Introduction to Generative AI (Day 7/20) #largelanguagemodels #genai
Summary
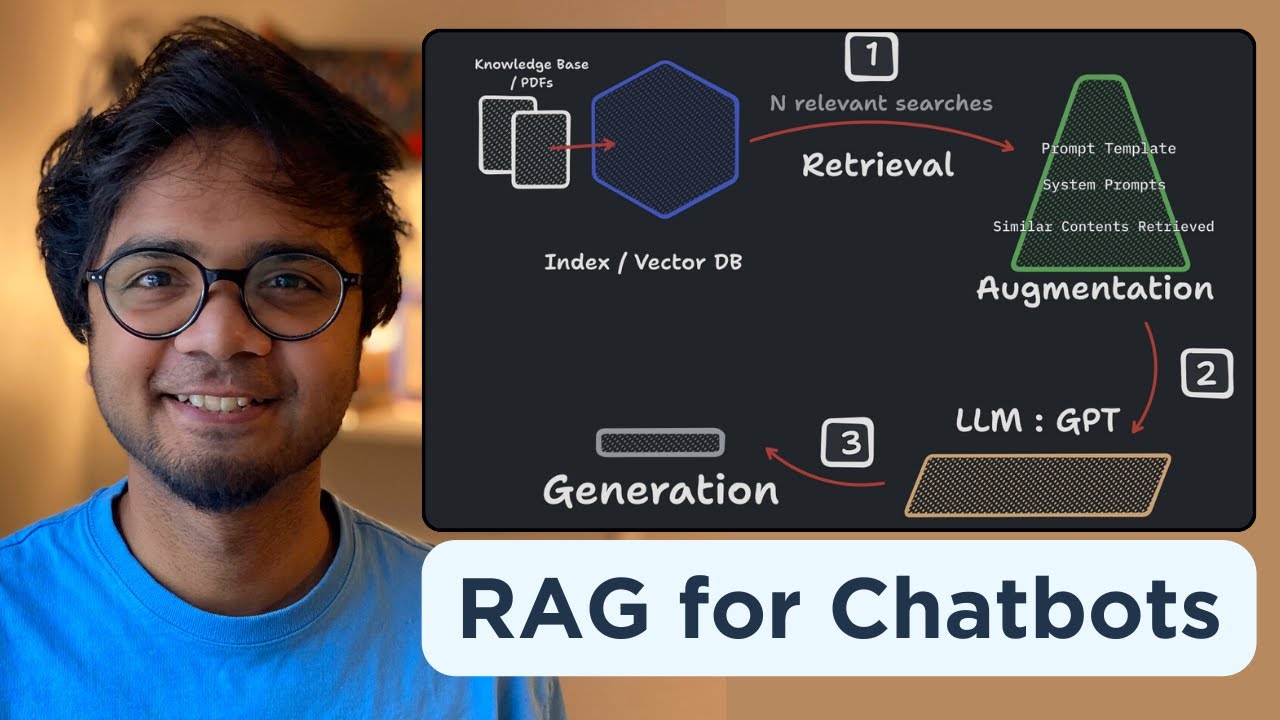
TLDRRetrieval Augmented Generation (RAG) is a prominent application of Large Language Models (LLMs) that enhances question-answering capabilities. It involves four stages: knowledge ingestion, where information is gathered and stored in a vector database; knowledge retrieval, finding relevant data for a given question; context augmentation, which adds this data to the question; and generation, where the LLM uses the augmented context to produce a more precise response. This method allows LLMs to provide better answers by leveraging additional information, akin to open-book question answering.
Takeaways
- 🧠 RAG stands for Retrieval-Augmented Generation and is a popular application of large language models (LLMs).
- 📚 The main concept of RAG is to enhance LLMs' ability to answer questions by providing them with additional information on unfamiliar topics.
- 🔍 The process starts with 'knowledge ingestion' where relevant information is gathered and broken down into smaller parts.
- 🗃️ These smaller parts are then stored in a 'vector database' or 'knowledge base' for quick retrieval.
- 🔎 'Knowledge retrieval' is the active phase where the LLM searches the knowledge base for the most relevant information to answer a new question.
- 📝 'Context augmentation' involves adding the retrieved information to the original question to provide additional context for the LLM.
- 💬 'Generation' is the final stage where the LLM uses the question and the augmented context to generate a more accurate and comprehensive answer.
- 🔑 The knowledge base is crucial as it contains the chunks of information that can be used to enhance the LLM's responses.
- 🤖 The LLM's performance in answering questions can be significantly improved by leveraging the knowledge base during the retrieval phase.
- 📈 RAG is particularly useful for open-book question answering, where external information is necessary to provide a complete answer.
- 🌐 The script highlights the importance of organizing and making information easily accessible for LLMs to enhance their capabilities.
Q & A
What is Retrieval-Augmented Generation (RAG)?
-Retrieval-Augmented Generation (RAG) is a technique used with large language models (LLMs) to enhance their ability to answer questions about topics they may not inherently know about by providing additional information.
How does RAG help improve the performance of LLMs?
-RAG improves LLM performance by allowing them to access external information to answer questions more accurately, similar to how humans might refer to an open book for answers.
What is the first stage in the RAG process called and what does it involve?
-The first stage is called 'knowledge ingestion,' which involves gathering and breaking down information from various sources like PDFs or websites into smaller parts and storing them in a vector database, also known as a knowledge base.
What role does the knowledge base play in the RAG process?
-The knowledge base serves as a repository for the information gathered during the knowledge ingestion stage, which can be searched and retrieved to assist in answering questions.
Can you explain the 'knowledge retrieval' stage in RAG?
-Knowledge retrieval is the active phase of RAG where the LLM searches the knowledge base for the most relevant information chunks that can help answer a new question from the user.
What is context augmentation in the RAG process?
-Context augmentation is the process of appending the retrieved information chunks from the knowledge base to the user's question, providing additional context for the LLM to generate a more accurate answer.
What happens during the 'Generation' stage of RAG?
-In the Generation stage, the LLM is provided with the original question along with the additional context retrieved from the knowledge base, and it uses this information to generate a comprehensive and accurate answer.
How does RAG differ from traditional LLMs that do not use external information?
-Traditional LLMs rely solely on their pre-trained knowledge, while RAG-enhanced LLMs can access and incorporate external information to provide more accurate and informed responses.
What types of sources can be included in the knowledge ingestion phase of RAG?
-Sources for knowledge ingestion can include PDFs, websites, and any other form of digital text that contains relevant information to answer potential questions.
How does the vector database in RAG help with information retrieval?
-The vector database in RAG organizes information into vectors, which allows for efficient searching and retrieval of the most relevant information chunks when answering questions.
What challenges might RAG face in terms of integrating external information?
-Challenges for RAG may include ensuring the accuracy and relevance of the external information, as well as the computational efficiency of searching and retrieving information from the vector database.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

Beyond the Hype: A Realistic Look at Large Language Models • Jodie Burchell • GOTO 2024

[RAG Series #1] Hanya 10 menit paham bagaimana konsep dibalik Retrieval Augmented Generation (RAG)
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Llama-index for beginners tutorial

RAG From Scratch: Part 1 (Overview)

What is Retrieval-Augmented Generation (RAG)?
5.0 / 5 (0 votes)
