Building the World's Largest RAG for Knowledge Management @ CVS Health
Summary
TLDRIn this talk, Eric Whitman, Director of Machine Learning at CVS Health, discusses the challenges of building an enterprise-scale retrieval-augmented generation (RAG) system. He emphasizes the need for semantic search and natural language processing to improve knowledge retrieval within the company. Highlighting CVS Health’s vast, dynamic knowledge sources, Eric outlines the process of ingesting, structuring, and optimizing data for efficient search. He also addresses the technical infrastructure, such as microservices and containerization, necessary for scaling. Ultimately, the talk emphasizes balancing cost, speed, and quality while considering team structure and governance to ensure successful system deployment and sustainability.
Takeaways
- 😀 **RAG System Overview**: Building a scalable Retrieval-Augmented Generation (RAG) system requires a well-designed architecture and a focus on unifying and simplifying search for large organizations with complex knowledge sources.
- 😀 **Challenges with Large Scale**: Enterprises like CVS Health face challenges such as handling millions of documents, dynamic data sources, and access control for sensitive information, which complicate traditional RAG architectures.
- 😀 **Simplifying Search at CVS**: The goal is to reduce manual, time-consuming search processes by integrating semantic search and natural language processing to create a unified search experience across diverse data sources.
- 😀 **MVP Focus**: For an MVP, CVS focuses on three key knowledge sources: technical documentation, IT policy, and general policy documents, each of which has unique integration and connectivity needs.
- 😀 **Custom Data Pipelines**: CVS builds custom data pipelines for each source, normalizing, chunking, and vectorizing documents before storing them in a vector database to facilitate more efficient searches.
- 😀 **Metadata is Essential**: Proper metadata handling enables filtering, access control, tracking document life cycles, and managing related content across various knowledge sources, enhancing the overall system’s effectiveness.
- 😀 **Change Data Capture (CDC)**: To keep documents up-to-date, CVS employs CDC mechanisms to track document creation, modification, and deletion, ensuring the vector store mirrors changes in the source systems.
- 😀 **Scaling Challenges**: The system needs to balance cost, speed, and quality while ensuring that large data volumes don’t overwhelm the infrastructure. Microservices are used to maintain flexibility and enable faster iteration.
- 😀 **Performance Evaluation**: Continuous performance evaluation is critical. CVS uses manual, automated, and LLM-based tracking to monitor relevance and ensure the system improves over time without breaking under the load of new data.
- 😀 **Building with Flexibility**: Developing systems with a platform mindset—modular components and microservices—allows for scaling and testing new models or technologies over time without disrupting the entire infrastructure.
Q & A
What is the main focus of the talk given by Eric Whitman?
-The talk focuses on the principles of building an enterprise-level retrieval-augmented generation (RAG) system, particularly at CVS Health, highlighting the challenges, strategies, and best practices in designing such systems.
What are the key challenges faced by CVS Health in managing its internal knowledge?
-CVS Health faces challenges such as a large number of employees, multiple knowledge sources, complex and unstructured data, manual search processes, and the difficulty in tracking and managing documents as they change over time.
What is the goal of improving the search process at CVS Health?
-The goal is to simplify the search process by introducing semantic search and natural language capabilities, and to unify the search interface so users can access information from various sources through one platform.
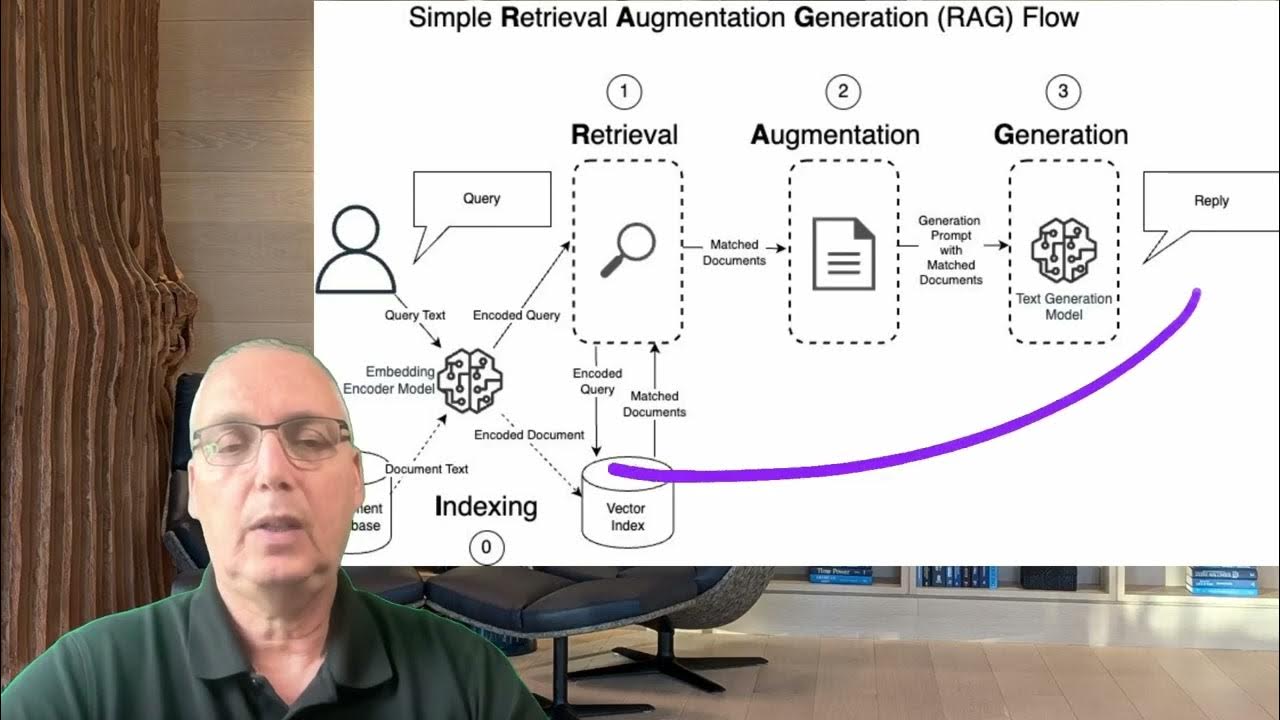
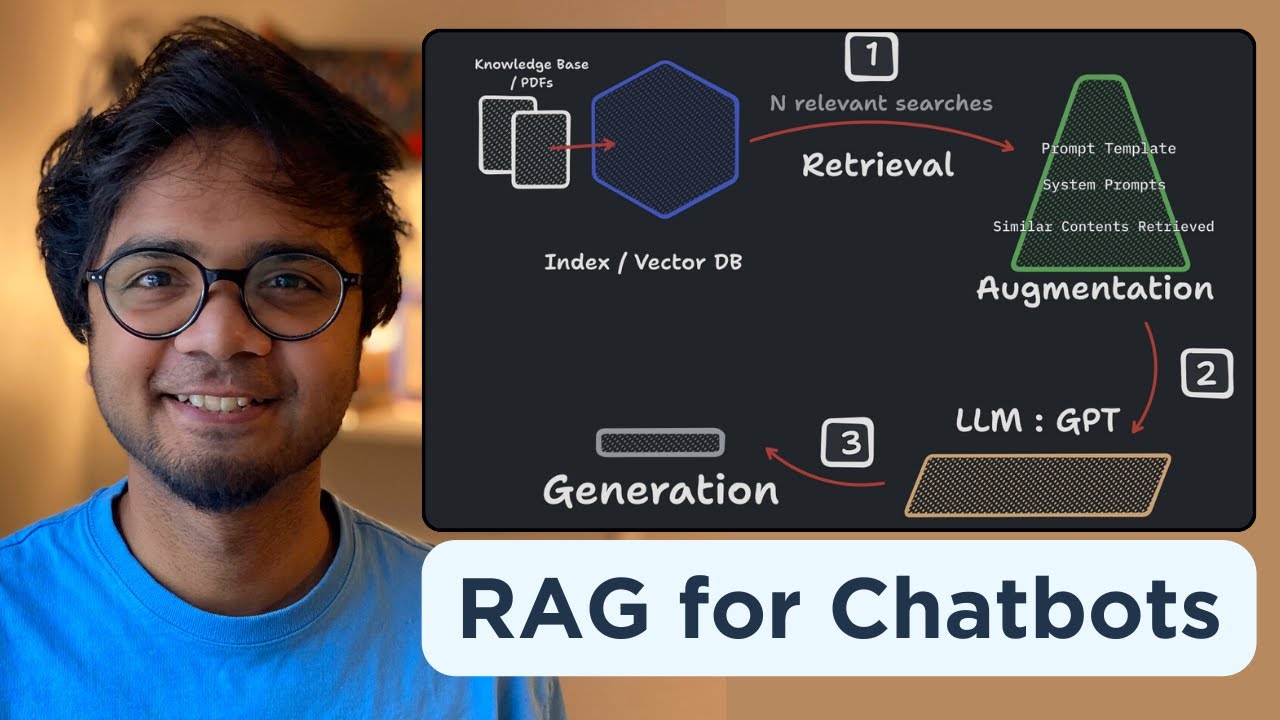
Why does the basic RAG architecture not scale for enterprise-level systems like CVS Health?
-The basic RAG architecture, which works with static, uniform content from a single source, is not scalable because it struggles with large document volumes, diverse data sources, and dynamic content in an enterprise environment.
How does CVS Health approach the ingestion of large volumes of documents for its RAG system?
-CVS Health builds custom data pipelines for different knowledge sources, ensuring fresh data is ingested continuously. These pipelines involve steps such as data normalization, chunking, vectorization, and integration with a vector store.
What are the key steps involved in the data pipeline for ingesting documents?
-The key steps include mapping content, metadata, and noise in documents, normalizing and serializing data, calculating document statistics, applying PII filters, chunking documents dynamically, vectorizing them, and storing them in a vector store.
What is the role of metadata in the document ingestion process?
-Metadata is crucial for filtering, managing access, mapping related content, and tracking document statistics. It helps normalize the structure across different data sources and enables better management of the data lifecycle.
What challenges does CVS Health face in maintaining a vector store for its knowledge sources?
-Challenges include ensuring that the vector store reflects updates to source documents, managing the lifecycle of documents (e.g., creation, modification, and deletion), and determining the frequency of updates to the vector store based on cost and performance considerations.
Why is chunking considered one of the most important steps in building a RAG system?
-Chunking is important because it divides large documents into smaller, more manageable pieces, which enhances retrieval accuracy and efficiency. High-quality chunking leads to better results in a RAG system by enabling more precise matches during searches.
What is the 'LLM Holy Trinity' mentioned in the talk, and why is it important?
-The 'LLM Holy Trinity' refers to the balance between cost, speed, and quality when building RAG systems. It’s important because finding the right balance ensures optimal performance, with cost and speed affecting system efficiency, and quality ensuring the relevance of the results.
How does CVS Health plan to evaluate the effectiveness of their RAG system?
-CVS Health plans to evaluate the RAG system using a combination of manual, automated, and LLM evaluation methods, tracking the relevancy and context of retrieved information over time to ensure continuous improvement and system performance.
What advice does Eric Whitman give for getting started with a RAG project?
-Eric Whitman advises starting with a discovery phase to map out knowledge sources, choosing 2-3 high-value sources to focus on initially, and building the system in a modular way to scale over time. He also emphasizes the importance of balancing optimization and software development.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes


5.0 / 5 (0 votes)
