What is backpropagation really doing? | Chapter 3, Deep learning
Summary
TLDRThis script delves into backpropagation, the foundational algorithm for neural network learning. It offers an intuitive explanation without formulas, followed by a deeper dive into the calculus for those interested. The video covers the process of adjusting weights and biases to minimize cost functions, using the example of recognizing handwritten digits. It also touches on the practical aspects of training with large datasets, like MNIST, and the use of mini-batches for efficient stochastic gradient descent.
Takeaways
- 🧠 Backpropagation is the algorithm that enables neural networks to learn by calculating the gradient of the cost function with respect to the weights and biases.
- 📈 The cost function measures the error of the network's predictions against the actual target values, and minimizing this function is the goal of learning.
- 🔍 An intuitive understanding of backpropagation involves recognizing how each training example influences the adjustments of weights and biases to decrease the cost.
- 🤖 The script emphasizes the importance of understanding the role of each component in the backpropagation process, despite the complexity of the notation and calculations.
- 🔢 The magnitude of the gradient components indicates the sensitivity of the cost function to changes in the corresponding weights and biases.
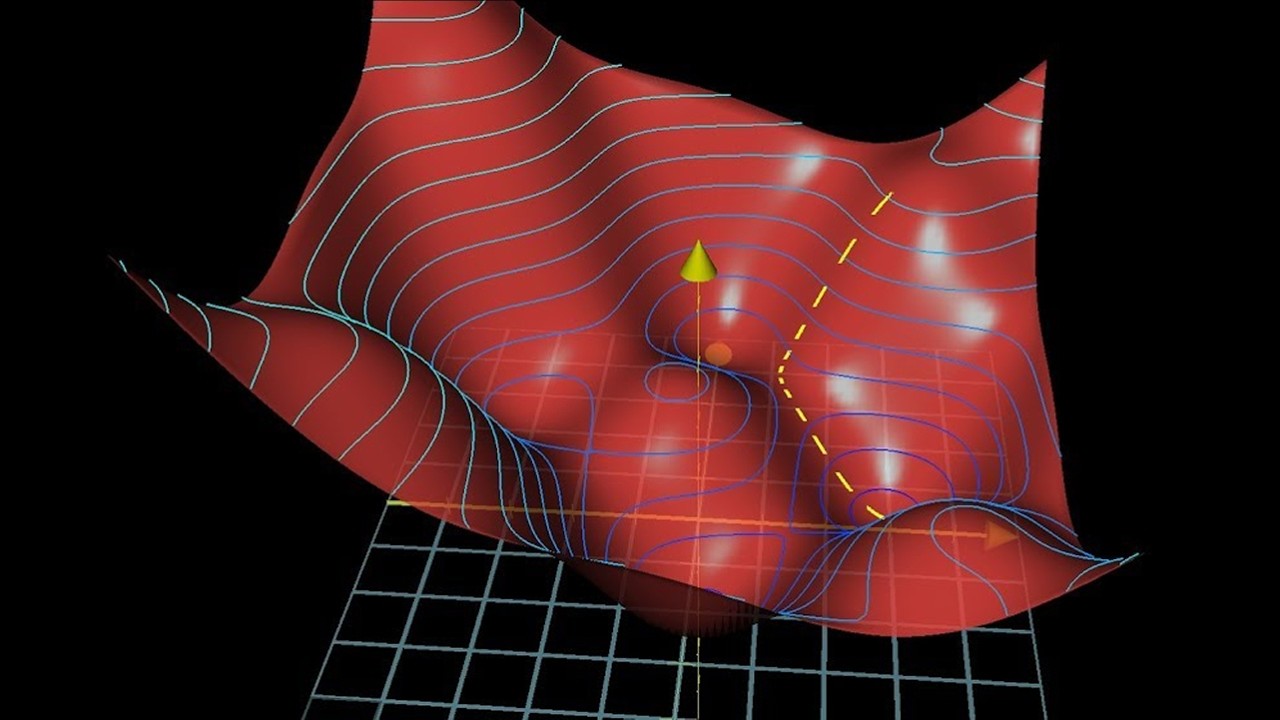
- 📉 The negative gradient points in the direction that will most efficiently reduce the cost, guiding the adjustments made during gradient descent.
- 🔄 The process of backpropagation involves moving backwards through the network, calculating the desired changes in activations and weights from the output layer to the input layer.
- 🔗 The concept of Hebbian theory is mentioned as a loose analogy to how weights are adjusted in neural networks, with stronger connections forming between co-active neurons.
- 💡 The adjustments to weights and biases are proportional to the influence they have on the cost function, with larger adjustments made to more influential weights.
- 📚 The script suggests that a deep understanding of backpropagation requires both an intuitive grasp of the process and a mathematical understanding of the underlying calculus.
- 💻 Practical implementation of backpropagation often uses mini-batches of training data for computational efficiency, a technique known as stochastic gradient descent.
Q & A
What is the core algorithm behind how neural networks learn?
-The core algorithm behind how neural networks learn is backpropagation.
What is the purpose of backpropagation in neural networks?
-The purpose of backpropagation is to compute the gradient of the cost function with respect to the weights and biases, which indicates how these parameters should be adjusted to minimize the cost and improve the network's performance.
How is the cost function defined for a single training example in the context of neural networks?
-The cost for a single training example is defined as the sum of the squares of the differences between the network's output and the desired output, for each component.
What is gradient descent and how does it relate to learning in neural networks?
-Gradient descent is an optimization algorithm used to minimize a cost function by iteratively moving in the direction of the negative gradient. In neural networks, learning involves finding the weights and biases that minimize the cost function using gradient descent.
How does the magnitude of the gradient vector components relate to the sensitivity of the cost function to changes in weights and biases?
-The magnitude of each component in the gradient vector indicates the sensitivity of the cost function to changes in the corresponding weight or bias. A larger magnitude means the cost function is more sensitive to changes in that particular weight or bias.
What is the role of the activation function in determining the output of a neuron in a neural network?
-The activation function, such as sigmoid or ReLU, is used to transform the weighted sum of inputs to a neuron, along with a bias, into the neuron's output. It introduces non-linearity into the network, allowing it to learn complex patterns.
What is the Hebbian theory in neuroscience, and how is it related to the learning process in neural networks?
-The Hebbian theory in neuroscience suggests that neurons that fire together wire together, meaning that connections between co-active neurons strengthen. This concept loosely relates to the learning process in neural networks, where weights between active neurons are increased during training.
Why is it necessary to adjust the weights and biases in proportion to their influence on the cost function?
-Adjusting the weights and biases in proportion to their influence on the cost function ensures that the most significant changes are made to the parameters that have the greatest impact on reducing the cost, leading to more efficient learning.
What is the concept of 'propagating backwards' in the context of backpropagation?
-The concept of 'propagating backwards' refers to the process of moving through the network from the output layer to the input layer, calculating the desired changes in weights and biases based on the error at each layer, which is then used to update the parameters.
What is a mini-batch in the context of stochastic gradient descent, and why is it used?
-A mini-batch is a subset of the training data used to compute a step in stochastic gradient descent. It is used to approximate the gradient of the cost function and to provide computational efficiency by not needing to process the entire dataset for each update.
What is the significance of having a large amount of labeled training data in machine learning?
-Having a large amount of labeled training data is crucial for machine learning because it allows the model to learn from a diverse set of examples, improving its ability to generalize and perform well on unseen data.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Week 5 -- Capsule 2 -- Training Neural Networks

KEL1 - [JST] ALGORITMA DAN ARSITEKTUR BACKPROPAGATION SERTA PENGENALAN POLA DENGAN BACKPROPAGATION

Backpropagation Solved Example - 4 | Backpropagation Algorithm in Neural Networks by Mahesh Huddar
Gradient descent, how neural networks learn | Chapter 2, Deep learning

Backpropagation calculus | Chapter 4, Deep learning

Tutorial 1- Introduction to Neural Network and Deep Learning
5.0 / 5 (0 votes)