[RAG Series #1] Hanya 10 menit paham bagaimana konsep dibalik Retrieval Augmented Generation (RAG)
Summary
TLDRIn this video, Daniel introduces Retrieval-Augmented Generation (RAG), a technique designed to enhance Large Language Models (LLMs) by incorporating external information such as PDFs, images, and audio. RAG addresses key LLM limitations, including hallucinations, time-sensitivity, and privacy concerns, by providing factual support and real-time updates without retraining the model. The process involves indexing, chunking, retrieving relevant information, and augmenting prompts to generate accurate responses. RAG is highly adaptable and traceable, making it useful for tasks like question answering and summarization. Daniel concludes with an analogy of RAG as an 'open-book exam,' where external sources improve LLM accuracy and reliability.
Takeaways
- 😀 Rag (Retrieval Augmented Generation) enhances large language models (LLM) by incorporating external information from various sources like PDFs, images, or audio.
- 😀 Rag addresses several issues with LLMs, such as hallucinations, timeliness problems, and limited access to private or recent data.
- 😀 Rag helps overcome the hallucination problem by providing factual support from external sources, reducing the likelihood of irrelevant or incorrect responses from LLMs.
- 😀 The timeliness issue is solved by feeding recent documents into the LLM, ensuring up-to-date information even if the model itself was trained on older data.
- 😀 Rag also tackles the limitation of LLMs being trained primarily on publicly available datasets, helping answer queries about private or sensitive data.
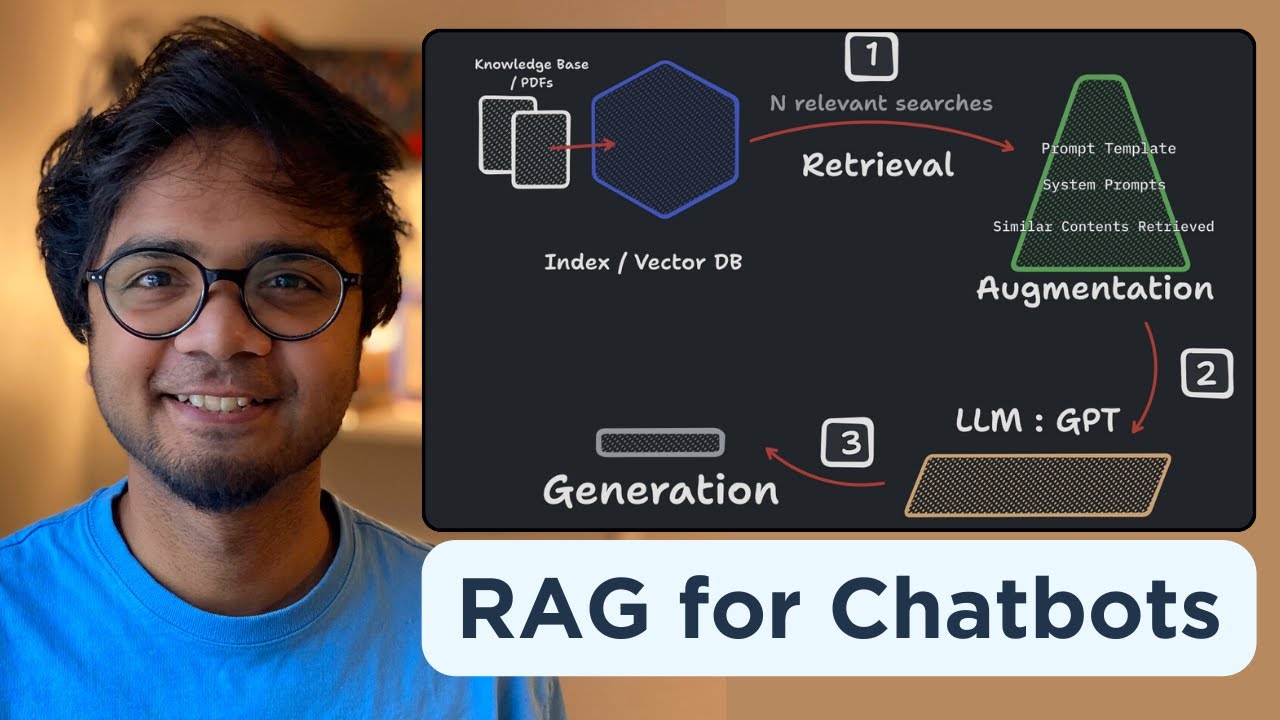
- 😀 The Rag process involves three main components: indexing, retrieval, and generation, where external data is processed, searched for relevant information, and then used to generate a response.
- 😀 Indexing involves cleaning, extracting, and chunking data from external sources to make it usable for the model. This ensures efficient data processing and retrieval.
- 😀 During retrieval, the system searches for the most relevant chunks of data to the user's query, ensuring the best possible match for accurate results.
- 😀 The augmentation step combines the retrieved data with a prompt, creating a more contextually relevant input for the LLM to generate a fact-based response.
- 😀 Rag enhances model accuracy, adaptability, and explainability by providing sources for answers, allowing for easy updates without needing to retrain the entire model.
Q & A
What is Retrieval-Augmented Generation (RAG)?
-RAG is a technique used to improve large language models (LLMs) by integrating external information from sources like PDFs, images, or videos. This information is used to enhance the responses generated by the LLM, ensuring that they are factually accurate.
Why is RAG important for large language models?
-RAG is important because it helps overcome limitations in LLMs, such as hallucination (generating factually incorrect answers), time sensitivity (outdated data), and inability to handle private or sensitive information. By incorporating external sources, RAG ensures more accurate and timely responses.
What are the common problems in LLMs that RAG solves?
-RAG addresses three key problems: hallucination (when LLMs generate plausible but incorrect responses), timeliness issues (when LLMs provide outdated information), and data privacy concerns (LLMs may not handle private or sensitive data well).
How does the indexing process work in RAG?
-In the indexing process, external sources like PDFs are cleaned, and relevant data is extracted. The information is then formatted into a usable structure, such as markdown, for easier retrieval during the query stage.
What is the retrieval stage in the RAG process?
-During the retrieval stage, a user’s query is compared to the indexed information. The system retrieves the most relevant chunks of data, which are then used to generate a response.
What is the role of the generation stage in RAG?
-The generation stage combines the relevant information retrieved from external sources with the model's own knowledge to create a final response. This helps ensure that the model’s answers are grounded in factual information.
What is chunking, and why is it necessary in the RAG process?
-Chunking is the process of breaking down large documents into smaller, manageable pieces (chunks). This is necessary because LLMs have limited input size, and focusing on specific chunks makes it easier to retrieve the most relevant information from a document.
How does RAG help reduce model hallucination?
-RAG reduces hallucination by providing the LLM with additional context and factual support from external sources. Instead of generating an answer based purely on probabilities, the model can refer to real data to improve the accuracy of its responses.
What are the key characteristics of RAG?
-The key characteristics of RAG include accuracy (relying on external sources for factual data), timeliness (updating models without retraining them), flexibility (easily updating external data), and traceability (knowing the source of the information used in the model’s answer).
How can RAG be applied in real-world scenarios?
-RAG can be applied in various fields such as question answering, summarization, and other tasks that require real-time factual support. By providing up-to-date and accurate information, RAG improves the usefulness and reliability of LLMs in these applications.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Retrieval Augmented Generation - Neural NebulAI Episode 9

What is a Vector Database? Powering Semantic Search & AI Applications

Introduction to Generative AI (Day 7/20) #largelanguagemodels #genai

W2 5 Retrieval Augmented Generation RAG

RAG vs. CAG: Solving Knowledge Gaps in AI Models
5.0 / 5 (0 votes)