Week 5 -- Capsule 2 -- Training Neural Networks
Summary
TLDRThis video explores the process of learning the parameters of a neural network, focusing on gradient-based optimization methods like backpropagation. It explains the challenges of finding closed-form solutions in neural networks and introduces the sigmoid function as a differentiable alternative to threshold functions. The video then delves into the backpropagation algorithm, explaining how it adjusts network weights iteratively to minimize error. It also discusses different gradient descent variations and the power of neural networks, which, with sufficient layers, can approximate any function with arbitrary accuracy.
Takeaways
- 😀 Gradient-based optimization is essential for learning neural network parameters as closed-form solutions are not feasible for most neural networks.
- 😀 Neural networks typically cannot find closed-form solutions for weights, unlike linear regression, which has a direct solution.
- 😀 The backpropagation algorithm is a core method for training neural networks, consisting of a forward pass and a backward pass.
- 😀 The forward pass involves using input data to make predictions, while the backward pass computes gradients to adjust weights.
- 😀 Differentiability is crucial for applying gradient-based optimization methods, which is why smooth functions like the sigmoid function are used.
- 😀 The backpropagation algorithm iteratively propagates the error backward from the output layer to the input layer to adjust weights.
- 😀 Gradient descent is used for weight optimization, where weights are updated by following the negative gradient of the error.
- 😀 Different variants of gradient descent exist: Stochastic Gradient Descent (SGD), Batch Gradient Descent, and Mini-Batch Gradient Descent.
- 😀 Stochastic Gradient Descent (SGD) uses one data point at a time, but it can be noisy, whereas Batch Gradient Descent uses the full dataset and is more stable.
- 😀 Mini-Batch Gradient Descent offers a balance by using a subset of the dataset, offering faster computations and reduced noise.
- 😀 A neural network with a single hidden layer can approximate any continuous function, and with multiple hidden layers, it can approximate any function with arbitrary accuracy.
Q & A
What is the primary method for estimating the parameters (weights) of a neural network?
-The primary method for estimating the parameters of a neural network is through gradient-based optimization, specifically using the backpropagation algorithm. This involves calculating the gradient of the objective function and iteratively adjusting the parameters to minimize the error.
Why can't we find a closed-form solution for the weights in neural networks like we can in linear regression?
-Neural networks involve complex non-linearities and multiple layers of computation, making it impossible to solve for the weights directly in a closed-form equation. Unlike linear regression, where we can find an explicit formula for the weights, neural networks require iterative methods like gradient descent.
What is the backpropagation algorithm and how does it work?
-Backpropagation is an algorithm used to compute the gradients of the error with respect to each parameter (weight) in the neural network. It works by starting from the output layer and propagating the error backward through the network, updating each weight based on its contribution to the overall error.
How does the sigmoid function help in training neural networks?
-The sigmoid function is differentiable everywhere, unlike threshold functions, which are not differentiable. By replacing threshold functions with sigmoid functions, we ensure that the network can compute gradients for each parameter, making it compatible with gradient-based optimization methods like backpropagation.
What is gradient descent, and how does it update the network parameters?
-Gradient descent is an optimization method that iteratively adjusts the network parameters by moving in the direction of the negative gradient of the error function. The step size is determined by the gradient and a hyperparameter called the learning rate.
What is the difference between stochastic gradient descent (SGD) and batch gradient descent?
-Stochastic gradient descent (SGD) calculates the gradient using a single data point at a time, which can lead to noisy updates. Batch gradient descent, on the other hand, uses the entire dataset to compute the gradient, providing a more stable but computationally expensive estimate.
Why is mini-batch gradient descent used in practice?
-Mini-batch gradient descent is a compromise between SGD and batch gradient descent. It uses a subset of the dataset (mini-batch) to compute the gradient, which reduces computational cost compared to batch gradient descent while still providing more stability than SGD.
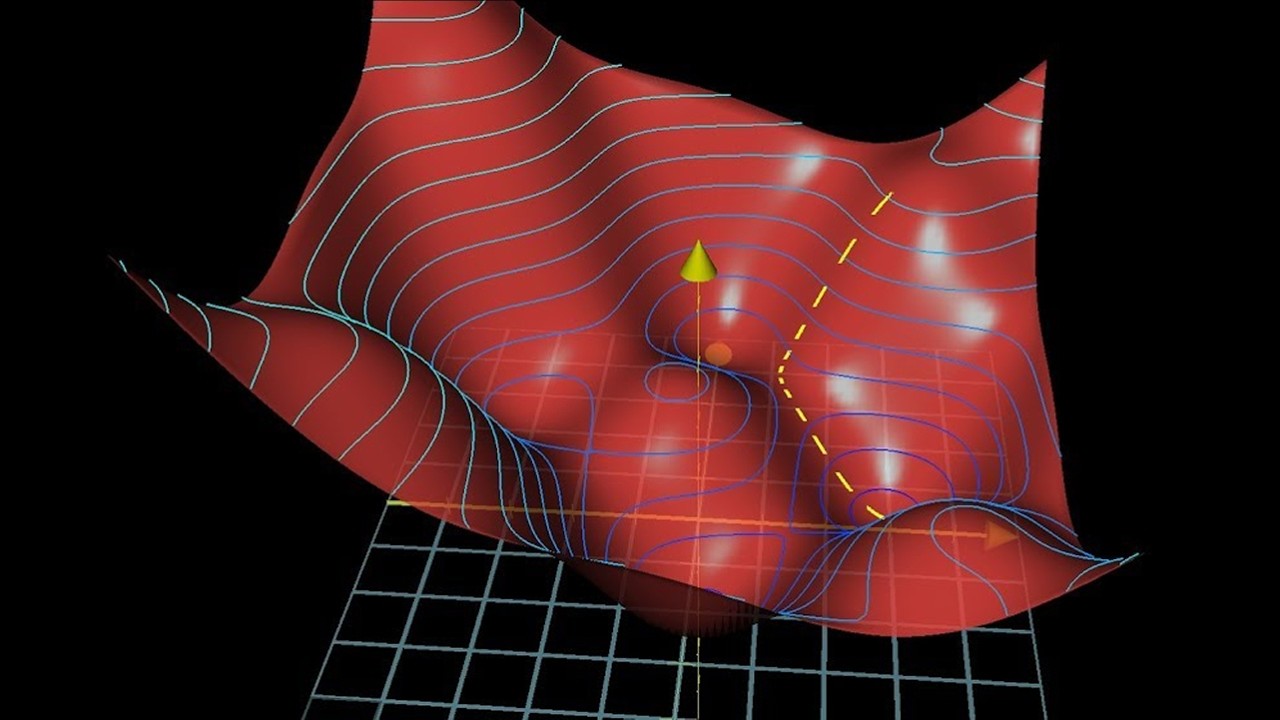
What happens if the function being optimized has multiple minima?
-If the function has multiple minima, gradient descent is likely to find a local minimum rather than a global one. The optimization process does not guarantee finding the global minimum, only a local one depending on the starting point and the path taken during the iterations.
How can a neural network with a single hidden layer represent complex functions?
-A neural network with a single hidden layer can represent any continuous function, but it may require a large number of hidden units, which grows exponentially with the number of inputs. This allows the network to approximate complex functions, but the complexity increases rapidly.
Can a neural network always learn any function using backpropagation?
-While a neural network with sufficient hidden layers can theoretically approximate any function with arbitrary accuracy, backpropagation and the optimization process do not guarantee that the network will always find the correct configuration. The outcome depends on the data, the optimization algorithm, and other factors.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Feedforward Neural Networks and Backpropagation - Part 1

Neural Networks Pt. 2: Backpropagation Main Ideas

Feedforward Explained - Neural Networks From Scratch Part 1
Gradient descent, how neural networks learn | Chapter 2, Deep learning

Optimization for Deep Learning (Momentum, RMSprop, AdaGrad, Adam)

Neural Networks Demystified [Part 4: Backpropagation]
5.0 / 5 (0 votes)