What is a Vector Database? Powering Semantic Search & AI Applications
Summary
TLDRThis video explains the concept of vector databases, highlighting how they store and retrieve unstructured data like images, text, and audio. Unlike traditional relational databases, vector databases use mathematical vectors to represent data, capturing semantic similarities between items. By employing embedding models such as Clip for images or GloVe for text, data is transformed into vector embeddings with multiple dimensions. The video also covers the importance of vector indexing for efficient search and introduces retrieval-augmented generation (RAG), where vector databases support large language models by retrieving relevant information based on semantic similarity.
Takeaways
- 😀 Vector databases store unstructured data, such as images, text, and audio, as mathematical vector embeddings.
- 😀 A traditional relational database stores data in structured formats like binary image files and metadata, but it struggles to capture the semantic context of unstructured data.
- 😀 The semantic gap refers to the disconnect between how computers store data and how humans understand it, which relational databases can't address effectively.
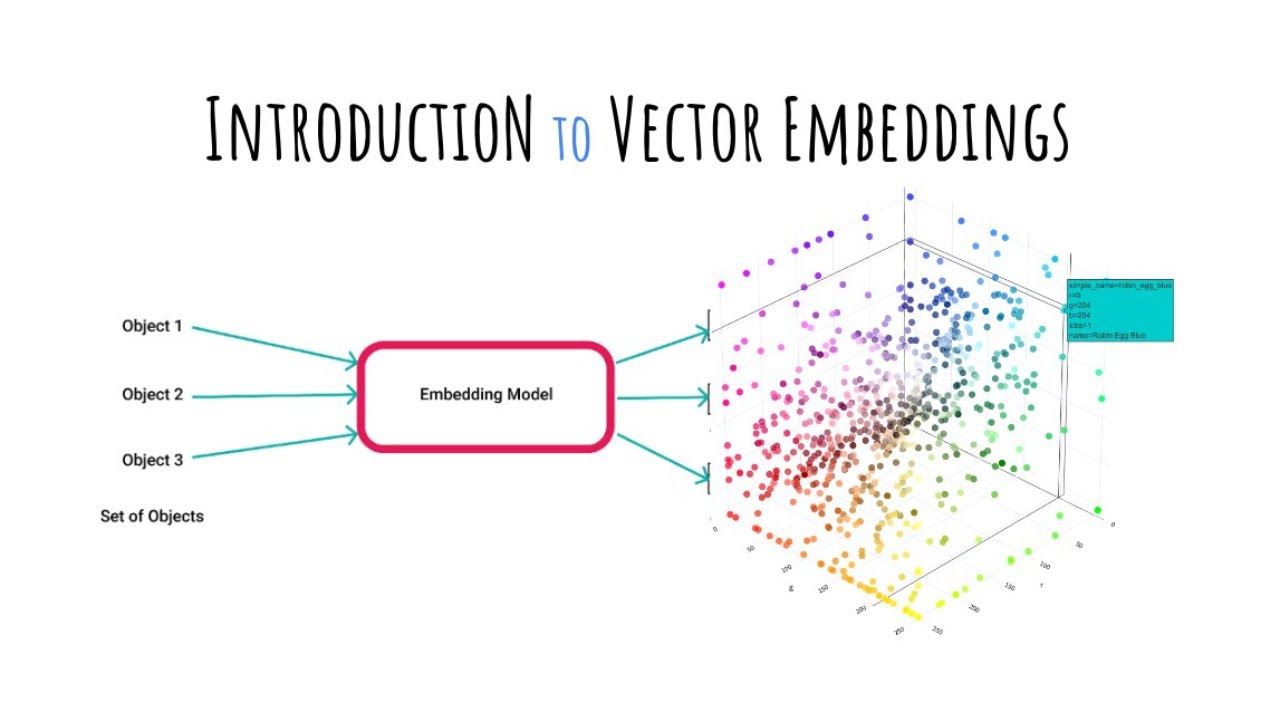
- 😀 Vector embeddings are arrays of numbers that represent the essence of data, with similar items placed close together in vector space.
- 😀 Similarity searches in vector databases work by comparing vector embeddings, allowing for more nuanced queries, such as finding images with similar color palettes or landscapes.
- 😀 Vector embeddings are created by embedding models that are trained on large datasets, like CLIP for images, GloVe for text, and Wav2Vec for audio.
- 😀 Embedding models process data through multiple layers, extracting increasingly abstract features that help generate high-dimensional vector embeddings.
- 😀 In a vector database, vector indexing techniques like Approximate Nearest Neighbor (ANN) algorithms improve search efficiency by quickly finding close vectors, even in large databases.
- 😀 Vector indexing methods, such as HNSW (Hierarchical Navigable Small World) and IVF (Inverted File Index), trade slight accuracy for faster search speeds.
- 😀 Retrieval-Augmented Generation (RAG) uses vector databases to store chunks of documents as embeddings, enabling faster and more semantic searches to assist large language models in generating responses.
Q & A
What is a vector database?
-A vector database is a type of database that stores unstructured data, such as images, text, or audio, as vector embeddings—mathematical representations that capture the semantic essence of the data.
How is data stored in a traditional relational database?
-In a traditional relational database, data is stored in structured formats, typically tables, and can include binary data (e.g., images), metadata (e.g., file format, creation date), and tags (e.g., 'sunset', 'landscape').
What is the 'semantic gap' in traditional databases?
-The 'semantic gap' refers to the difference between how data is stored in traditional databases (as structured fields) and how humans interpret and understand data (in its semantic context). This gap makes it difficult to perform nuanced queries based on features like color palette or scene content.
How do vector databases overcome the semantic gap?
-Vector databases overcome the semantic gap by representing data as vector embeddings—arrays of numbers that capture the semantic essence of the data, making it easier to perform searches based on similarity rather than simple metadata or tags.
What are vector embeddings?
-Vector embeddings are arrays of numbers that represent the key features of data, such as a mountain's elevation or a sunset's color palette, allowing for mathematical comparison and similarity searches in a vector database.
How are vector embeddings generated?
-Vector embeddings are generated through embedding models, which are trained on massive datasets. These models process data through multiple layers, extracting progressively more abstract features such as edges for images or words and context for text.
What are some examples of embedding models?
-Examples of embedding models include Clip (for images), GloVe (for text), and Wav2vec (for audio). Each model is specialized for different types of data and extracts relevant features for creating vector embeddings.
How are vector embeddings compared in a vector database?
-Vector embeddings are compared using mathematical operations that determine the proximity of vectors in vector space. Items with similar semantic features will have vectors close together, while dissimilar items will be farther apart.
What is vector indexing, and why is it important?
-Vector indexing is a process used to speed up similarity searches in large vector databases. It involves using algorithms like approximate nearest neighbors (ANN) to quickly find vectors that are likely to be close to a query vector, improving search efficiency.
How do ANN algorithms like HNSW and IVF improve search speed?
-ANN algorithms like HNSW (Hierarchical Navigable Small World) and IVF (Inverted File Index) trade a small amount of accuracy for faster search speeds by organizing the vectors into layers or clusters, allowing for quicker retrieval of similar vectors.
What is Retrieval-Augmented Generation (RAG), and how do vector databases play a role in it?
-Retrieval-Augmented Generation (RAG) is a process where vector databases store chunks of documents or knowledge as embeddings. When a user asks a question, the system retrieves relevant text chunks by comparing vector similarities and uses them to generate a response through a language model.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes





5.0 / 5 (0 votes)
