BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM
Summary
TLDRThis video compares two popular Transformer models: BERT (from Google) and GPT (from OpenAI). Both share similar architectural elements, such as multi-headed attention and feed-forward networks, but differ in their encoder-decoder structures. BERT is bidirectional and supports pre-training and fine-tuning, making it adaptable to new data. In contrast, GPT is unidirectional and focuses solely on pre-training, with minimal fine-tuning. The video highlights how BERT’s flexibility allows for continual learning, while GPT’s massive scale and black-box nature make it more restrictive. Ultimately, BERT is seen as better optimized for specific tasks and is widely used in NLP applications.
Takeaways
- 😀 Bert and GPT are both based on Transformer architecture, with Bert using an encoder and GPT using a decoder.
- 😀 Both models contain similar components, including multi-headed attention and feed-forward networks, but GPT has additional mask multi-headed attention.
- 😀 GPT is unidirectional, meaning it only looks at previous words to predict the next word, while Bert is bidirectional and considers both previous and following words.
- 😀 Bert has a two-step learning process: pre-training and fine-tuning, which allows continuous learning with new data, while GPT only undergoes massive pre-training without further learning after that.
- 😀 Bert can adapt to new data by adding an additional layer to its architecture and retraining the whole network, while GPT requires pre-training from scratch if new data is added.
- 😀 Bert’s pre-trained layers are generally task-agnostic, allowing for more flexibility in fine-tuning specific layers, especially the last ones, for downstream tasks.
- 😀 Optimization techniques such as dynamic MLM and the dropping of next sentence prediction were applied to Bert to improve its performance.
- 😀 GPT's sheer size and black-box nature make it more restrictive compared to Bert in certain contexts, despite GPT's impressive capabilities.
- 😀 Bert has performed well across many tasks and can be found across most leaderboard results, outperforming GPT in certain benchmarks.
- 😀 GPT learns through reinforcement learning from human feedback, a key component in its ability to produce coherent and contextually relevant outputs.
- 😀 The future of transformer-based models may involve a deeper exploration of fine-tuning strategies and optimization methods to improve their efficiency and applicability in different scenarios.
Q & A
What is the main difference between the encoder and decoder architecture in transformer-based models like BERT and GPT?
-The encoder (BERT) and decoder (GPT) are built using similar Transformer architecture, with both having multi-headed attention and a feedforward network. The main difference is that GPT includes an additional masked multi-head attention in the decoder, making it unidirectional, while BERT is bidirectional, considering both the previous and next words for prediction.
Why is GPT considered unidirectional?
-GPT is unidirectional because it only looks at the words before the current word to predict the next one, whereas BERT is bidirectional, looking both before and after the target word.
What is the significance of pre-training and fine-tuning in BERT?
-In BERT, pre-training allows the model to learn general language representations, while fine-tuning adapts it to specific downstream tasks. Fine-tuning makes BERT highly flexible for various tasks by continuing to train with task-specific data.
How does the learning process differ between GPT and BERT?
-GPT undergoes massive pre-training but does not continue learning after that; it only uses a prompt for further tasks. BERT, on the other hand, allows both pre-training and fine-tuning, enabling it to adapt and learn from new data over time.
What is the advantage of BERT over GPT when it comes to new data?
-In BERT, if new data comes in, you can simply add a fine-tuning layer and retrain the model, which is easier than re-training the entire model from scratch. GPT, however, requires re-training the whole system if new data is introduced.
How can BERT’s architecture be optimized for specific tasks?
-BERT's architecture can be optimized for specific tasks by freezing the initial layers and focusing the training on the last layers, which are the most task-specific. This can speed up training and make the model more efficient for certain applications.
What role does reinforcement learning play in GPT’s performance?
-Reinforcement learning from human feedback (RLHF) is added to GPT to enhance its learning process and fine-tune its responses. This approach improves the model’s performance by making it more aligned with human-like understanding and decision-making.
What is the difference between the pre-training and fine-tuning phases in BERT?
-Pre-training in BERT involves training the model on a large corpus of text to learn general language representations. Fine-tuning involves adjusting the model for specific tasks using labeled data, allowing BERT to perform specialized tasks like sentiment analysis or question answering.
Why is GPT 3.5 considered powerful despite its lack of fine-tuning?
-GPT 3.5 is powerful due to its massive scale and sheer size, which allows it to generate high-quality text based on its pre-training. While it doesn't fine-tune on specific tasks, its large model capacity enables it to perform impressively well on a wide range of tasks out of the box.
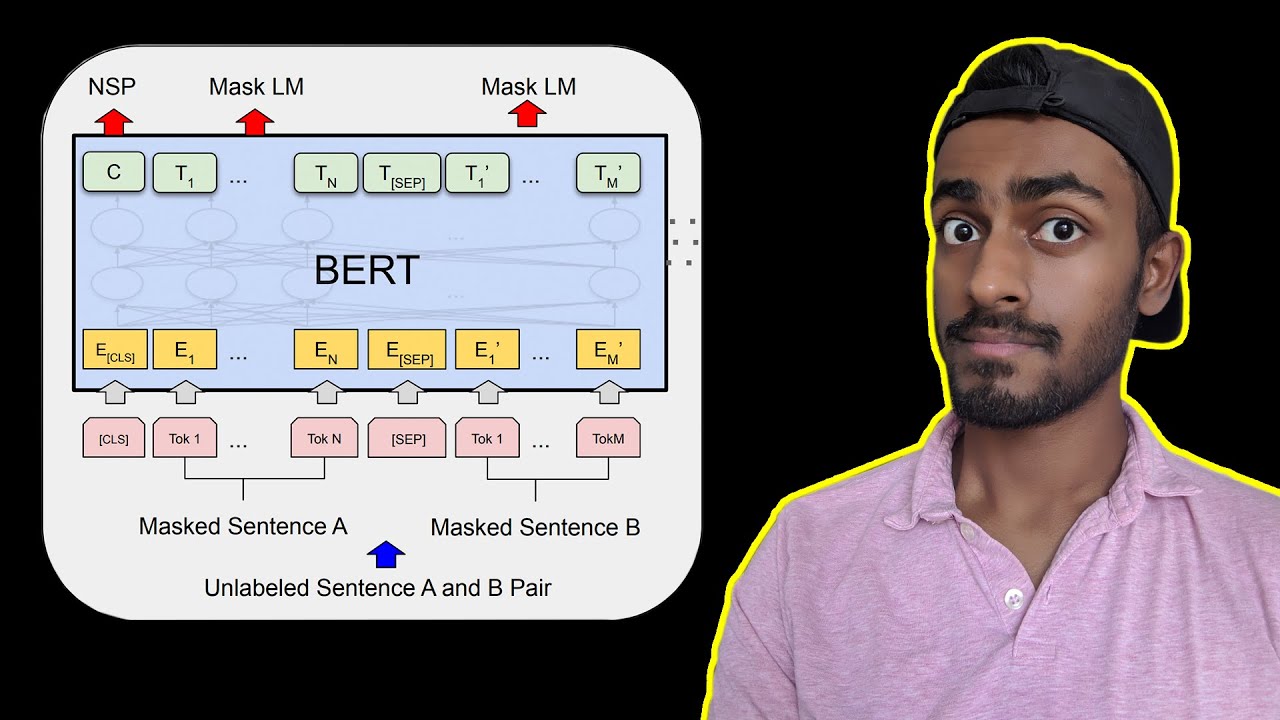
How does BERT’s use of the Masked Language Model (MLM) and Next Sentence Prediction (NSP) tasks differ from GPT?
-BERT uses two key pre-training tasks: the Masked Language Model (MLM), which predicts missing words in a sentence, and Next Sentence Prediction (NSP), which predicts if two sentences logically follow each other. GPT, however, is based on autoregressive modeling and does not use MLM or NSP; it focuses solely on predicting the next word in a sequence.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Stanford CS25: V1 I Transformers United: DL Models that have revolutionized NLP, CV, RL

AI News: This Was an INSANE Week in AI!

Opus 4.6 vs. Chat GPT 5.3 (coloquei os dois a prova)

New ChatGPT o1 VS GPT-4o VS Claude 3.5 Sonnet - The Ultimate Test
LLM Foundations (LLM Bootcamp)
BERT Neural Network - EXPLAINED!
5.0 / 5 (0 votes)