DE Zoomcamp 1.2.1 - Introduction to Docker
Summary
TLDRThe video introduces docker, explaining key concepts like containers and isolation to demonstrate why docker is useful for data engineers. It walks through examples of running different docker containers locally to showcase reproducibility across environments and support for local testing and integration. The presenter sets up a basic python data pipeline docker container, parameters it to process data for a specific day, and previews connecting it to a local postgres database in the next video to load the New York Taxi dataset for SQL practice.
Takeaways
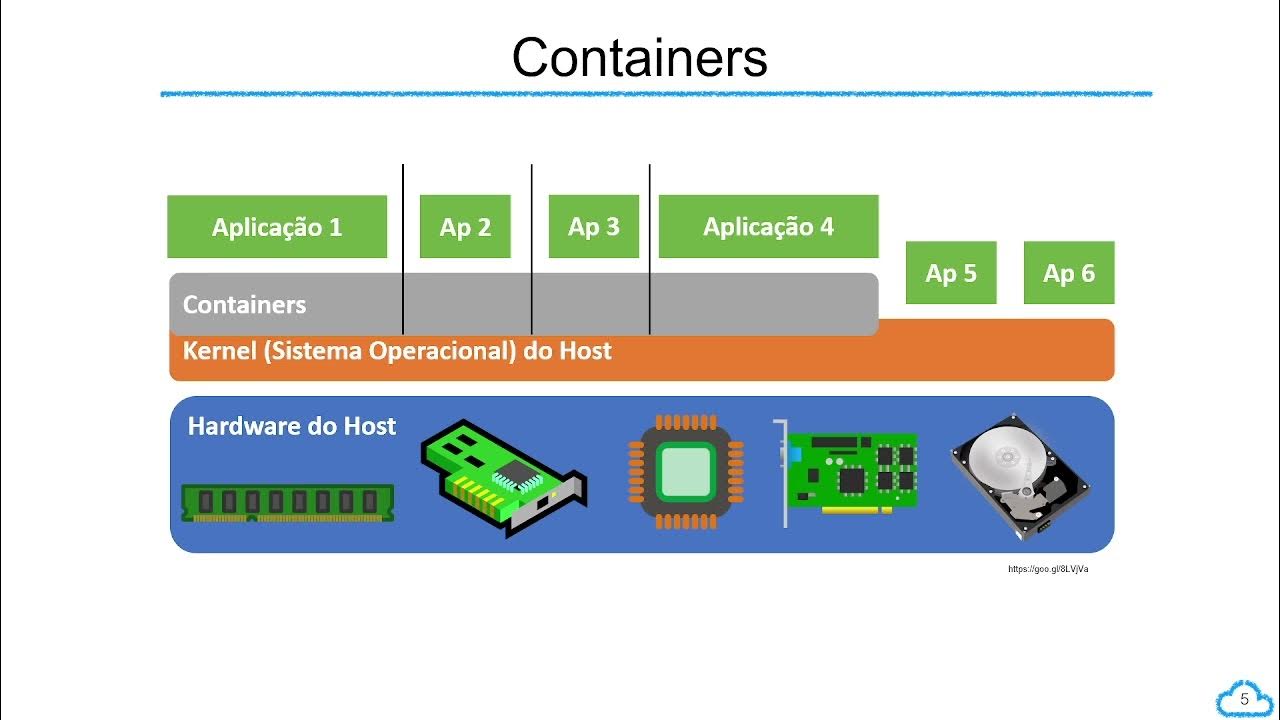
- 😀 Docker provides software delivery through isolated packages called containers
- 👍 Containers ensure reproducibility across environments like local and cloud
- 📦 Docker helps setup local data pipelines for experiments and tests
- 🛠 Docker images allow building reproducible and portable services
- 🔌 Docker enables running databases like Postgres without installing them
- ⚙️ Docker containers can be parameterized to pass inputs like dates
- 🎯 Docker entrypoint overrides default container command on run
- 🚆 Dockerfiles define instructions to build Docker images
- 🖥 Docker builds images automatically from Dockerfiles
- 🌎 Docker Hub provides public Docker images to use
Q & A
What is Docker and what are some of its key features?
-Docker is a software platform that allows you to build, run, test, and deploy applications quickly using containers. Key features include portability, isolation, and reproducibility.
Why is Docker useful for data engineers?
-Docker is useful for data engineers because it enables local testing and experimentation, integration testing, reproducibility across environments, and deployment to production platforms like AWS and Kubernetes.
What is a Docker image?
-A Docker image is a snapshot or template that contains all the dependencies and configurations needed to run an application or service inside a Docker container.
What is a Docker container?
-A Docker container is an isolated, self-contained execution environment created from a Docker image. The container has its own filesystem, resources, dependencies and configurations.
What is a Dockerfile?
-A Dockerfile is a text file with instructions for building a Docker image. It specifies the base image to use, commands to run, files and directories to copy, environment variables, dependencies to install, and more.
How do you build a Docker image?
-You build a Docker image by running the 'docker build' command, specifying the path of the Dockerfile and a tag for the image. This runs the instructions in the Dockerfile and creates an image.
How do you run a Docker container?
-You run a Docker container using the 'docker run' command along with parameters for the image name, ports to expose, environment variables to set, volumes to mount, and the command to execute inside the container.
What data set will be used in the course?
-The New York City taxi rides dataset will be used throughout the course for tasks like practicing SQL, building data pipelines, and data processing.
What tools will be used alongside Docker?
-The course will use PostgresSQL in a Docker container for a database. The pgAdmin tool will also be run via Docker to communicate with Postgres and run SQL queries.
What will be covered in the next video?
-The next video will cover running PostgresSQL locally with Docker, loading sample data into it using a Python script, and dockerizing that script to automate data loading.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频





5.0 / 5 (0 votes)
