Intro to Databricks Lakehouse Platform Architecture and Security
Summary
TLDRThe video script delves into the architecture and security fundamentals of Databricks' Lakehouse platform, emphasizing the significance of data reliability and performance. It introduces Delta Lake, an open-source storage format that ensures ACID transactions and schema enforcement, and Photon, a next-gen query engine for cost-effective performance. The script also covers unified governance and security structures, including Unity Catalog for data governance and Delta Sharing for secure data exchange. Additionally, it highlights the benefits of serverless compute for on-demand, scalable data processing, and introduces key Lakehouse data management terminology.
Takeaways
- 📈 **Data Reliability and Performance**: The importance of having reliable and clean data for accurate business insights and conclusions is emphasized, as bad data leads to bad outcomes.
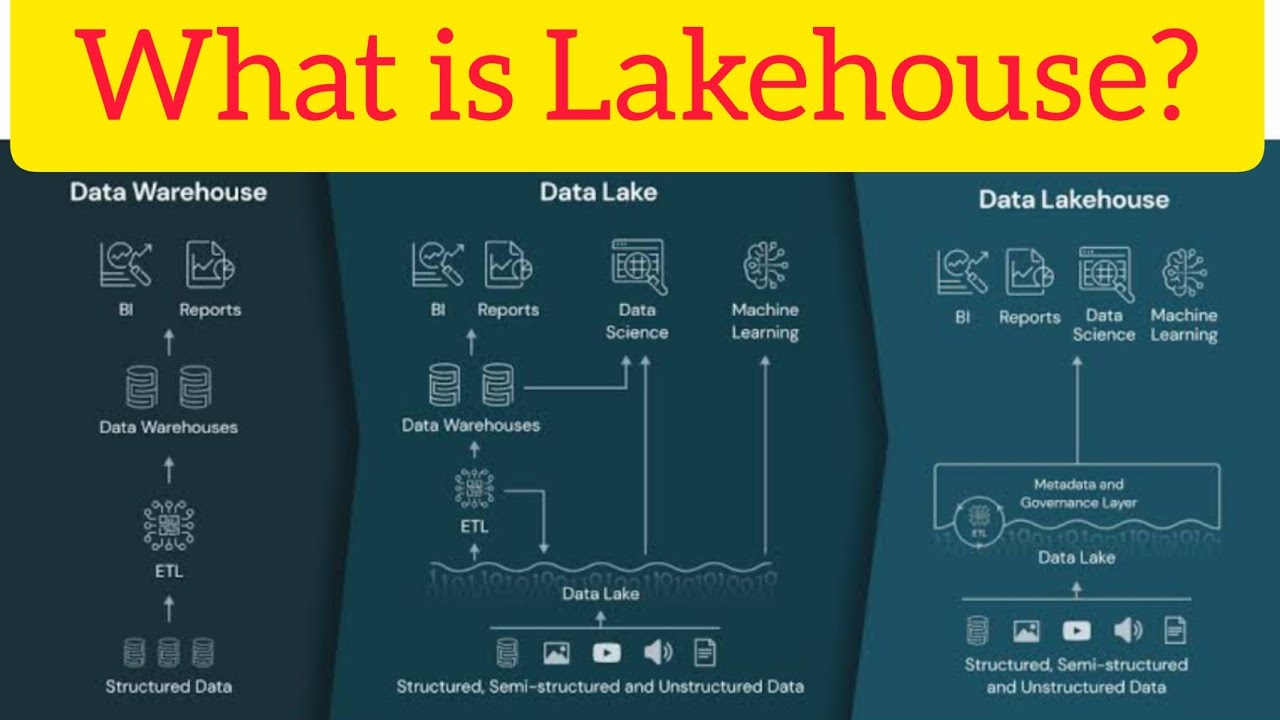
- 💧 **Data Lakes vs. Data Swamps**: Data lakes are great for storing raw data but often lack features for data reliability and quality, sometimes leading to them being referred to as data swamps.
- 🚀 **Performance Issues with Data Lakes**: Data lakes may not perform as well as data warehouses due to issues like lack of ACID transaction support, schema enforcement, and integration with data catalogs.
- 🔒 **Delta Lake**: Delta Lake is an open-source storage format that addresses the reliability and performance issues of data lakes by providing ACID transactions, scalable metadata handling, and schema enforcement.
- 🛠️ **Photon Query Engine**: Photon is a next-generation query engine designed to provide the performance of a data warehouse with the scalability of a data lake, offering significant infrastructure cost savings.
- 🌐 **Compatibility and Flexibility**: Delta Lake runs on top of existing data lakes and is compatible with Apache Spark and other processing engines, providing flexibility for data management infrastructure.
- 🔑 **Unified Governance and Security**: The importance of a unified governance and security structure is highlighted, with features like Unity Catalog, Delta Sharing, and the separation of control and data planes.
- 🔄 **Data Sharing with Delta Sharing**: Delta Sharing is an open-source solution for securely sharing live data across platforms, allowing for centralized administration and governance of data.
- 🛡️ **Security Structure**: The Databricks Lakehouse platform offers a simple and unified approach to data security by splitting the architecture into control and data planes, ensuring data stays secure and compliant.
- 🌟 **Serverless Compute**: Serverless compute is a fully managed service that simplifies the process of setting up and managing compute resources, reducing costs and increasing productivity.
Q & A
Why is data reliability and performance important in the context of a data platform architecture?
-Data reliability and performance are crucial because they ensure that the data used for business insights and decision-making is accurate and clean. Poor data quality can lead to incorrect conclusions, and performance issues can slow down data processing and analysis.
What are some of the common issues with data lakes that can affect data reliability and performance?
-Data lakes often lack features for data reliability and quality, such as ACID transaction support, schema enforcement, and integration with a data catalog, leading to data swamps and issues like the small file problem, ineffective partitioning, and high cardinality columns that degrade query performance.
What is Delta Lake and how does it address the issues associated with data lakes?
-Delta Lake is a file-based open-source storage format that provides ACID transaction guarantees, scalable data and metadata handling, audit history, schema enforcement, and support for deletes, updates, and merges. It runs on top of existing data lakes and is compatible with Apache Spark and other processing engines.
How does Photon improve the performance of the Databricks Lakehouse platform?
-Photon is a next-generation query engine that provides significant infrastructure cost savings and performance improvements. It is compatible with Spark APIs and offers increased speed for data ingestion, ETL, streaming, data science, and interactive queries directly on the data lake.
What are the benefits of using Delta tables over traditional Apache Parquet tables?
-Delta tables, based on Apache Parquet, offer additional features such as versioning, reliability, metadata management, and time travel capabilities. They provide a transaction log that ensures multi-user environments have a single source of truth and prevent data corruption.
What is Unity Catalog and how does it contribute to data governance in the Databricks Lakehouse platform?
-Unity Catalog is a unified governance solution for all data assets. It provides fine-grained access control, SQL query auditing, attribute-based access control, data versioning, and data quality constraints. It offers a common governance model across clouds, simplifying permissions and reducing risk.
What is Delta Sharing and how does it facilitate secure data sharing across platforms?
-Delta Sharing is an open-source solution for sharing live data from the Lakehouse to any computing platform securely. It allows data providers to maintain governance and track usage, enabling centralized administration and secure collaboration without data duplication.
How does the security structure of the Databricks Lakehouse platform ensure data protection?
-The security structure splits the architecture into a control plane and a data plane. The control plane manages services in Databrick's cloud account, while the data plane processes data in the business's cloud account. Data is encrypted at rest and in transit, and access is tightly controlled and audited.
What is the serverless compute option in Databricks and how does it benefit users?
-Serverless compute is a fully managed service where Databricks provisions and manages compute resources. It offers immediate environment startup, scaling up and down within seconds, and resource release after use, reducing total cost of ownership and admin overhead while increasing user productivity.
What are the key components of Unity Catalog's data object hierarchy?
-The key components of Unity Catalog's data object hierarchy include the metastore, catalog, schema, table, view, and user-defined function. The metastore is the logical container for metadata, the catalog is the topmost container for data objects, and schemas, tables, views, and functions are used to organize and manage data.
What is the purpose of the three-level namespace introduced by Unity Catalog?
-The three-level namespace introduced by Unity Catalog provides improved data segregation capabilities. It consists of the catalog, schema, and table/view/function levels, allowing for more granular and organized data management compared to the traditional two-level namespace.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

02 What is Data Lakehouse & Databricks Data Intelligence Platform | Benefits of Databricks Lakehouse

Intro To Databricks - What Is Databricks

Intro to Databricks Lakehouse Platform

Intro to Supported Workloads on the Databricks Lakehouse Platform
What is Lakehouse Architecture? Databricks Lakehouse architecture. #databricks #lakehouse #pyspark

Data Federation with Unity Catalog
5.0 / 5 (0 votes)
