Machine Learning Tutorial Python - 8: Logistic Regression (Binary Classification)
Summary
TLDRThis tutorial introduces logistic regression as a technique for solving classification problems, where the prediction is categorical rather than continuous as in linear regression. The video explains the concept of binary and multi-class classification, using the example of predicting customer insurance purchases based on age. It demonstrates how to visualize data with a scatter plot and how linear regression might be inappropriate for certain datasets. The presenter then introduces the sigmoid function, which logistic regression uses to model the probability of a certain class. The tutorial continues with a practical example using a dataset, showing how to perform a train-test split, train a logistic regression model, make predictions, and evaluate the model's accuracy. Finally, the video concludes with an exercise for viewers to apply logistic regression to an HR Analytics dataset to predict employee retention.
Takeaways
- 📈 The tutorial aims to solve a simple classification problem using logistic regression, which is different from linear regression that predicts continuous values.
- 🔍 Classification problems predict categorical outcomes, such as yes/no or choosing among multiple categories.
- 📊 Binary classification involves predicting an outcome with only two categories, while multi-class classification deals with more than two categories.
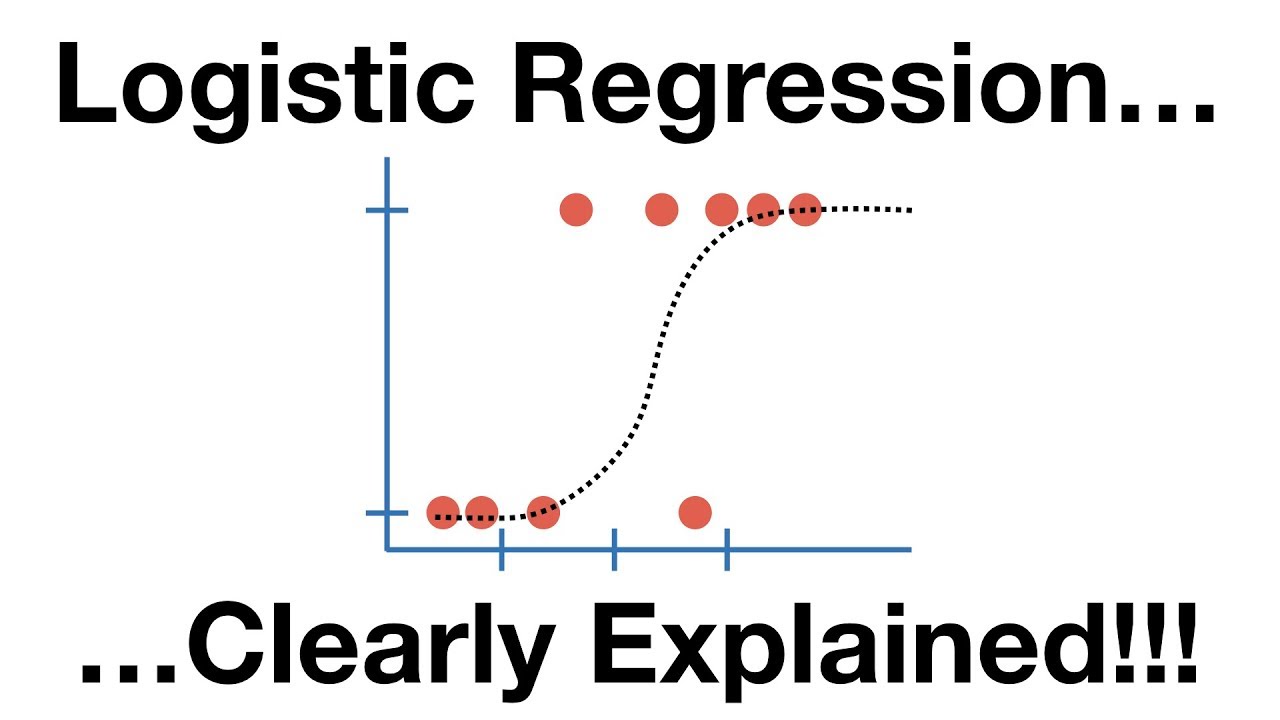
- 📉 The script demonstrates using a scatter plot to visualize data distribution, which helps in identifying patterns in the data before applying logistic regression.
- 🤖 Logistic regression models use a sigmoid function to transform linear equation outputs into a probability range between 0 and 1.
- 🧮 The sigmoid function has an S-shaped curve, mathematically represented as 1 / (1 + e^(-z)), where 'e' is Euler's number.
- 📝 The tutorial covers how to implement logistic regression using the scikit-learn library in Python, abstracting the complex mathematics.
- ⏭️ The process includes data splitting into training and test sets, model training with the training set, and making predictions with the test set.
- 💯 The accuracy of the logistic regression model is evaluated using the test set, with a score close to 1 indicating a high accuracy for the given dataset.
- 🤓 The script suggests exploring Kaggle for various datasets to practice building logistic regression models and solving real-world problems.
- 📚 The exercise at the end of the tutorial challenges learners to apply logistic regression to an HR Analytics dataset to predict employee retention.
- 🔧 The exercise involves exploratory data analysis, plotting bar charts for salary and department impact, building a logistic regression model, making predictions, and measuring model accuracy.
Q & A
What is the main goal of the tutorial?
-The main goal of the tutorial is to solve a simple classification problem using logistic regression.
What is the difference between linear regression and classification problems?
-Linear regression is used to predict continuous values, such as home prices or stock prices, while classification problems predict categorical values, such as yes/no or selecting one category from multiple options.
What are the two types of classification problems mentioned in the script?
-The two types of classification problems mentioned are binary classification, which involves predicting a simple yes or no outcome, and multi-class classification, which involves predicting one category from more than two available options.
How does logistic regression differ from linear regression in terms of the output it provides?
-Logistic regression provides an output that is a probability ranging between 0 and 1, which can be used to classify the prediction into categories, whereas linear regression provides a continuous output that can be any number.
What is the sigmoid function and how is it used in logistic regression?
-The sigmoid function is a mathematical function that takes any input and transforms it into a value between 0 and 1. It is used in logistic regression to convert the linear equation's output into a probability score that can be used for classification.
What is the purpose of splitting the dataset into a training set and a test set?
-The purpose of splitting the dataset is to use the majority of the data (training set) to train the model and a smaller portion (test set) to evaluate its performance and ensure that it generalizes well to new, unseen data.
How does the logistic regression model make predictions?
-The logistic regression model makes predictions by applying the sigmoid function to a linear equation derived from the training data. The output of the sigmoid function is then used to classify the prediction into one of the categories.
What is the significance of the score returned by the logistic regression model?
-The score returned by the logistic regression model represents the accuracy of the model. It is a measure of how well the model's predictions match the actual outcomes in the test set.
How can the logistic regression model predict the probability of an event occurring?
-The logistic regression model can predict the probability of an event occurring by applying the sigmoid function to the linear equation's output. The resulting probability score indicates the likelihood of the event.
What is the purpose of exploratory data analysis in the context of the HR Analytics dataset?
-The purpose of exploratory data analysis is to identify patterns and relationships within the data that can help understand factors affecting employee retention or attrition. This can inform the development of a logistic regression model to predict employee retention.
What are the steps involved in building a logistic regression model for the HR Analytics dataset?
-The steps involved include: 1) Exploratory data analysis to identify key factors affecting employee retention, 2) Plotting bar charts to visualize the impact of factors like salary and department on retention, 3) Building a logistic regression model using the identified factors, 4) Making predictions with the model, and 5) Measuring the model's accuracy.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频

Lec-5: Logistic Regression with Simplest & Easiest Example | Machine Learning

Konsep Dasar Regresi Logistik

PERBEDAAN UJI REGRESI LOGISTIK DAN UJI REGRESI LINEAR | PENJELASAN MUDAH DIPAHAMI MAHASISWA

What is Classification? What is a Classifier?

Week 2 Lecture 6 - Statistical Decision Theory - Classification
StatQuest: Logistic Regression
5.0 / 5 (0 votes)
