K - means implementation in R
Data Science for Engineers IITM
25 Mar 201821:14
Summary
The video is abnormal, and we are working hard to fix it.
Please replace the link and try again.
Please replace the link and try again.
Takeaways
- 😀 K-means 聚类是一种常用的无监督学习算法,用于根据数据的相似性将数据分为不同的类别。
- 😀 使用 R 语言实现 K-means 聚类时,首先需要加载并查看数据,以确定适合聚类的数值列。
- 😀 通过 `read.csv()` 函数导入数据,可以方便地将 CSV 文件转换为 R 中的数据框。
- 😀 `str()` 和 `summary()` 函数可以帮助快速了解数据的结构和基本统计信息。
- 😀 聚类的核心是选择合适的特征(如行程长度、速度、空闲时间等),这些特征有助于分组。
- 😀 在使用 K-means 聚类时,`kmeans()` 函数是核心函数,`centers` 参数决定了聚类的数量。
- 😀 通过执行 K-means 聚类后,可以获得每个数据点的聚类标签,表示该数据点属于哪个类别。
- 😀 K-means 聚类的结果包括每个聚类的中心、各个数据点的聚类分配以及聚类的总内聚度。
- 😀 在选择聚类数量时,可以使用肘部法则(Elbow Method)来帮助确定最佳的聚类数。
- 😀 聚类结果不仅可以帮助分析数据,还能为进一步的决策和分析提供支持,比如优化 Uber 乘车数据的服务。
- 😀 了解 K-means 聚类的基本原理和 R 中的实现步骤,可以为数据分析和机器学习应用打下基础。
The video is abnormal, and we are working hard to fix it.
Please replace the link and try again.
Please replace the link and try again.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级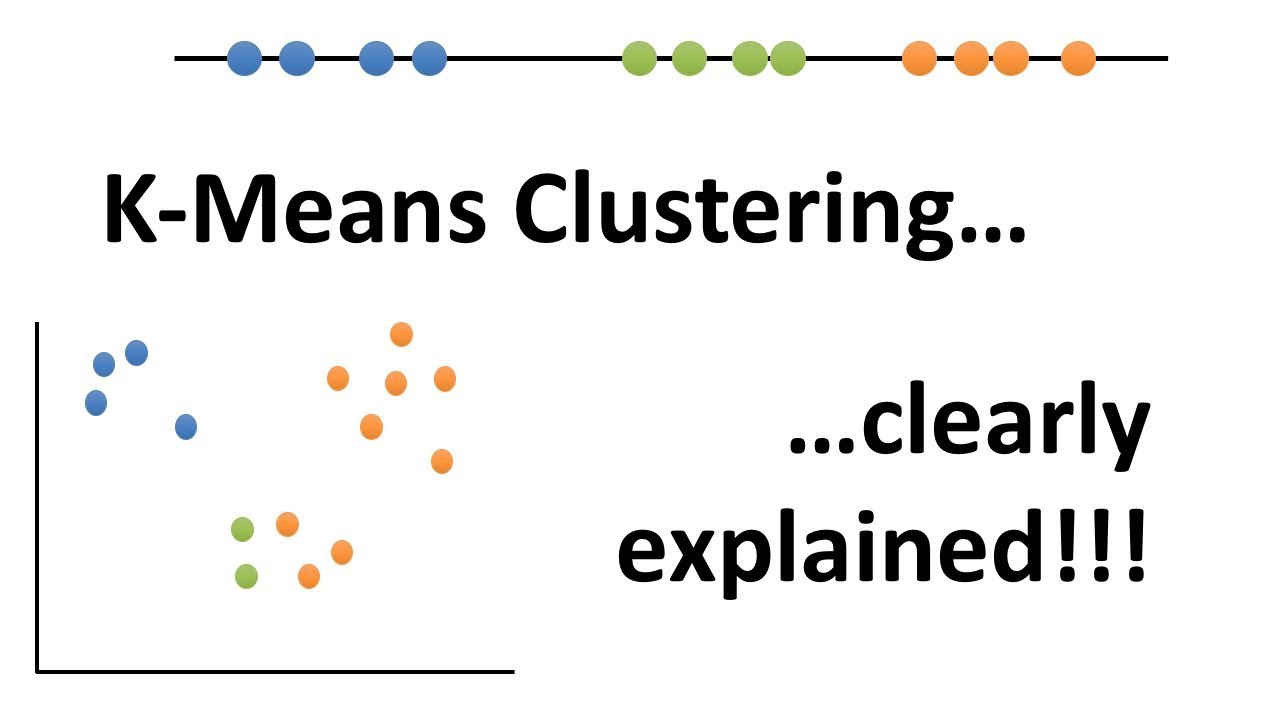





Rate This
★
★
★
★
★
5.0 / 5 (0 votes)