3. Learning untuk Klasifikasi dari MACHINE LEARNING
Summary
TLDRThis video script discusses machine learning, focusing on regression and classification processes. It explains how machine learning identifies patterns through regression and distinguishes differences using classification. The speaker highlights the challenges of handling multiple inputs in machine learning compared to simple linear regression and introduces gradient descent for optimization. The video also explains the classification process using logistic regression, the use of sigmoid functions for binary outcomes, and the challenges of ensuring model predictions are within a suitable range. Examples illustrate concepts like updating weights in both regression and classification tasks.
Takeaways
- 😀 There are two main tasks in machine learning: finding similarities (regression) and finding differences (classification).
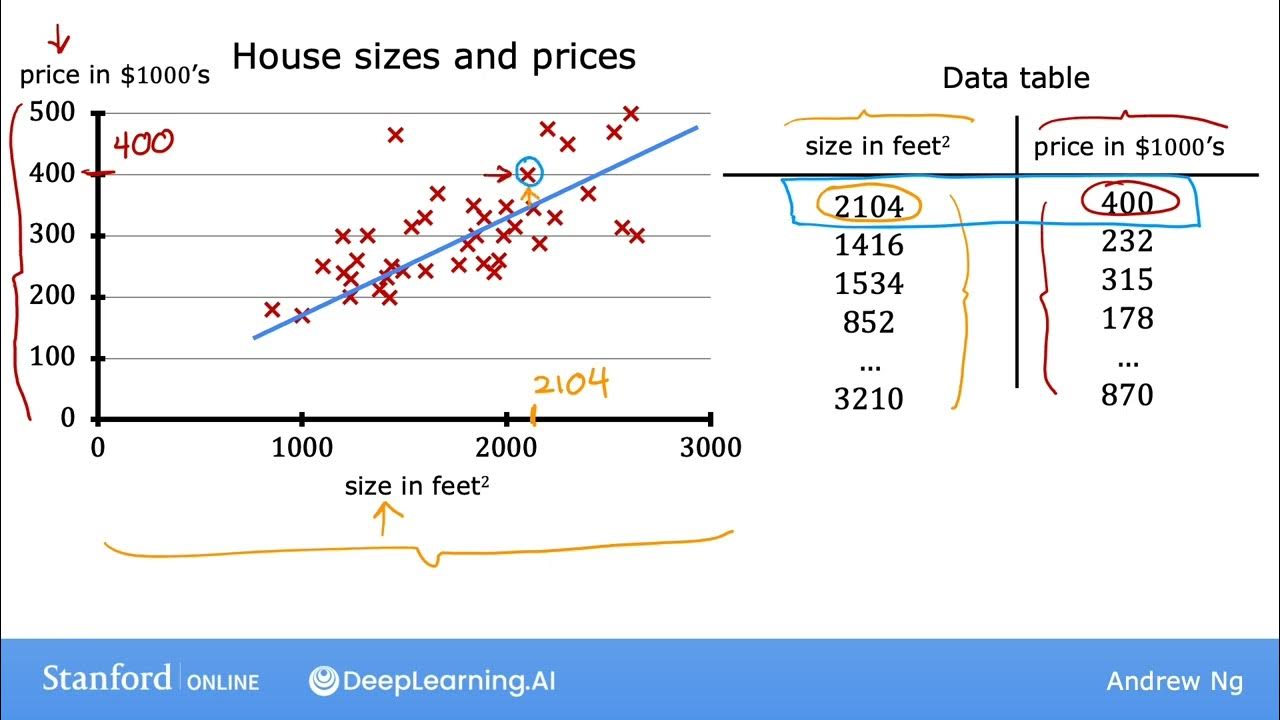
- 🤖 Regression in machine learning involves predicting a continuous outcome based on inputs.
- ⚙️ When dealing with multiple inputs (e.g., X1, X2, X3), machine learning models use corresponding weights (W1, W2, W3) to predict the output.
- 📊 In machine learning, loss functions are used to measure the difference between predicted and actual outputs, which guides the adjustment of weights and biases.
- 🔁 The gradient descent algorithm helps minimize the loss by adjusting weights and biases iteratively.
- 📐 Unlike simple linear regression learned in statistics, machine learning models can handle complex input data with many variables.
- 🟠 Classification tasks aim to separate data points into distinct categories, such as identifying patterns to distinguish between two different groups.
- 🚶♂️ The sigmoid function is used in classification tasks to map predictions to a range between 0 and 1, making it suitable for binary classification.
- 🔄 The process of classification in machine learning involves calculating a prediction (Y_hat), applying an activation function, and updating weights using gradient descent.
- 📉 By iterating through this process, the model improves its classification accuracy over time, reducing the overall loss function.
Q & A
What are the two main processes in machine learning as described in the script?
-The two main processes in machine learning mentioned are regression, which focuses on finding similarities, and classification, which involves identifying differences.
How does machine learning regression differ from traditional linear regression in statistics?
-Machine learning regression can handle multiple inputs and large datasets, making it more complex than traditional linear regression, which uses simpler formulas and is designed for fewer inputs.
What is the purpose of the cost function in machine learning?
-The cost function measures the difference between predicted and actual outputs, helping the model adjust its parameters to minimize errors and improve predictions.
Why is gradient descent important in machine learning?
-Gradient descent helps optimize the learning process by adjusting weights and biases in the model, gradually minimizing the cost function through successive iterations.
What challenge arises when dealing with multiple inputs in machine learning?
-When handling multiple inputs, the regression formula becomes much more complex, as each input needs its own weight, making the process more computationally intensive.
How does the classification process differ from regression in machine learning?
-In classification, the model is trained to distinguish between different classes (e.g., people from two different countries), whereas regression focuses on predicting continuous values.
What problem occurs when predicted values are significantly larger than expected in classification?
-When predicted values are too large, the loss function becomes excessively high, making it difficult for the model to learn effectively. This is because actual outputs are often constrained to a range like 0 or 1.
What is the sigmoid function, and why is it used in classification?
-The sigmoid function is a smooth curve that maps predicted values between 0 and 1. It ensures that predictions for classification problems remain within a realistic range, preventing extreme values.
How does updating weights and biases differ in classification compared to regression?
-While the process of updating weights and biases is similar, classification involves additional steps like calculating activation functions (e.g., sigmoid), making the updates slightly more complex.
Why is it important to continuously update weights and biases in a machine learning model?
-Continuous updates ensure that the model learns from its mistakes by gradually reducing the error between predictions and actual outcomes, improving its performance over time.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade Now



5.0 / 5 (0 votes)