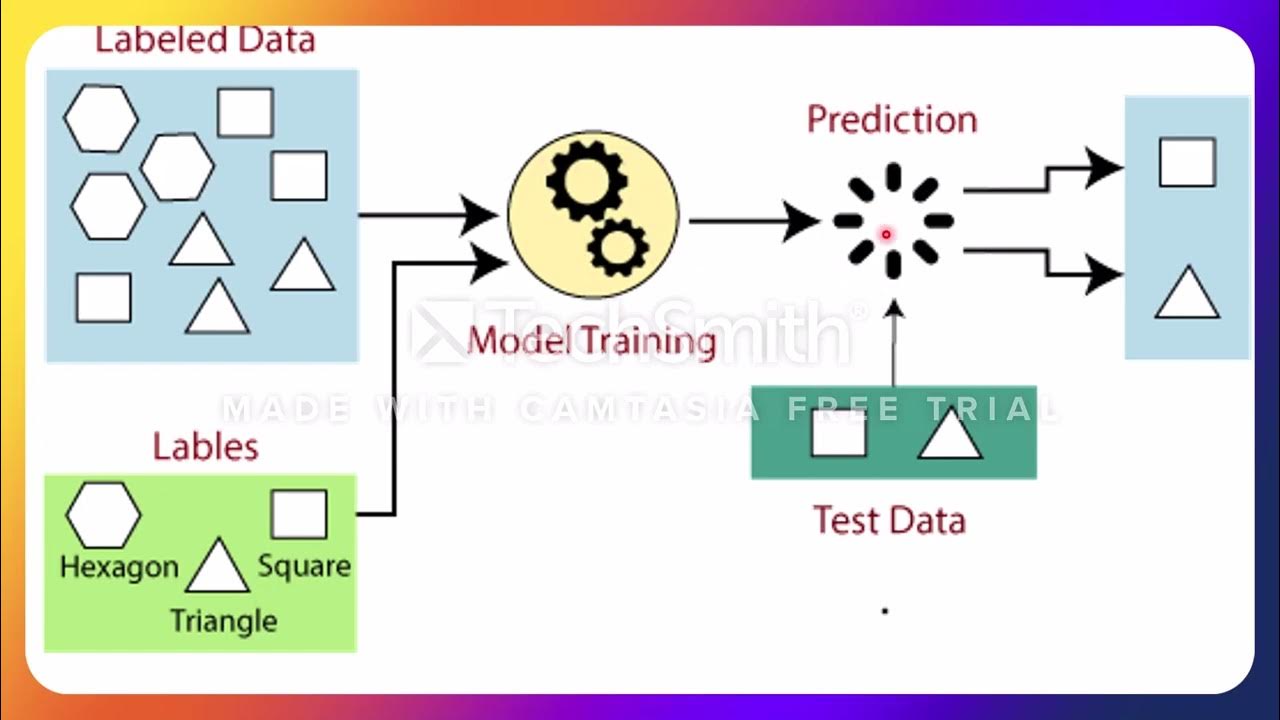
- 😀 The process of dividing data into training and validation datasets is crucial for building effective machine learning models.
- 😀 Cross-validation is a method used to ensure that the model is trained on different parts of the dataset and validated to prevent overfitting.
- 😀 Holdout cross-validation involves dividing data into training and validation sets, where data points are selected randomly, ensuring diverse training scenarios.
- 😀 The fold cross-validation method divides the dataset into several folds and uses each fold as the validation set at some point, improving the accuracy of results.
- 😀 Stratified K-Fold cross-validation ensures that each fold contains a balanced proportion of all categories, which is important when dealing with imbalanced datasets.
- 😀 Time series cross-validation is particularly useful for data where the sequence of events matters, such as forecasting, and requires validation based on chronological order.
- 😀 The main advantage of fold cross-validation is that it helps in averaging the model's performance across different data subsets, reducing bias and variance.
- 😀 Time series validation cannot use random data splits, as it's essential to maintain the order of the data to simulate real-world prediction scenarios effectively.
Q & A
What is the importance of understanding different types of pollution in machine learning?
-Understanding different types of pollution is crucial in machine learning because it helps in identifying and handling potential data issues. This knowledge also aids in improving the accuracy of models and helps with practical problem-solving during data science tasks, such as cleaning and preprocessing data.
What is the significance of cross-validation in machine learning?
-Cross-validation is a critical technique used to evaluate the performance of a model. It helps prevent overfitting by using different subsets of data for training and testing, ensuring that the model generalizes well to unseen data.
What is the concept of 'leave-one-out cross-validation' (LOO CV)?
-In leave-one-out cross-validation (LOO CV), the model is trained on all the data points except one, which is used for testing. This process is repeated for each data point, and the results are averaged. While it is effective, LOO CV is time-consuming and prone to overfitting.
What are the main disadvantages of leave-one-out cross-validation?
-The main disadvantages of LOO CV are its time-consuming nature, especially with large datasets, and its tendency to overfit. Since only one data point is used for validation at a time, the model may have a skewed view of its performance.
What does 'hold-out cross-validation' mean?
-Hold-out cross-validation involves splitting the dataset into a training set and a test set. A percentage of the data is used for training, while the remaining portion is used for testing. This method is simpler but may not fully utilize the available data for training and validation.
What is the purpose of random splitting in hold-out cross-validation?
-Random splitting ensures that the training and validation sets are selected randomly, helping avoid bias and making the model evaluation more reliable. However, care must be taken to ensure balanced data distribution, especially in imbalanced datasets.
How does k-fold cross-validation work?
-In k-fold cross-validation, the dataset is divided into 'k' equal parts. The model is trained on 'k-1' parts and tested on the remaining part. This process is repeated 'k' times, with each subset being used as the test set once. The results are averaged to get a final performance score.
What is the benefit of using k-fold cross-validation over other methods?
-K-fold cross-validation provides a more reliable estimate of model performance because each data point is used for both training and testing. It reduces the risk of overfitting and gives a better understanding of how the model will perform on unseen data.
What is stratified k-fold cross-validation?
-Stratified k-fold cross-validation ensures that each fold in the cross-validation process has an equal distribution of classes, particularly in imbalanced datasets. This technique helps prevent bias and ensures that the model performs consistently across all classes.
How does time series cross-validation differ from other cross-validation methods?
-Time series cross-validation accounts for the temporal order of data. Unlike random sampling in other methods, time series validation splits the data sequentially, using earlier data for training and later data for validation. This is crucial for forecasting models where the future depends on past data.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Machine Learning Interview Questions 2024 | ML Interview Questions And Answers 2024 | Simplilearn

End to End ML Project 1 - P1 - Problem Statement and Solution Design
L8 Part 02 Jenis Jenis Learning

K Fold Cross Validation | Cross Validation in Machine Learning

Training Data Vs Test Data Vs Validation Data| Krish Naik
Data analysis and visualization
5.0 / 5 (0 votes)