COS 333: Chapter 9, Part 2
Summary
TLDRThis lecture delves into advanced sub-program concepts, exploring parameter parsing methods such as in, out, and in-out modes, and their implementations like pass by value and pass by reference. It discusses the efficiency and safety trade-offs in parameter passing and touches on the complexities of multi-dimensional array parameters. The lecture also addresses the design issues related to sub-programs, including type checking, indirect calls, and the referencing environment of passed sub-programs, with examples in various programming languages.
Takeaways
- 📚 The lecture delves into Chapter 9, continuing the discussion on sub-programs, their design issues, and parameter parsing methods.
- 🔍 It differentiates between 'in', 'out', and 'in-out' modes for formal parameters, explaining how data is passed between the caller and the sub-program.
- 📈 The lecture introduces five implementation models for parameter passing: pass by value, pass by result, pass by reference, pass by value-result, and pass by name.
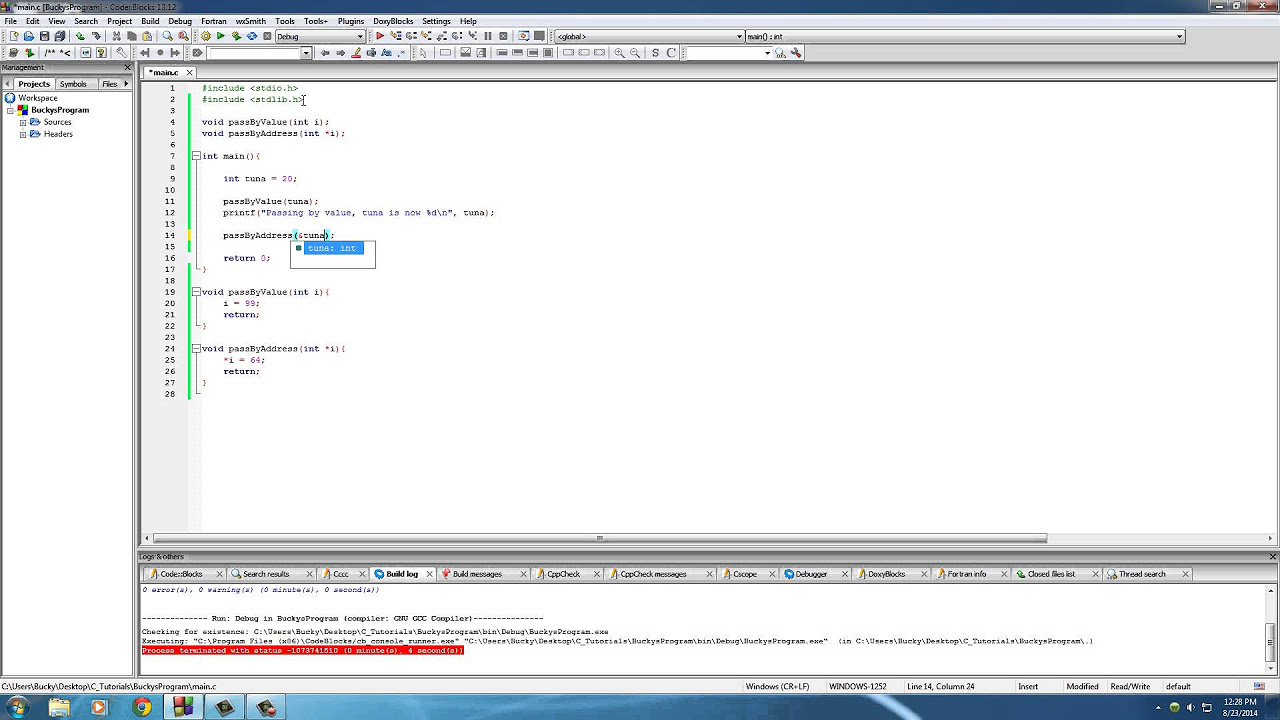
- 👉 Pass by value is demonstrated with an example in C++, highlighting how the actual parameter's value initializes the formal parameter within a sub-program.
- 🔄 Discusses the disadvantages of pass by value, such as the need for additional storage and potential high cost for large parameters due to copying.
- 🔧 Pass by result is explained with an ADA example, showing how the sub-program can modify the actual parameter's value through the formal parameter.
- 🔀 Pass by value-result combines both pass by value and pass by result, allowing data to be passed into and out of the sub-program.
- 💡 The advantages of pass by reference are highlighted, including efficiency in processing time and memory usage due to passing a reference instead of a copy.
- 🚧 The potential downsides of pass by reference are also discussed, such as slower access to formal parameters due to indirect addressing and the possibility of unwanted side effects.
- 🌐 The lecture provides insights into how different programming languages handle parameter passing, with examples from C, C++, Java, ADA, and others.
- 🔑 The concept of 'pass by name' is introduced as an older parameter parsing technique, which uses textual substitution and can lead to late binding of variables at runtime.
Q & A
What are the three modes for parameters in sub-programs?
-The three modes for parameters in sub-programs are 'in' mode, 'out' mode, and 'in-out' mode. 'In' mode formal parameters receive data from actual parameters in a subprogram call. 'Out' mode formal parameters send data to actual parameters. 'In-out' mode formal parameters both receive data from and send data to actual parameters.
What is the difference between pass by value and pass by reference?
-Pass by value involves copying the actual parameter's value into the formal parameter, creating two separate copies of the data. Pass by reference, on the other hand, involves passing the memory address of the actual parameter to the formal parameter, allowing the sub-program to access and modify the original data directly.
Why might pass by value be implemented using an access path?
-Pass by value can be implemented using an access path, typically through a pointer or reference, to avoid the overhead of copying large data structures. However, this approach is not commonly recommended due to the difficulty in enforcing write protection within the called sub-program, which could lead to unintended modifications of the actual parameter.
What are the advantages of pass by reference over pass by value?
-Pass by reference is more efficient in terms of processing time and memory usage. It avoids the need for copying large amounts of data, thus reducing processing time and memory overhead. However, it can introduce potential issues such as unwanted side effects and aliases.
How does pass by result differ from pass by value?
-Pass by result is an 'out' mode parameter parsing technique where the value of the formal parameter is used to change the corresponding actual parameter's value. Unlike pass by value, no value is transmitted to the sub-program; instead, data is only transmitted back to the caller when control is returned.
What is the concept of 'pass by name' in parameter passing?
-Pass by name involves textual substitution where all occurrences of a formal parameter are replaced by the corresponding actual parameter. The binding to a value or address only occurs when the formal parameter is used in the sub-program, allowing for late binding and flexibility in how parameters are accessed.
Why is parameter type checking important in programming languages?
-Parameter type checking is important for ensuring the reliability of a program. It verifies that the types of actual and formal parameters match, preventing type mismatches that could lead to unexpected behavior or errors at runtime.
How do programming languages handle multi-dimensional arrays as parameters?
-Languages like C and C++ require specifying the sizes of all dimensions except the first in the function parameter list. Java and C# handle multi-dimensional arrays as objects with a length property, allowing the size to be dynamically determined at runtime without needing explicit size declarations in the parameter list.
What is the difference between shallow binding and deep binding for sub-programs?
-Shallow binding uses the calling environment of the sub-program that actually performs the call, while deep binding uses the definition environment of the sub-program being called. Shallow binding is natural for dynamically scoped languages, whereas deep binding is for statically scoped languages.
What are the considerations for passing sub-programs as parameters?
-When passing sub-programs as parameters, considerations include whether parameter types are checked and determining the referencing environment for the passed sub-program, which can be influenced by shallow binding, deep binding, or ad-hoc binding.
How do function pointers in C++ allow for calling sub-programs indirectly?
-Function pointers in C++ are pointers to functions that include parameter and return types. They can be assigned to any function that matches the specified requirements, allowing for indirect calls to functions through the pointer.
What is the role of delegates in C# for calling sub-programs indirectly?
-In C#, delegates are objects that can be used to call sub-programs indirectly. They are created by defining a delegate type with a specific method signature and then instantiating delegate objects with methods that match this signature.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

COS 333: Chapter 9, Part 1

136. OCR A Level (H046-H446) SLR23 - 2.2 Functions & procedures
C Programming Tutorial - 58 - Pass by Reference vs Pass by Value

Capítulo 4 - Funções de usuário: Parâmetros

MySQL - Parâmetros IN, OUT e INOUT em Procedimentos Armazenados - 36

Pass by Value vs. Pass by Reference | Python Course #12
5.0 / 5 (0 votes)