Few-Shot Learning (1/3): Basic Concepts
Summary
TLDRIn this lecture, Assistant Professor Shusen Wang from Stevens Institute of Technology introduces few-shot learning, a method for classification or regression with minimal samples. He uses an animal identification game to illustrate how humans can quickly learn to distinguish between new entities from a few examples. The lecture contrasts few-shot learning with traditional supervised learning, emphasizing the 'learn to learn' approach. It discusses the importance of the support set for making predictions on new classes and introduces key concepts like 'K-way N-shot' learning. The talk also touches on meta-learning and its application in few-shot learning, using relatable examples and mentioning datasets like Omniglot and Mini-ImageNet for practical research.
Takeaways
- 📚 Few-shot learning is a method of classification or regression using a very limited number of samples.
- 👨🏫 Dr. Shusen Wang introduces few-shot learning with an example of distinguishing between Armadillos and Pangolins using just four images.
- 🧠 The challenge for computers in few-shot learning is to make accurate predictions with minimal training data, which is easier for humans.
- 🔑 Key terms introduced are 'support set' and 'query', where the support set is a small set of labeled samples used for making predictions at test time.
- 🤖 The goal of few-shot learning is not just to recognize objects but to 'learn to learn', understanding similarities and differences between objects.
- 🐇 Even if the model hasn't seen certain classes during training, like squirrels, it can identify similarities between new, unseen objects.
- 🦊 The model can make predictions about new, unseen classes by comparing a query image to a support set provided at test time.
- 📈 The accuracy of few-shot learning depends on the number of 'ways' (classes in the support set) and 'shots' (samples per class).
- 📊 As the number of ways increases, accuracy typically decreases, while increasing the number of shots improves accuracy.
- 🔍 The basic idea is to train a model to predict similarity, which can then be applied to unseen queries with the help of a support set.
- 📊 Two commonly used datasets for evaluating few-shot learning models are Omniglot, a hand-written character dataset, and Mini-ImageNet, a smaller version of ImageNet.
Q & A
What is few-shot learning?
-Few-shot learning is a machine learning approach where a model is trained to make classifications or predictions based on a very small number of samples.
How does the game with Armadillos and Pangolins illustrate few-shot learning?
-The game demonstrates the concept of few-shot learning by showing how humans can distinguish between two animals using only four images, highlighting the ability to learn from minimal examples.
What is the challenge for computers in few-shot learning?
-The challenge for computers in few-shot learning is that the small number of samples is insufficient for training a deep neural network, which typically requires large datasets.
What are the key terms 'support set' and 'query' in the context of few-shot learning?
-The 'support set' refers to a small set of labeled samples used for making predictions at test time, while a 'query' is an unseen sample that the model must classify using the information from the support set.
How is few-shot learning different from standard supervised learning?
-Few-shot learning differs from standard supervised learning in that it aims to train the model to understand similarities and differences between objects rather than recognizing specific objects from the training set.
What is meant by 'learning to learn' in meta-learning?
-'Learning to learn' in meta-learning refers to the ability of a model to adapt and learn from new tasks with minimal data by leveraging the knowledge acquired from previous learning experiences.
Why is recognizing a squirrel difficult for a model trained without that class?
-A model trained without the squirrel class will struggle to recognize it because it has not learned the characteristics of squirrels and lacks the necessary features to distinguish them from other objects.
What is the significance of the terms 'K-way' and 'N-shot' in few-shot learning?
-In few-shot learning, 'K-way' refers to the number of classes in the support set, while 'N-shot' indicates the number of samples per class. These terms help define the complexity of the learning task.
How does the prediction accuracy in few-shot learning relate to the number of ways and shots?
-The prediction accuracy in few-shot learning generally decreases as the number of ways (classes in the support set) increases and improves as the number of shots (samples per class) increases.
What is the role of a similarity function in few-shot learning?
-A similarity function in few-shot learning measures the similarity between two samples. It is used to compare the query image with samples in the support set to determine the most similar class for prediction.
Which datasets are commonly used for evaluating few-shot learning models?
-Omniglot and Mini-ImageNet are two widely used datasets for evaluating few-shot learning models. Omniglot contains hand-written characters from various alphabets, while Mini-ImageNet consists of natural images from 100 classes.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тариф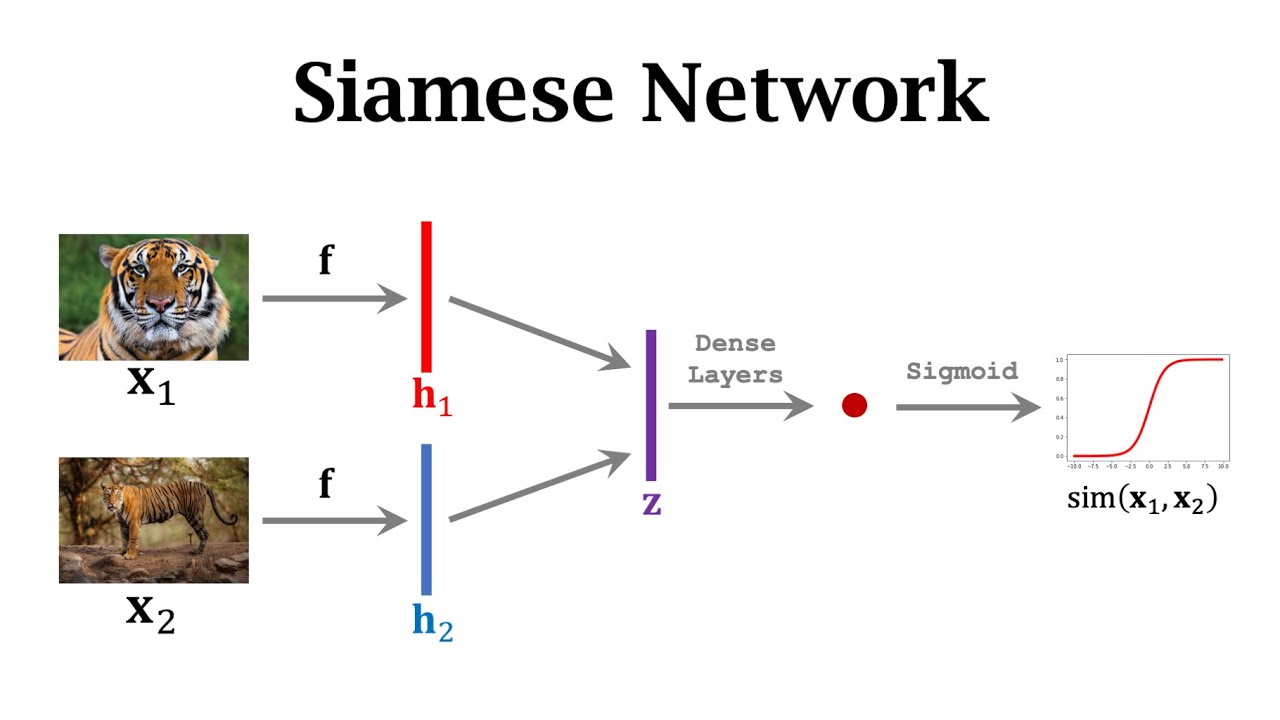




5.0 / 5 (0 votes)
