Hash Tables
Summary
TLDRThis video explains fundamental data structures, focusing on arrays, linked lists, and hash tables. It highlights the advantages of arrays, such as random access but fixed size, and compares them to linked lists, which offer dynamic growth at the cost of slower lookups. The video dives into hash tables, discussing their efficiency for insertion, deletion, and lookup in constant time, but also addresses potential collisions and methods like linear probing and separate chaining to resolve them. Finally, it emphasizes the importance of crafting efficient hash functions to minimize collisions and improve performance.
Takeaways
- 😀 Arrays allow random access to elements, but their size is fixed, making them less flexible for growth.
- 😀 Linked lists can grow dynamically, but accessing an element requires traversal, which can be inefficient (O(n)).
- 😀 Hash tables offer a solution with faster insertion, deletion, and lookup operations, potentially in constant time (O(1)).
- 😀 A hash table is an array combined with a hash function that maps keys to specific indices in the table.
- 😀 The hash function is crucial, as it needs to consistently output the same hash value for identical keys.
- 😀 Collisions occur when two keys hash to the same index. They must be handled for a hash table to function correctly.
- 😀 Linear probing is a collision resolution method where the next available index is chosen, but clustering can degrade performance.
- 😀 Separate chaining resolves collisions by storing elements in linked lists at each index, which can still lead to O(n/k) lookup time in the worst case.
- 😀 Good hash functions should use all information in the key to minimize collisions and ensure an even distribution of hash values.
- 😀 A well-designed hash function should be simple and fast to minimize the computational cost during insertions, deletions, and lookups.
Q & A
What is the primary advantage of using arrays in data structures?
-Arrays provide random access to elements, meaning you can access any element in constant time by using its index. This is beneficial for algorithms like binary search that rely on quick access.
What is a significant limitation of arrays compared to other data structures?
-Arrays have a fixed size, meaning once you declare the array, its size cannot be changed. This limits their ability to grow dynamically based on the need for more memory.
How do linked lists differ from arrays in terms of memory storage?
-Linked lists store elements dynamically in memory, with each node containing an element and a pointer to the next node. This allows linked lists to grow easily, unlike arrays that require contiguous memory.
What is the major disadvantage of linked lists?
-Linked lists do not offer random access to elements. To find a specific element, you have to traverse the list from the beginning, making lookup operations inefficient with a time complexity of O(n).
What problem does a hash table solve that arrays and linked lists cannot?
-Hash tables offer fast insertion, deletion, and lookup of elements, potentially achieving constant time complexity (O(1)) for these operations, which is a significant improvement over arrays and linked lists.
What is a hash table and how does it work?
-A hash table is an array paired with a hash function. The hash function takes a key and generates a hash value that maps to a specific index in the hash table. This allows fast access, insertion, and deletion based on the key.
How does a hash function contribute to the efficiency of a hash table?
-The hash function maps a key to a specific index in the hash table. A good hash function ensures that the keys are spread evenly across the table, reducing the likelihood of collisions and ensuring fast operations.
What is a collision in the context of hash tables, and how does it occur?
-A collision occurs when two different keys hash to the same index in the hash table. For example, both 'apple' and 'ant' might hash to the same index, requiring a method to handle the conflict.
What are the two common methods for resolving collisions in hash tables?
-The two common methods for resolving collisions are linear probing, where the next available slot is used, and separate chaining, where each index points to a linked list to store multiple keys.
How does separate chaining handle collisions differently from linear probing?
-In separate chaining, when a collision occurs, the key is inserted at the head of a linked list at the corresponding index. This allows multiple keys to be stored in the same table slot without causing clustering, unlike linear probing.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados
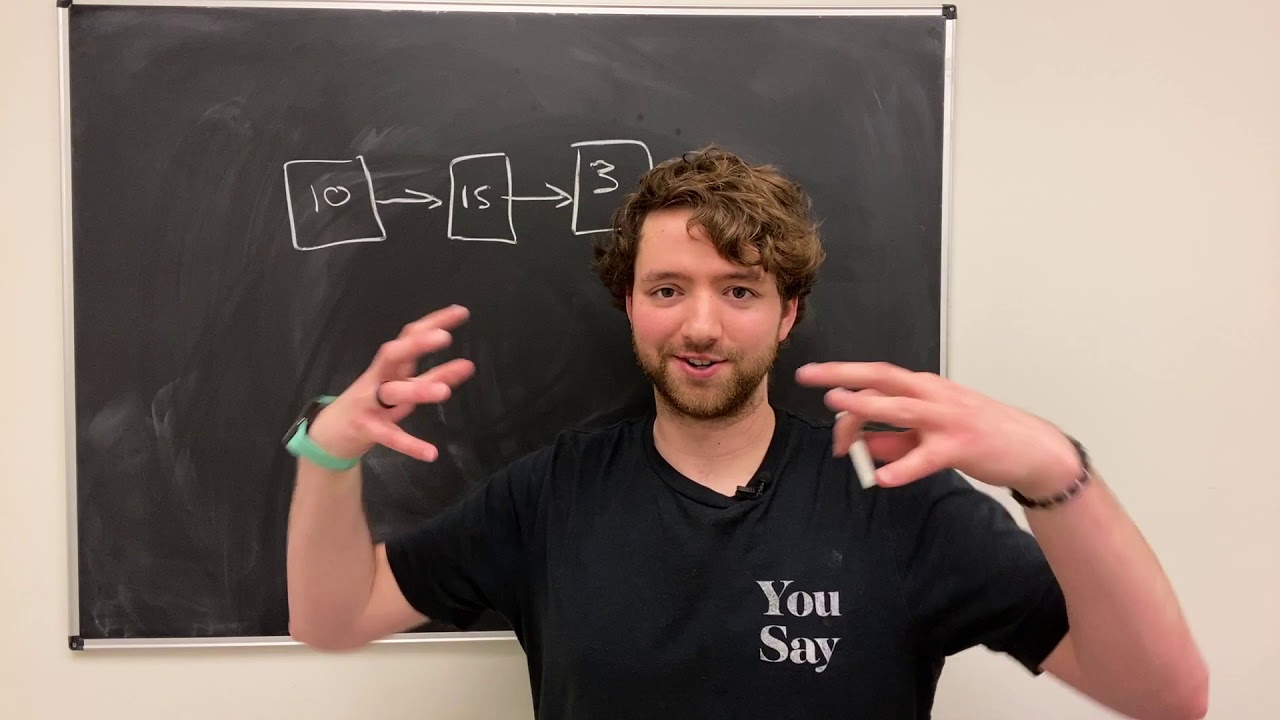
Arrays vs Linked Lists - Data Structures and Algorithms

STRUKTUR DATA dalam PEMROGRAMAN

AQA A’Level Hash tables - Part 1

Roadmap 🛣️ of DSA | Syllabus of Data structure | Data Structure for Beginners

Top 7 Data Structures for Interviews Explained SIMPLY

161. OCR A Level (H446) SLR26 - 2.3 Comparison of the complexity of algorithms
5.0 / 5 (0 votes)
