Model in analytics | Predictive Modelling | Data Science | NADOS
Summary
TLDRThis video explains the process of creating and utilizing product models, emphasizing the transformation of raw data into well-organized formats using pipelines. It covers defining models through formulas, training them with historical data, and evaluating their accuracy. The speaker stresses that after creating a model, continuous performance checks and updates are necessary to maintain its effectiveness in real-world applications. The video highlights the importance of regular monitoring and fine-tuning to ensure a model’s predictions remain accurate over time, and discusses deployment as a critical final step to ensure business value.
Takeaways
- 😀 Data must be organized from its raw form into a structured format for use in modeling.
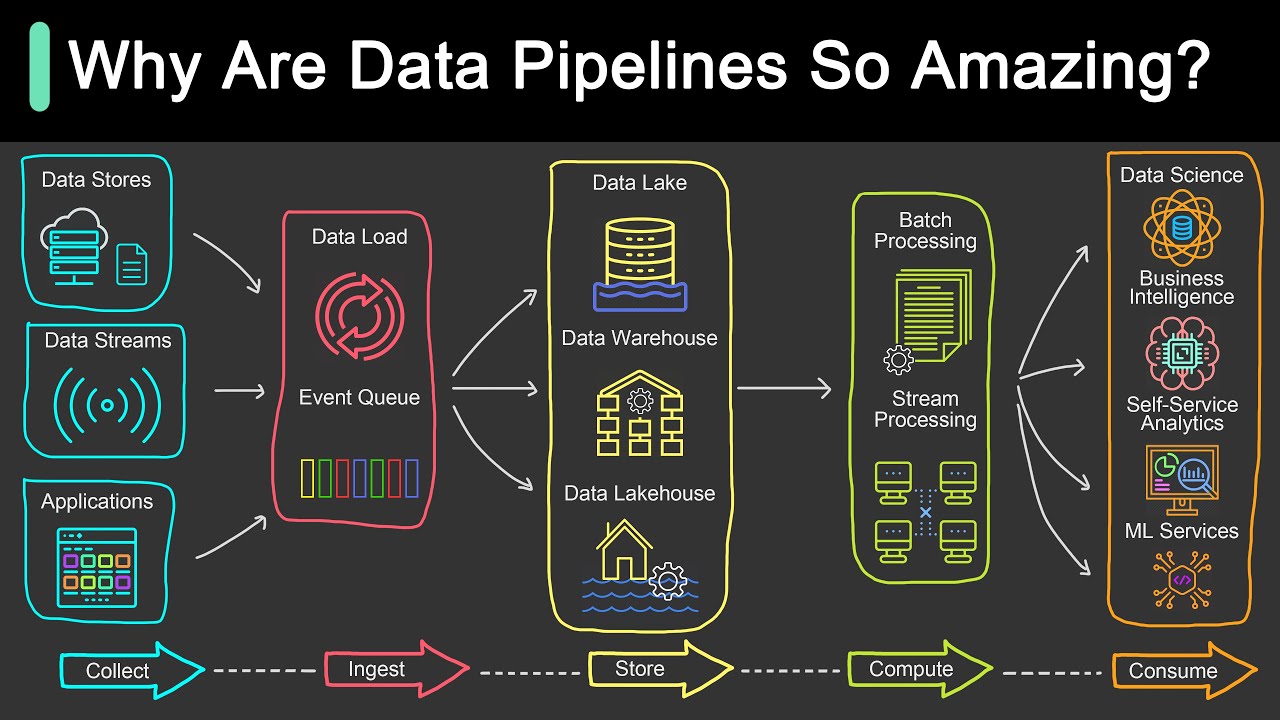
- 😀 Pipelines are essential for transforming and organizing data efficiently.
- 😀 A model is defined using a mathematical formula, which takes inputs and generates outputs.
- 😀 Historical data plays a crucial role in training models to ensure accurate predictions.
- 😀 Model performance must be continuously evaluated using real-world data to check for accuracy.
- 😀 Feedback from the deployed model helps in making adjustments to improve performance.
- 😀 After the model is trained, it is ready to be tested with new, unseen data.
- 😀 The deployment process includes applying the model in a real-world setting and monitoring its success.
- 😀 It is important to regularly update models as they can become outdated and less accurate over time.
- 😀 The responsibility of model creation doesn’t end with deployment; ongoing performance checks are necessary to maintain relevance and accuracy.
Q & A
What is the first step in the process of creating a product model?
-The first step is transforming unorganized data from various sources into a structured, well-organized format using data pipelines. This allows the model to process it effectively.
What role do data pipelines play in model development?
-Data pipelines help in organizing and preparing raw data by applying various actions to ensure the data is in a suitable format for the model, improving data quality for the model’s processing.
How is the model defined in the process?
-The model is defined by using mathematical formulas that process the input data to generate predictions or outputs, similar to how traditional programming functions work.
Why is historical data important for model training?
-Historical data is crucial because it allows the model to learn patterns and make accurate predictions based on past trends, which are essential for its performance when applied to new data.
What happens after a model is trained?
-After training, the model is tested with new data to evaluate its predictions and performance. The model must be checked for accuracy to ensure it functions as expected.
Why is performance evaluation critical after model training?
-Performance evaluation is essential because it determines whether the model is functioning correctly and if it meets the required standards. A model that performs poorly needs adjustments before it can be used in real-world scenarios.
What is the significance of model deployment?
-Model deployment involves putting the trained model into a live environment where it can be used for making predictions. This step also allows the model to continue evolving as it interacts with new data.
What is meant by model accuracy, and why is it important?
-Model accuracy refers to how well the model's predictions match the actual results. It’s important because a high accuracy ensures that the model is useful for making reliable predictions in real-world applications.
How does a model improve after being deployed?
-After deployment, the model improves by processing new data, learning from it, and adapting its predictions over time, which enhances its accuracy and relevance.
What should be done if a model's performance is poor after deployment?
-If a model's performance is poor, it should be reviewed and adjusted. Continuous monitoring and performance checks are necessary to make improvements and ensure the model’s effectiveness in solving business problems.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

Data Scientist vs Data Analyst vs Data Engineer: What's the difference?
What is Data Pipeline? | Why Is It So Popular?

How to Create Viral Tiktok Product Videos Using AI

Cara Membuat dan Membaca PENYAJIAN DATA - DIAGRAM BATANG, TABEL dan PIKTOGRAM

What is ETL Pipeline? | ETL Pipeline Tutorial | How to Build ETL Pipeline | Simplilearn

The Difference Between Digitization, Digitalization, and Digital Transformation
5.0 / 5 (0 votes)
