RAG vs Fine-Tuning vs Prompt Engineering: Optimizing AI Models
Summary
TLDRIn this video, the speaker explores three key ways to enhance large language model responses: Retrieval-Augmented Generation (RAG), Fine-Tuning, and Prompt Engineering. RAG uses external data for up-to-date, domain-specific answers but adds computational overhead. Fine-tuning focuses on adapting models with specialized datasets, delivering faster, more domain-expert responses but requiring substantial resources and careful maintenance. Prompt Engineering improves the model’s output through detailed input, offering flexibility and immediate results without altering infrastructure. The video highlights the strengths and trade-offs of each method and how they can be combined to optimize AI performance.
Takeaways
- 😀 The modern equivalent of Googling yourself is asking a large language model (LLM) about your name, though the model's response varies based on its training data and cutoff dates.
- 😀 To improve the accuracy of an LLM’s answer, three methods can be applied: Retrieval Augmented Generation (RAG), fine-tuning, and prompt engineering.
- 😀 RAG involves retrieving up-to-date data from an external source, augmenting the query with that data, and then generating a response based on the enriched information.
- 😀 RAG allows a model to search for new data or incorporate recent information not available during its original training, making it useful for getting accurate, domain-specific, and up-to-date responses.
- 😀 A downside of RAG is the added computational overhead, including retrieval time and the need for storing vector embeddings in a database, which increases processing and infrastructure costs.
- 😀 Fine-tuning involves taking a pre-trained model and further training it on a specialized dataset to create deep expertise in a specific domain.
- 😀 Fine-tuning improves model performance in specialized areas but requires substantial resources, including quality training data, GPUs for processing, and time for the training process.
- 😀 One risk with fine-tuning is 'catastrophic forgetting,' where the model loses some of its general knowledge while learning new specialized data.
- 😀 Prompt engineering is the practice of crafting better, more detailed prompts to guide the model’s attention toward relevant patterns in its training data, improving response quality without additional training or data retrieval.
- 😀 While prompt engineering offers flexibility and immediate results, it cannot extend the model's knowledge, as it only utilizes the existing training data and does not address outdated or missing information.
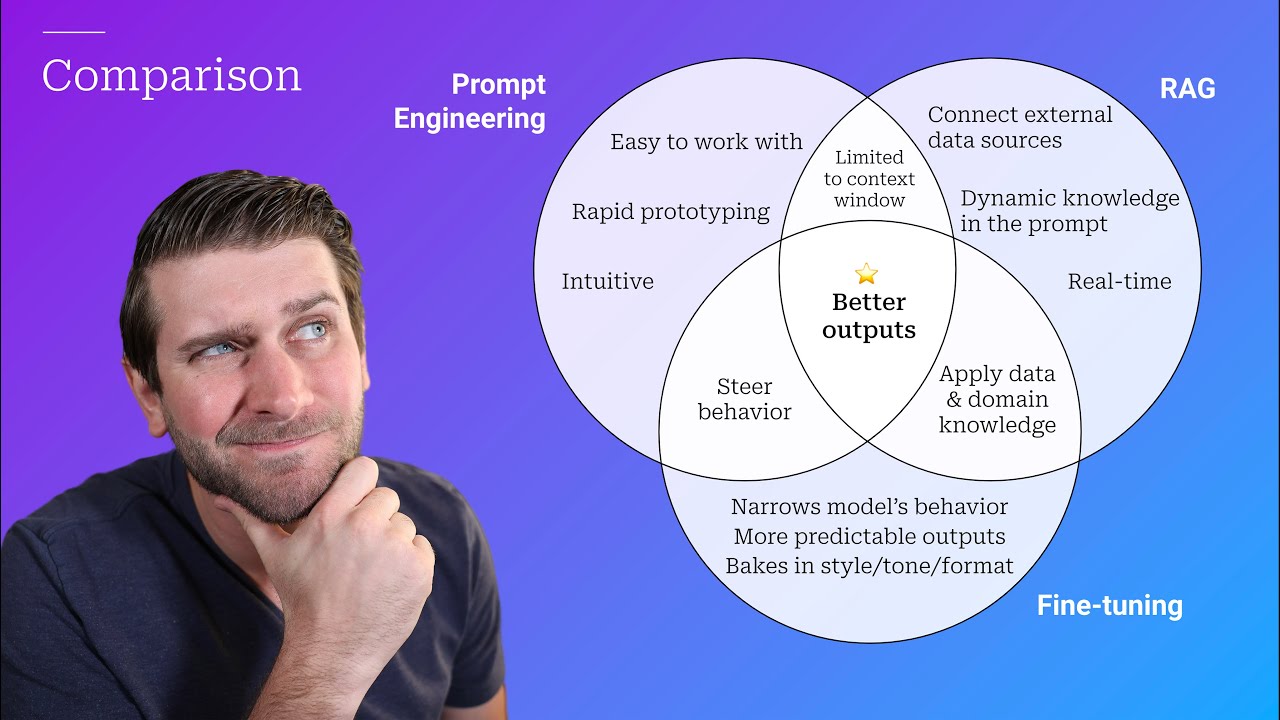
- 😀 RAG, fine-tuning, and prompt engineering are often used together to optimize results. For example, in a legal AI system, RAG retrieves up-to-date cases, prompt engineering ensures the right format, and fine-tuning ensures firm-specific expertise.
Q & A
What is the modern equivalent of Googling yourself?
-The modern equivalent is to ask a large language model (LLM) about yourself, as the information it provides may vary based on the model's training data and cutoff dates.
How do different large language models differ in their responses about the same person?
-Different models have different training data and knowledge cutoff dates, so the information they provide about the same person can vary significantly.
What are the three methods for improving a large language model's answers?
-The three methods are Retrieval Augmented Generation (RAG), fine-tuning, and prompt engineering.
What is Retrieval Augmented Generation (RAG)?
-RAG is a method where a model retrieves external, up-to-date information before generating an answer. It combines retrieval of relevant data with the original prompt to generate a more accurate and current response.
What are the key steps involved in the RAG process?
-The key steps in RAG are retrieval (searching through a corpus of information), augmentation (adding the retrieved data into the query), and generation (producing the response based on the enriched context).
What are some of the costs associated with using RAG?
-RAG can introduce performance costs due to the additional retrieval step, infrastructure costs for storing vector embeddings, and processing costs for handling and maintaining the data.
What is fine-tuning in the context of large language models?
-Fine-tuning is the process of updating a model's parameters using a specialized data set to make the model more adept in a specific domain or area of expertise, like technical support or legal advice.
What are the advantages and drawbacks of fine-tuning a model?
-Advantages of fine-tuning include faster inference and deep domain expertise. However, it requires substantial computational resources, a large number of high-quality training examples, and poses risks like catastrophic forgetting, where general knowledge is lost in favor of specialized knowledge.
What is prompt engineering and how does it differ from RAG and fine-tuning?
-Prompt engineering involves crafting specific prompts to guide the model’s attention to relevant knowledge or patterns in its training data. Unlike RAG or fine-tuning, prompt engineering doesn't involve adding new information or adjusting the model's internal weights—it simply helps better activate existing knowledge.
What are some benefits of using prompt engineering?
-Prompt engineering allows for immediate results without changing backend infrastructure. It also provides flexibility, as users can adapt the model's responses to their needs by adjusting the prompts.
How can RAG, fine-tuning, and prompt engineering be used together?
-RAG can provide up-to-date information, fine-tuning can offer deep domain expertise, and prompt engineering can ensure the model follows specific formats. Together, these methods can be used to create a powerful and specialized AI system.
What is the trade-off between the three methods—RAG, fine-tuning, and prompt engineering?
-RAG offers up-to-date knowledge but comes with performance costs. Fine-tuning enables deep expertise but is resource-intensive and prone to maintenance challenges. Prompt engineering offers flexibility and immediate results but cannot extend the model’s knowledge.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Fine Tuning, RAG e Prompt Engineering: Qual é melhor? e Quando Usar?
Prompt Engineering, RAG, and Fine-tuning: Benefits and When to Use
Introduction to Generative AI

The Vertical AI Showdown: Prompt engineering vs Rag vs Fine-tuning

A Survey of Techniques for Maximizing LLM Performance

I Built Over 20 AI Projects. Here’s The Top 2.
5.0 / 5 (0 votes)