METODE CLUSTERING-SINGLE LINKAGE
Summary
TLDRThe lecture introduces hierarchical clustering using the single linkage algorithm, contrasting it with k-means by highlighting that the number of clusters is determined at the end rather than at the start. It explains key concepts such as distance measurement, standard deviation, and Z-score standardization. A practical case study using song data demonstrates step-by-step calculations: data transformation, distance matrix creation, and iterative merging of clusters based on the smallest distances. The session emphasizes careful data preparation, numerical conversion of categorical variables, and proper application of clustering steps to group similar objects, ultimately producing meaningful clusters for analysis.
Takeaways
- 😀 The session introduces hierarchical clustering using the single linkage algorithm, focusing on grouping similar objects based on proximity.
- 😀 Single linkage clustering determines the number of clusters at the end of the process, unlike K-Means which requires pre-defined cluster counts.
- 😀 Hierarchical clustering has three main approaches: single linkage (closest distance), complete linkage (farthest distance), and average linkage (average distance).
- 😀 Key steps in the algorithm include calculating the mean, standard deviation, and Z-scores for data normalization.
- 😀 Proximity or similarity between objects is measured using distance metrics like Euclidean, Manhattan, or Pearson distance.
- 😀 Objects and variables are organized into a table format, where objects are rows and variables are columns for systematic analysis.
- 😀 Non-numeric (nominal) data is transformed into numeric values to allow distance calculations in clustering.
- 😀 A distance matrix is created to represent pairwise distances between objects, with diagonal entries (distance to self) being zero and excluded from clustering decisions.
- 😀 Iterative merging is performed by identifying the smallest non-zero distance, combining objects into clusters, and updating the distance matrix until final clusters emerge.
- 😀 A practical example uses songs as objects with variables like playtime, country of origin, and genre to illustrate the clustering process step by step.
- 😀 The final clusters represent groups of objects with the highest similarity, useful for analyzing preferences or patterns in datasets.
- 😀 Proper data preparation and assumption assignment are essential for meaningful clustering outcomes, especially when handling categorical data.
Q & A
What is the main difference between k-means clustering and single linkage hierarchical clustering?
-In k-means clustering, the number of clusters is determined at the start, while in single linkage hierarchical clustering, the number of clusters is determined at the end of the calculation based on data similarity.
Why is single linkage clustering also called hierarchical clustering?
-It is called hierarchical clustering because it builds a hierarchy of clusters by successively merging the closest objects or clusters until all objects are grouped.
What are the three common methods of hierarchical clustering mentioned?
-The three common methods are single linkage (nearest distance), complete linkage (farthest distance), and average linkage (average distance between all points in clusters).
What is the purpose of calculating the mean and standard deviation in clustering?
-Calculating the mean and standard deviation allows for standardizing the data (using Z-scores), which ensures that variables with different scales are comparable in measuring distances between objects.
How is the Z-score calculated according to the transcript?
-The Z-score is calculated as Zᵢ = (xᵢ − x̄) / SD, where xᵢ is the data point, x̄ is the mean of the data, and SD is the standard deviation.
What formula is suggested for calculating the distance between objects?
-The Euclidean distance formula is suggested: d(i,j) = √Σ(xᵢ − xⱼ)². Alternatives like Manhattan distance or Pearson correlation can also be used depending on the context.
What is a distance matrix and how is it used in single linkage clustering?
-A distance matrix is a table that records the distances between each pair of objects. It is used to identify the closest objects or clusters to merge at each step of the hierarchical clustering process.
Why is the zero distance on the diagonal of the distance matrix ignored during clustering?
-The zero distance represents the distance of an object to itself, which is always zero and not meaningful for clustering, so it is ignored in finding the closest objects to merge.
How is the iterative merging process carried out in single linkage clustering?
-The smallest non-zero distance in the distance matrix is identified, the corresponding objects are merged into a new cluster, and distances between this new cluster and all other objects are recalculated. This is repeated until all objects are clustered.
What types of data were used in the example case study?
-The case study used songs as objects and considered three variables: time of play (morning, afternoon, evening, night), country of origin, and genre of music.
Why is data transformation necessary before applying clustering algorithms?
-Data transformation is necessary because clustering algorithms typically require numerical input. Nominal or categorical data must be converted to numeric form to calculate distances and similarities between objects.
What is the final output of the single linkage clustering process?
-The final output is the assignment of objects into clusters based on their similarity. Each object belongs to a cluster, and clusters can be analyzed or visualized to understand patterns or relationships in the data.
Outlines

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenMindmap

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenKeywords

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenHighlights

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenTranscripts

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführen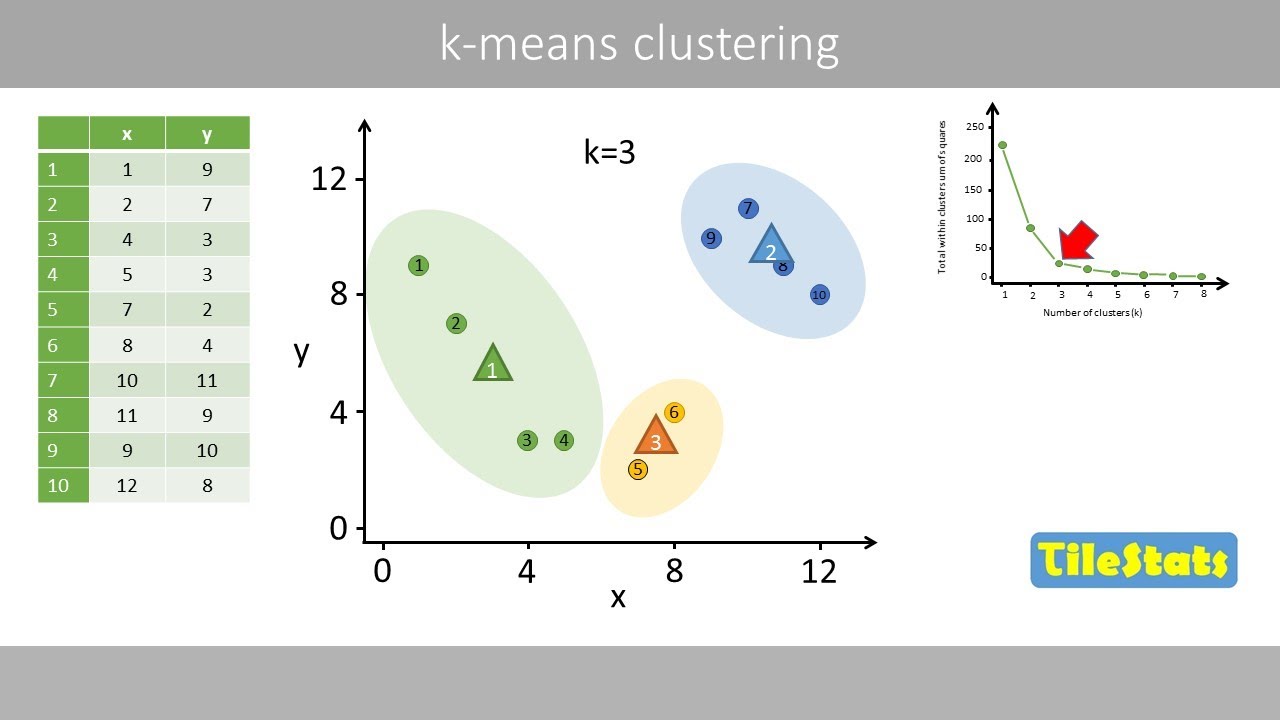



5.0 / 5 (0 votes)
