Linear Regression, Cost Function and Gradient Descent Algorithm..Clearly Explained !!
Summary
TLDRThis video introduces linear regression, a fundamental machine learning model used to predict outputs based on input features. It explains the concept of a model in data science, the importance of understanding and predicting real-world processes, and how linear regression works with a single feature. The video also covers multiple feature linear regression, the cost function, and the gradient descent algorithm for finding the best model parameters. It concludes with practical insights on implementing linear regression in Python and the significance of the learning rate as a hyperparameter.
Takeaways
- 🧠 A model in data science is a mathematical representation of a real-world process, focusing on the relationship between inputs and outputs.
- 🔮 Models are valuable for understanding processes and predicting outcomes based on input features, which can have significant economic benefits.
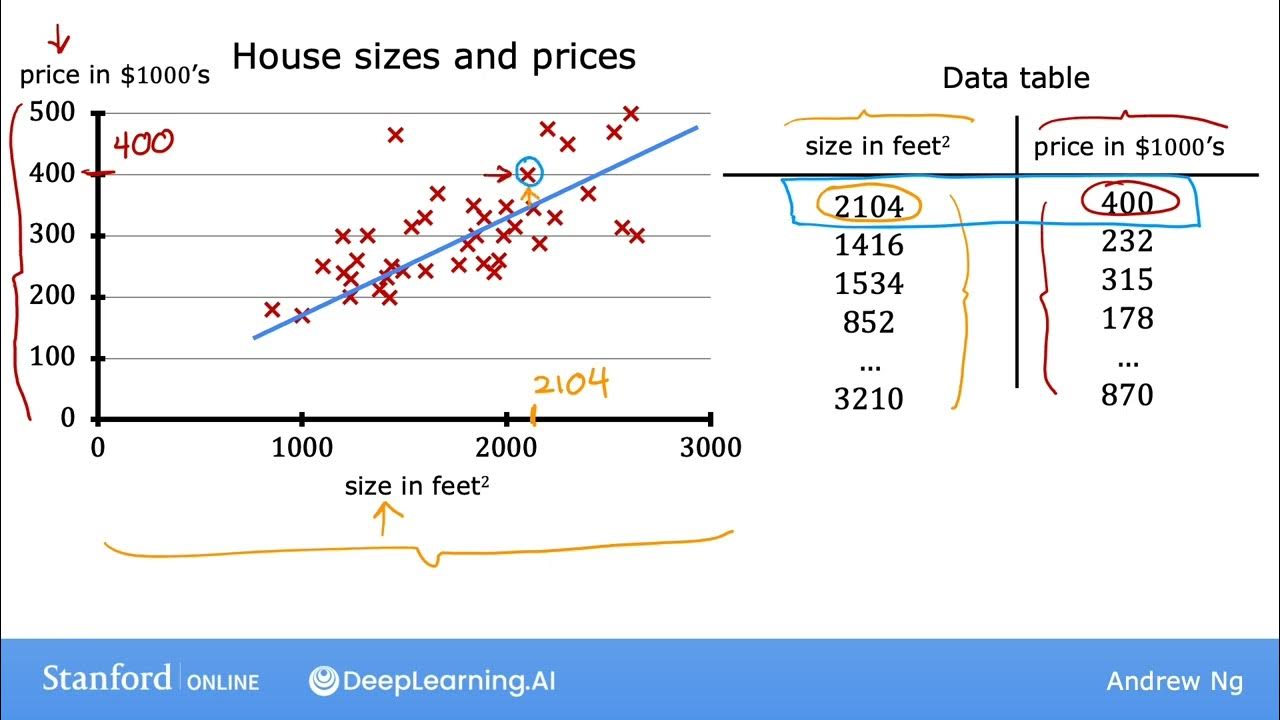
- 🏠 The example of house size predicting its price illustrates the use of a simple linear model where input (size) determines output (price).
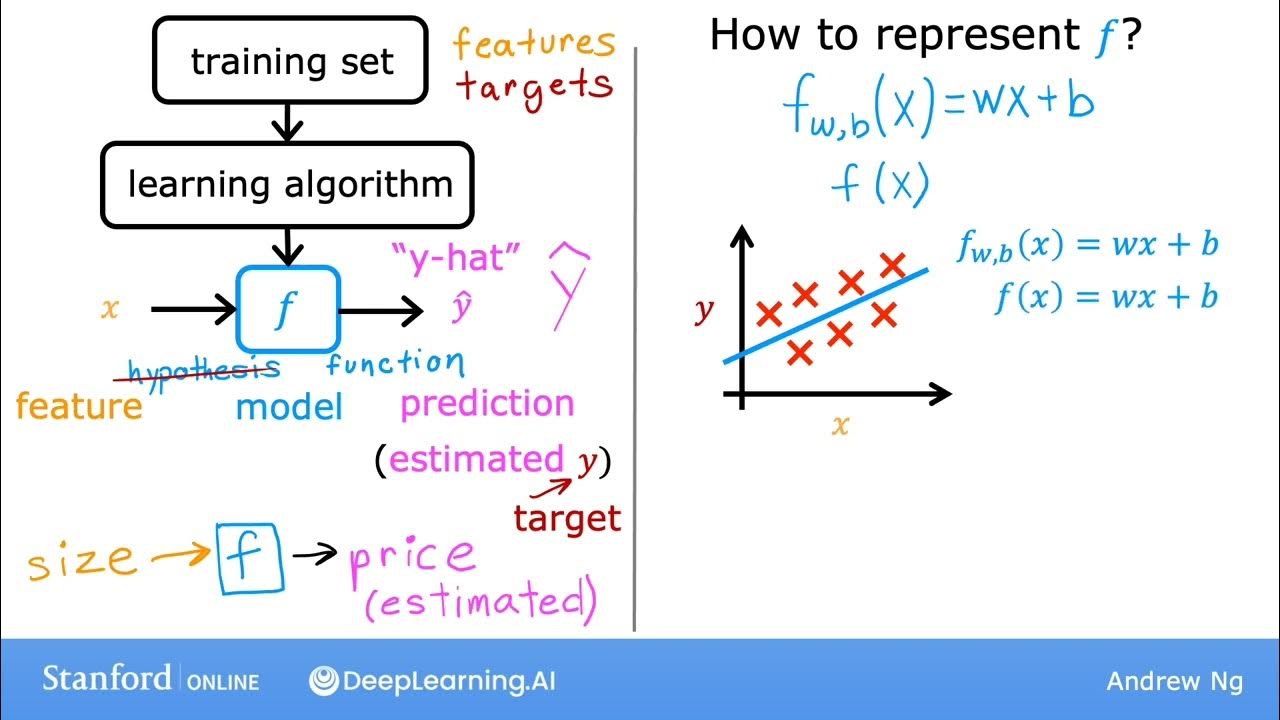
- 📊 Linear regression is introduced as a method to find a linear relationship between input features and an output variable, represented graphically on a coordinate plane.
- 🔢 The equation of a linear relationship is expressed as y = a0 + a1*x, where y is the output, x is the input feature, and a0 and a1 are model parameters.
- 📈 For multiple features, the linear equation extends to y = a0 + a1*x1 + a2*x2 + ... + an*xn, with each xi representing a feature and ai the corresponding model parameter.
- 📉 The cost function, derived from the sum of squared errors (SSE), is used to measure how well the model fits the data and guides the model parameter adjustments.
- 🔍 The gradient descent algorithm is employed to minimize the cost function by iteratively adjusting model parameters based on the slope (derivative) of the cost function.
- 🔄 The learning rate (alpha) in gradient descent determines the size of the steps taken towards the minimum of the cost function, requiring careful tuning to ensure convergence.
- 💻 Linear regression models can be implemented in Python with libraries that abstract the complex mathematics, allowing for efficient model training and prediction.
Q & A
What is a model in the context of data science?
-In data science, a model is a mathematical representation of a real-world process, characterized by an input-output relationship.
Why are models important in data science?
-Models are important because they help us understand the nature of the process being modeled and enable us to predict outputs based on input features, which has significant economic value.
What is linear regression and why is it significant?
-Linear regression is a machine learning model used to establish a linear relationship between a dependent variable and one or more independent variables. It's significant because it provides a simple and effective way to predict outcomes based on input features.
How is the relationship between house size and price represented in linear regression?
-In linear regression, the relationship between house size (input) and price (output) is represented as a straight line on a graph, where the x-axis represents the size of the house and the y-axis represents the price.
What are the model parameters in a simple linear regression model?
-In a simple linear regression model, the model parameters are 'a naught' (intercept) and 'a1' (coefficient), which define the equation of the line as 'y = a naught + a1 * x'.
How does the cost function in linear regression work?
-The cost function in linear regression measures the difference between the predicted values and the actual values. It is typically represented as the sum of the squares of the differences (errors) between predicted and actual values, divided by the number of examples (m).
What is the purpose of the gradient descent algorithm in linear regression?
-The gradient descent algorithm is used to minimize the cost function in linear regression by iteratively adjusting the model parameters (a naught and a1) to find the values that result in the lowest cost.
How does the learning rate (alpha) affect the gradient descent process?
-The learning rate (alpha) determines the size of the steps taken towards the minimum of the cost function during each iteration of gradient descent. A higher learning rate can lead to faster convergence but might cause the algorithm to overshoot the minimum, while a lower learning rate ensures a more stable convergence but may slow down the process.
What is the role of the error term in the cost function?
-The error term (e) in the cost function represents the difference between the actual value and the predicted value for each training example. It is used to calculate the cost, which is then minimized through the gradient descent process.
How can linear regression be extended to handle multiple features?
-Linear regression can be extended to handle multiple features by including additional terms in the equation, each multiplied by its respective feature (x1, x2, ..., xn) and coefficient (a1, a2, ..., an), allowing the model to capture more complex relationships.
What is the significance of the intercept (a naught) in a linear regression model?
-The intercept (a naught) in a linear regression model represents the expected value of the dependent variable when all the independent variables are set to zero. It helps to position the regression line on the y-axis.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados
#10 Machine Learning Specialization [Course 1, Week 1, Lesson 3]
#9 Machine Learning Specialization [Course 1, Week 1, Lesson 3]

Key Machine Learning terminology like Label, Features, Examples, Models, Regression, Classification

Different Types of Learning

Bayesian Estimation in Machine Learning - Introduction and Examples

GEOMETRIC MODELS ML(Lecture 7)
5.0 / 5 (0 votes)
