Why Everyone is Freaking Out About RAG
Summary
TLDRThe video script introduces Retrieval Augmented Generation (RAG), a technique that enhances Language Models (LMs) by connecting them to a data store for up-to-date, accurate responses. It addresses issues like outdated data and lack of source transparency in LMs. RAG allows developers to use LMs for reasoning without relying on their training data, ensuring responses are current and verifiable. The script outlines RAG's architecture, benefits like avoiding retraining and providing sources, and concerns about data relevance and retrieval efficiency.
Takeaways
- 🤖 RAG stands for Retrieval-Augmented Generation, a technique that enhances the usability of Large Language Models (LLMs) by addressing their limitations.
- 📚 Current LLMs often provide outdated answers or lack transparency in how they derive their answers, which can lead to misinformation.
- 🔍 RAG connects an LLM to a data store, allowing it to retrieve up-to-date information to generate responses, thus solving the problem of outdated data.
- 💡 By using RAG, developers can implement LLMs in their applications with confidence in the accuracy of the results and the ability to trace the source of information.
- 📈 RAG enables LLMs to use their reasoning abilities rather than relying on their training data, making them more effective for natural language understanding and generation.
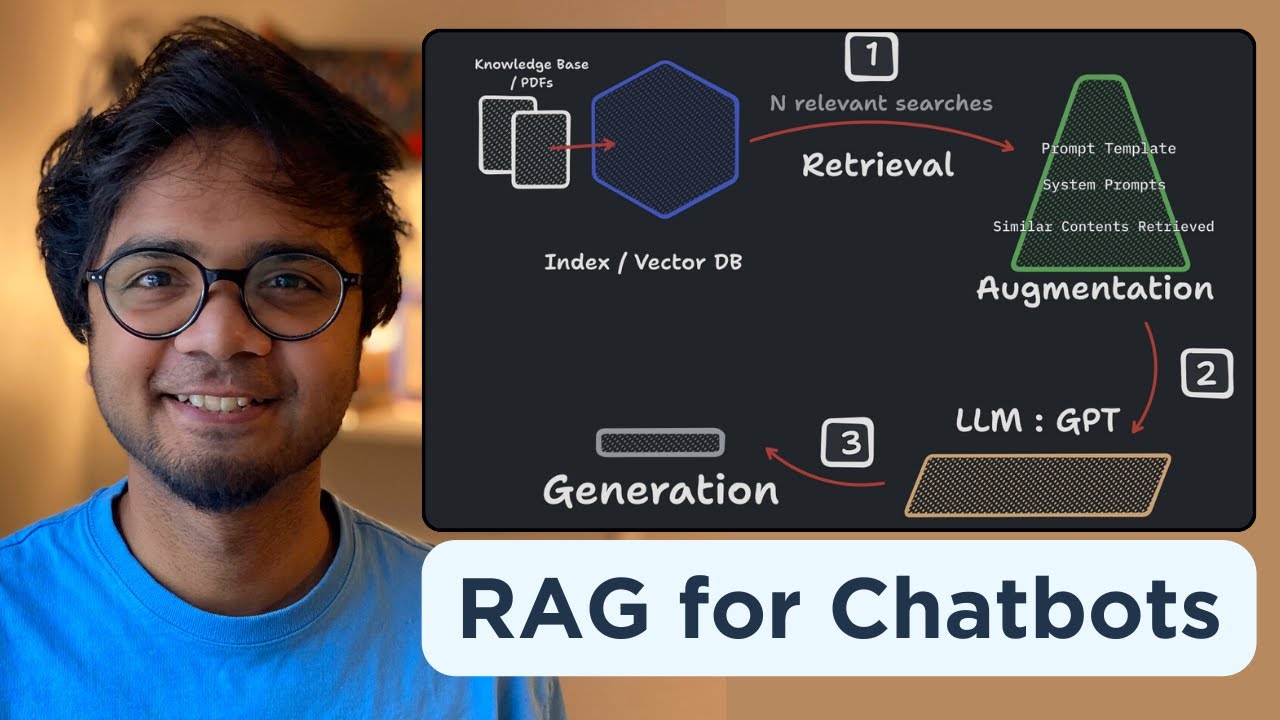
- 🛠️ The architecture of RAG involves vectorizing prompts, using a retriever to find relevant data, and then augmenting the LLM with this data to provide evidence-based answers.
- 🚫 One of the benefits of RAG is that it allows developers to avoid retraining LLMs, instead keeping the data source updated to ensure current information.
- 🔗 RAG provides a source for data, allowing users to validate the information and know where the LLM derived its answers from, increasing trust in the model's responses.
- 🛑 RAG also allows LLMs to admit when they don't have an answer, avoiding the provision of misleading or incorrect information.
- 👀 Concerns with RAG include the need for efficient and accurate retrieval of relevant information, and ensuring the model uses this data correctly without introducing latency.
- 📘 Understanding RAG requires knowledge of how LLMs work, and resources like HubSpot's 'How to Use Chat GPT at Work' can provide valuable insights for developers.
Q & A
What does RAG stand for and what is its purpose?
-RAG stands for Retrieval-Augmented Generation. Its purpose is to enhance the usability of Large Language Models (LLMs) by addressing issues such as outdated information and the lack of transparency in how the models generate answers.
What are the two major issues with current LLMs as mentioned in the script?
-The two major issues with current LLMs are outdated data and the lack of a source for the information provided. LLMs may give answers based on data they were trained on, which may not be current, and they often do not provide a way to verify the accuracy of their answers.
How does RAG address the problem of outdated information in LLMs?
-RAG addresses the problem of outdated information by connecting an LLM to a data store. When the LLM needs to generate an answer, it retrieves up-to-date data from the data store and uses this data to inform its response, ensuring the information is current.
How does RAG provide transparency in the information provided by an LLM?
-RAG provides transparency by allowing the LLM to retrieve data from a specific source, which can then be used to generate a response. This means that users can trace back the information to its original source, verifying the accuracy and relevance of the data.
What is an example of how RAG can be used in a practical scenario?
-An example given in the script is using an LLM to retrieve up-to-date scores for a football game. The LLM would be connected to a real-time database containing NFL scores, and it would retrieve the relevant information from this database to answer questions about the game scores.
How does RAG change the way we use LLMs?
-RAG changes the way we use LLMs by shifting from using them as knowledge bases to using them as reasoning tools that understand natural language. The LLMs are augmented with up-to-date data from a controlled data source, allowing them to provide more accurate and relevant responses.
What are some benefits of using RAG with LLMs?
-Some benefits include avoiding the need to retrain language models with updated data, providing a source for the information so it can be validated, and allowing the model to accurately state when it does not have an answer based on the provided data.
What are some concerns or challenges with implementing RAG?
-Concerns with implementing RAG include ensuring that the data augmented into the model is good and relevant, developing an efficient and accurate way to retrieve relevant information quickly to avoid latency, and making sure the model uses the augmented data correctly.
How does RAG handle situations where the data source does not have an answer?
-RAG allows the LLM to state that it does not have an answer based on the provided data, rather than giving a potentially incorrect or misleading answer.
What is the role of a vector database in the RAG process?
-A vector database is used to vectorize the prompt and find documents with similar vector representations, which are then returned as relevant data for the LLM to use in generating a response.
How can developers learn more about using RAG and LLMs effectively?
-Developers can learn more about using RAG and LLMs effectively through resources like the free guide 'How to Use Chat GPT at Work' provided by HubSpot, which includes expert insights and practical applications.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифПосмотреть больше похожих видео

W2 5 Retrieval Augmented Generation RAG

Retrieval Augmented Generation - Neural NebulAI Episode 9
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

RAG vs. Fine Tuning

What is Agentic RAG?

[RAG Series #1] Hanya 10 menit paham bagaimana konsep dibalik Retrieval Augmented Generation (RAG)
5.0 / 5 (0 votes)
