I Built Over 20 AI Projects. Here’s The Top 2.
Summary
TLDRThis video outlines two essential AI projects for aspiring AI engineers: fine-tuning a large language model (LLM) and building a retrieval-augmented generation (RAG) workflow. Fine-tuning enhances an LLM’s performance on specific tasks by training it on custom datasets, while RAG augments an LLM with external data for more accurate responses. The video offers practical tips for making each project unique, such as training on incorrect answers for fine-tuning and choosing interesting datasets for RAG. It also covers key libraries and tools like Hugging Face Transformers and Langchain to help implement these projects efficiently.
Takeaways
- 😀 Fine-tuning LLMs allows models to excel in specific tasks or domains, improving performance in specialized areas.
- 😀 You can fine-tune models with small datasets (100-500 data points) using open-source models like GPT-2 or Meta's Llama.
- 😀 The fine-tuning process becomes more feasible and computationally efficient with the use of libraries like Transformers and Bits and Bytes.
- 😀 Using advanced fine-tuning techniques, such as training models on incorrect answers, can help the model learn logical reasoning and error detection.
- 😀 To make fine-tuning projects stand out, choose a unique and interesting dataset that hasn't been fine-tuned before (e.g., niche topics or specialized problems).
- 😀 Fine-tuning is not just for technical recruiters—explaining the project to a technical hiring manager in an interview is key to demonstrating your skills.
- 😀 Retrieval-Augmented Generation (RAG) enhances LLMs by adding external information through a vector database, making the model capable of answering questions with data outside its training set.
- 😀 RAG is ideal for use cases like company-specific knowledge or internal documents that cannot be included in the original training data.
- 😀 The RAG workflow involves chunking documents into smaller units, storing them in a vector database, and using a retriever model to fetch relevant chunks for context.
- 😀 Implementing RAG effectively requires libraries like LangChain to connect all components, such as the retriever, vector database, and LLM, into a seamless workflow.
Q & A
What is fine-tuning in the context of LLMs (Large Language Models)?
-Fine-tuning is the process of training a general-purpose LLM, like GPT, on a smaller, specialized dataset to improve its performance for a specific task or domain. This allows the model to become more efficient at handling particular types of queries, like math problems or specialized data, without retraining it from scratch.
How can fine-tuning an LLM be made unique and stand out on a resume?
-To make your fine-tuning project unique, you can choose a specialized or interesting dataset that hasn't been commonly used for fine-tuning. Additionally, you can experiment with advanced techniques, such as training a model on incorrect answers and teaching it to identify the logical flaws in those answers, which sets your project apart from others.
What is the advantage of fine-tuning a model with a small dataset, like 100-500 data points?
-Fine-tuning with a small dataset is advantageous because it doesn’t require massive computational resources or extensive training data. By using techniques like LoRA (Low-Rank Adaptation), you can train the model effectively without needing expensive GPUs or large amounts of data, making it more feasible for individual developers.
What is the role of the 'bits and bytes' library in fine-tuning an LLM?
-The 'bits and bytes' library is used to quantize the model, which reduces the precision of the numbers used in calculations (e.g., from 32-bit to 4-bit), significantly reducing memory requirements on the GPU. This makes the fine-tuning process more computationally feasible while maintaining much of the model's performance.
Why would someone choose to use RAG (Retrieval-Augmented Generation) instead of fine-tuning?
-RAG is chosen over fine-tuning when you need the LLM to access external data that wasn't part of its original training dataset, such as private company documents. RAG is less resource-intensive and can be quicker to set up, as it doesn't require retraining the model but instead augments the LLM's knowledge with real-time data retrieval.
What are the key components involved in a RAG workflow?
-A RAG workflow involves several key components: a retriever model that searches for relevant chunks of data, a vector database (like Chroma DB or Pinecone) that stores these chunks, and an LLM that processes the retrieved data and generates a response based on it.
How does the retriever model in a RAG system interact with the vector database?
-In a RAG system, the retriever model queries the vector database for relevant chunks of data that might answer a user's question. These chunks are then passed as context to the LLM, which uses them to generate a more informed and accurate response.
What are some tools or libraries needed to build a RAG workflow?
-To build a RAG workflow, you'll need several tools and libraries: Hugging Face for the LLM, Langchain for integrating the retriever model with the LLM, and a vector database like Chroma DB or Pinecone to store and retrieve data.
How can you make your RAG project stand out to technical hiring managers?
-To stand out with a RAG project, it’s important to choose an interesting and unique dataset for retrieval, such as proprietary or domain-specific data. Most importantly, understanding and explaining the neural network mechanics behind the entire RAG workflow will demonstrate deeper technical expertise.
What are the challenges of fine-tuning models like GPT, and how can they be overcome?
-The challenges of fine-tuning models like GPT include the high computational cost and the large datasets typically required. These challenges can be overcome by using open-source models like GPT-2 or LLaMA, applying techniques like LoRA for more efficient fine-tuning, and using smaller, high-quality datasets (100-500 data points).
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
Introduction to Generative AI

5 AI Engineer Projects to Build in 2026 | Ex-Google, Microsoft
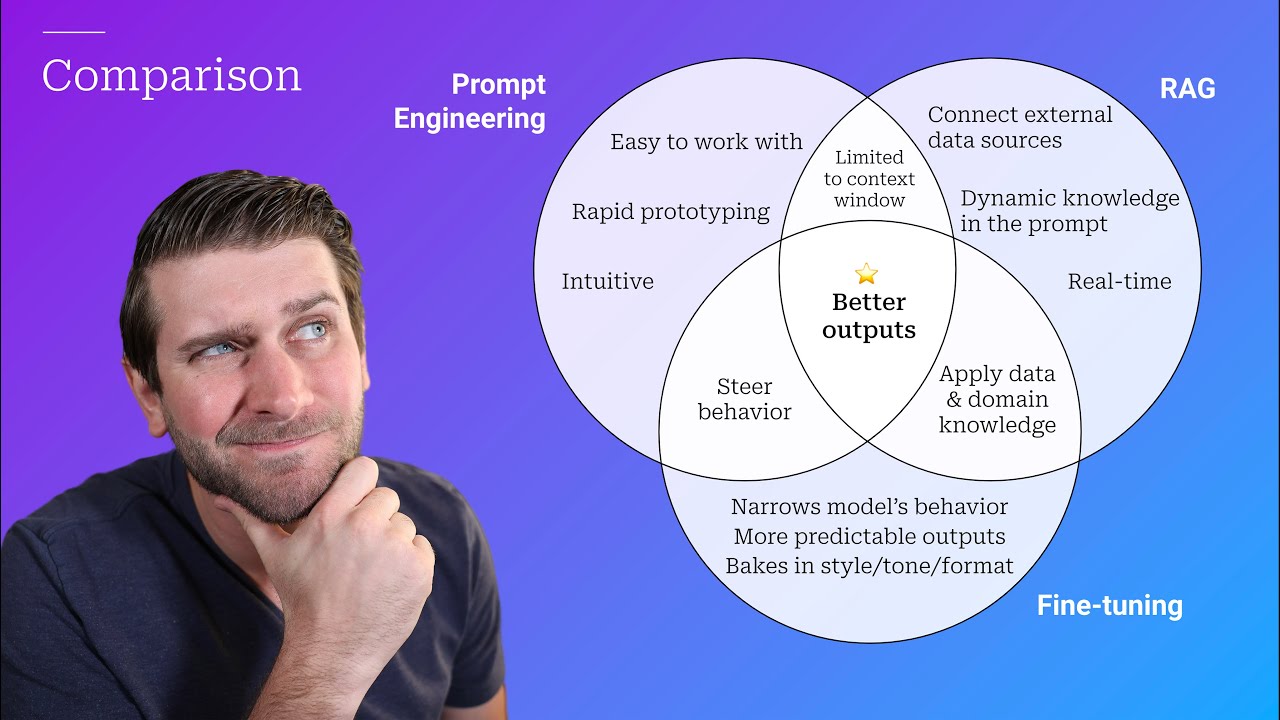
Prompt Engineering, RAG, and Fine-tuning: Benefits and When to Use

The Vertical AI Showdown: Prompt engineering vs Rag vs Fine-tuning

RAG vs Fine-Tuning vs Prompt Engineering: Optimizing AI Models

Fine-Tuning, RAG, or Prompt Engineering? The Ultimate LLM Showdown Explained!
5.0 / 5 (0 votes)