Bucket options in Cloud Storage
Summary
TLDRIn this episode of 'Cloud Storage Bytes,' the focus is on the foundational role of 'buckets' in cloud storage. The video explains the necessity of creating a bucket for any data storage, emphasizing the importance of choosing a globally unique name, selecting an optimal location based on redundancy and user distribution, and deciding on a storage class that aligns with data accessibility and cost considerations. Four storage classes are introduced, catering to different availability and pricing needs, from standard for high availability to nearline, coldline, and archive for less frequent access. The episode invites viewers to explore more about cloud storage features.
Takeaways
- 📦 A cloud storage bucket is essential for storing any data in cloud services, as it serves as the foundational unit for all operations.
- 🔍 Creating a bucket requires three initial decisions: a globally unique name, a location, and a storage class.
- 🔒 The bucket's name must be unique and cannot be changed once set, so it's crucial to choose a relevant and useful name.
- 📍 Location selection for a bucket should be based on redundancy needs, primary user base, and expected first-time access speed.
- 🌐 There are three types of locations: region, dual-region, and multi-region, each offering different benefits in terms of latency, availability, and geographic distribution.
- 🛡️ Regions optimize latency and bandwidth for data consumers within the same region, while dual-regions offer geo-redundancy and higher availability.
- 🌍 Multi-regions are ideal for serving content outside the Google network and across large geographic areas, also providing high availability.
- 💼 The storage class of a bucket can be updated later but defaults to Standard if not specified, affecting availability, minimum storage duration, and pricing.
- 💰 Standard storage class offers the best availability at a slightly higher price, suitable for data served at a high rate with high availability.
- 🗂️ Nearline, Coldline, and Archive storage classes are for less frequently accessed data, with varying levels of availability and pricing based on access frequency and duration.
- 📚 Documentation is available to assist in making the best naming, location, and storage class decisions for specific needs.
- 🔄 The script encourages viewers to subscribe and engage for more insights into cloud storage features and operations.
Q & A
What is the primary purpose of a 'bucket' in Cloud Storage?
-A 'bucket' in Cloud Storage is a fundamental storage resource where all data must be stored in order to perform any operations with it.
What are the three initial decisions one must make when configuring a bucket?
-The three initial decisions are choosing a globally unique name, selecting a location, and determining the storage class.
Why is the name of a bucket important and what happens if it's changed?
-The bucket name is crucial as it needs to be globally unique and relevant for use. It cannot be changed once set, so careful consideration is required when choosing it.
What should guide the selection of a bucket's location?
-The location should be chosen based on redundancy options needed, the geographic location of primary users, and expected first-time byte access when caching is off.
What are the three types of locations available for a bucket in Cloud Storage?
-The three types of locations are region, dual-region, and multi-region, each offering different levels of latency, availability, and redundancy.
How does the choice of location affect the performance and availability of data in a bucket?
-Choosing a region optimizes latency and bandwidth for data consumers in the same region. Dual-region offers higher availability with geo-redundancy, and multi-region serves data consumers outside the Google network across large geographic areas.
What is the default storage class if none is selected during the initial configuration of a bucket?
-If no storage class is selected initially, the bucket will default to the Standard storage class.
What are the four different storage classes available in Cloud Storage, and what do they vary on?
-The four storage classes are Standard, Nearline, Coldline, and Archive. They vary in availability, minimum storage durations, and pricing for storage and access.
Which storage class should be used for data that requires high availability and is served at a high rate?
-The Standard storage class should be used for such data, as it offers the best availability, albeit at a slightly higher price.
How can one determine the appropriate storage class for infrequently accessed data?
-The choice depends on specific needs; Nearline is suitable for monthly access, Coldline for data accessed between monthly and yearly, and Archive for data needed about once a year.
What does the script suggest doing after learning about Cloud Storage configurations?
-The script suggests subscribing, liking the video, and expressing interest in further features of Cloud Storage for more detailed learning.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示

2022 | Resumo da Aula | 1ª Série | Matemática | Aula 10 - Unidades de Medida de Armazenamento de ...

Amazon S3 Explained in 10 Minutes

Module introduction

Computer Concepts - Module 3: Computer Hardware Part 1B (4K)
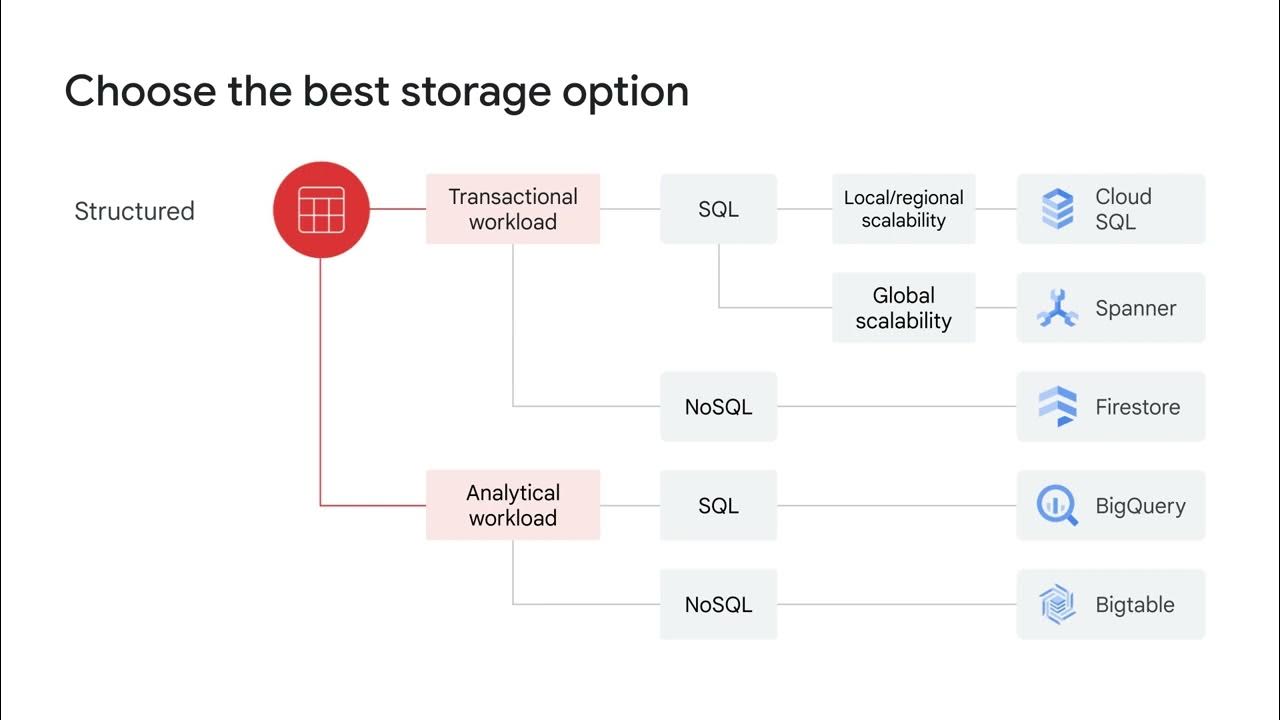
Structured and unstructured data storage

ARMAZENAMENTO EM NUVEM O QUE É E COMO USAR Gratuitamente!
5.0 / 5 (0 votes)
