DISTRIBUIÇÃO NORMAL ESTATÍSTICA
Summary
TLDREl guion del video proporciona una explicación detallada y práctica del concepto de distribución normal, uno de los pilares fundamentales en estadística y ciencia de datos. El presentador, Jefferson, creador del canal, se enfoca en enseñar cómo calcular y interpretar la distribución normal para análisis de datos y modelado predictivo. Se ilustra cómo determinar la probabilidad de seleccionar una persona de una altura específica dada la media y el desvio estándar de una muestra. Además, se muestra cómo realizar estos cálculos en Python, utilizando paquetes estadísticos y gráficos para visualizar los datos y la distribución normal, facilitando así una comprensión clara y aplicable del tema.
Takeaways
- 👋 El script es una presentación sobre la distribución normal en estadística por parte de Jefferson, creador del canal.
- 📚 Se discute que la distribución normal es un concepto fundamental en análisis de datos y modelado predictivo en machine learning.
- 📉 La distribución normal también se conoce como distribución gaussiana, curva de sino o distribución de sino.
- 🔍 Se utiliza para determinar la probabilidad de que un valor se encuentre dentro de un rango específico, como la altura media de las personas.
- 📊 Se menciona la importancia de entender medidas estadísticas como la moda, mediana y desviación estándar para interpretar la distribución normal.
- 🤖 Se explica cómo calcular y representar la distribución normal en Python, incluyendo el uso de paquetes como pandas, numpy, y matplotlib.
- 📈 Se ilustra cómo generar un histograma y una curva de sino para visualizar los datos y su distribución normal.
- 📝 Se da un ejemplo práctico de cómo calcular la probabilidad de que una persona tenga una altura entre 1,55 m y 1,75 m usando la fórmula de la función de densidad de probabilidad.
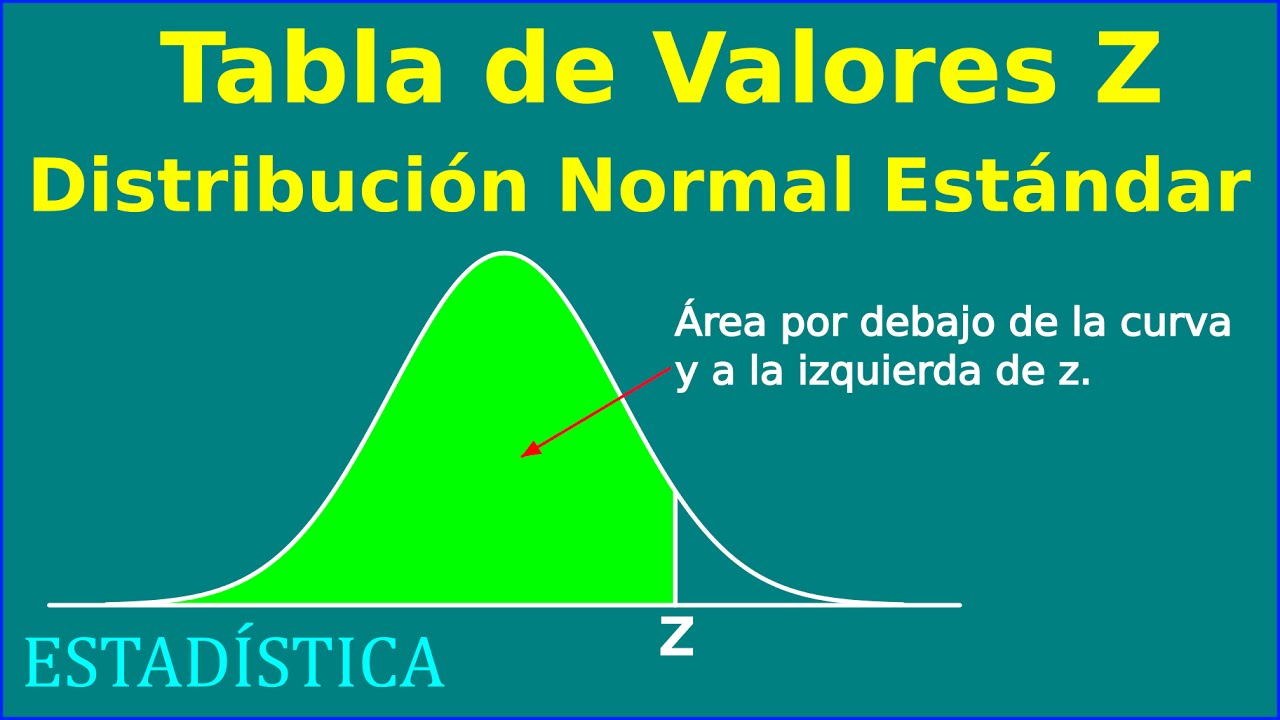
- 📚 Se menciona la utilización de la tabla de Z-scores para encontrar la probabilidad de un intervalo específico.
- 💡 Se resalta que la curva de sino es simétrica y que la media es el pico más alto de la curva, representando el centro de la distribución.
- 🔢 Se muestra cómo calcular la probabilidad de un intervalo de alturas en Python usando la función `norm.cdf` del paquete `scipy.stats`.
Q & A
¿Qué es la distribución normal y por qué es importante en estadística y ciencia de datos?
-La distribución normal, también conocida como distribución gaussiana o curva de sino, es una distribución de probabilidad continua que es utilizada ampliamente en estadística y ciencia de datos. Es importante porque muchos datos numéricos en la naturaleza siguen una distribución normal. Permite calcular la probabilidad de que un valor se encuentre dentro de un rango específico, lo cual es fundamental en análisis de datos y en la creación de modelos predictivos en machine learning.
¿Qué es un histograma y cómo se relaciona con la distribución normal?
-Un histograma es una representación gráfica de los datos que se utiliza para mostrar la distribución de una variable. Se relaciona con la distribución normal porque, a través de un histograma, se puede visualizar si los datos siguen una distribución normal o no. Además, se puede superponer una curva de sino para comparar visualmente la distribución de los datos con una distribución normal teórica.
¿Cómo se calcula el desvio estándar y qué representa?
-El desvio estándar es una medida de la variabilidad o dispersión de los datos en torno a la media. Se calcula como la raíz cuadrada de la varianza y representa el promedio de las distancias de cada punto de datos a la media. Un desvio estándar más grande indica que los datos están más dispersos, mientras que uno más pequeño indica que están más concentrados alrededor de la media.
¿Qué es el z-score y cómo se utiliza en la distribución normal?
-El z-score es una medida estándar que indica cuánto se desvía un valor de una distribución normal en términos de desviaciones estándar. Se calcula dividiendo la diferencia entre el valor y la media por el desvio estándar. Se utiliza para comparar los valores de datos individuales con la distribución normal y para calcular probabilidades asociadas a intervalos de valores.
¿Cómo se interpreta la fórmula de densidad de probabilidad en el contexto de la distribución normal?
-La fórmula de densidad de probabilidad para la distribución normal es una función matemática que describe cómo se distribuyen las probabilidades de los diferentes valores dentro de la distribución. Aunque no es necesario memorizar la fórmula, es importante entender que involucra el valor de x (valor a evaluar), la media (μ) y el desvio estándar (σ), y se utiliza para calcular la probabilidad de que un valor específico oce en la distribución.
¿Cómo se utiliza la tabla de z-scores para encontrar probabilidades en una distribución normal?
-La tabla de z-scores es una herramienta que relaciona z-scores con probabilidades acumuladas. Para encontrar la probabilidad de un intervalo de valores en una distribución normal, se identifican los z-scores correspondientes a los límites del intervalo en la tabla. Luego, se utiliza la diferencia entre las probabilidades acumuladas para calcular la probabilidad del intervalo deseado.
¿Qué es el paquete 'numpy' y cómo se utiliza en el análisis de datos en Python?
-El paquete 'numpy' es una biblioteca de Python que proporciona herramientas para el cálculo numérico y el manejo de arrays multidimensionales. Se utiliza en el análisis de datos para realizar operaciones matemáticas avanzadas, como el cálculo de la media, el desvio estándar y otras estadísticas descriptivas, así como para manipular y procesar grandes conjuntos de datos de manera eficiente.
¿Cómo se genera un histograma y una curva de sino en Python utilizando el paquete 'matplotlib'?
-Para generar un histograma y una curva de sino en Python, se utiliza el paquete 'matplotlib' junto con 'numpy'. Se crea un objeto 'figure' y se utilizan los métodos 'hist' para generar el histograma y 'plot' para superponer la curva de sino. Se pueden ajustar los parámetros como el número de 'bins' para personalizar la apariencia del histograma.
¿Qué es el método 'norm.cdf' en Python y cómo se utiliza para calcular probabilidades en una distribución normal?
-El método 'norm.cdf' es una función del paquete 'scipy.stats' que calcula la función de distribución acumulada (CDF) para una distribución normal. Se utiliza para encontrar la probabilidad de que una variable aleatoria normal se encuentre por debajo de un valor específico. Se llama a esta función con los parámetros de la media, el desvio estándar y el límite superior del intervalo de interés.
¿Cómo se calcula la probabilidad de que una persona tenga una altura entre 1.55 m y 1.75 m si la media es 1.65 m y el desvio estándar es 0.08 m?
-Para calcular esta probabilidad, se utilizan los z-scores correspondientes a las alturas de 1.55 m y 1.75 m, se encuentran en la tabla de z-scores o se calcula utilizando el método 'norm.cdf' en Python. Se determina la probabilidad acumulada para cada z-score y se resta una de la otra para obtener la probabilidad del intervalo (1.55 m, 1.75 m).
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenant




5.0 / 5 (0 votes)
