Intro to Supported Workloads on the Databricks Lakehouse Platform
Summary
TLDRThe video script introduces the Databricks Lakehouse platform as a solution for modern data warehousing challenges, supporting SQL analytics and BI tasks with Databrick SQL. It highlights the platform's benefits, including cost-effectiveness, scalability, and built-in governance with Delta Lake. The script also covers the platform's capabilities in data engineering, ETL pipelines, data streaming, and machine learning, emphasizing its unified approach to simplify complex data tasks and enhance data quality and reliability.
Takeaways
- 🏰 Databricks Lakehouse Platform supports data warehousing workloads with Databrick SQL and provides a unified solution for SQL analytics and BI tasks.
- 🚀 Traditional data warehouses are struggling to keep up with current business needs, leading to the rise of the Data Lakehouse concept for more efficient data handling.
- 💰 The platform offers cost-effective scalability and elasticity, reducing infrastructure costs by an average of 20 to 40 percent and minimizing resource management overhead.
- 🔒 Built-in governance with Delta Lake allows for a single copy of data with fine-grained control, data lineage, and standard SQL, enhancing data security and management.
- 🛠️ A rich ecosystem of tools supports BI on data lakes, enabling data analysts to use their preferred tools like DBT, 5tran, Power BI, or Tableau for better collaboration.
- 🔄 Databricks Lakehouse simplifies data engineering by providing a unified platform for data ingestion, transformation, processing, scheduling, and delivery, improving data quality and reliability.
- 🌐 The platform automates ETL pipelines and supports both batch and streaming data operations, making it easier for data engineers to implement business logic and quality checks.
- 📈 Databricks supports high data quality through its end-to-end data engineering and ETL platform, which automates pipeline building and maintenance.
- 📊 Delta Live Tables (DLT) is an ETL framework that simplifies the building of reliable data pipelines with automatic infrastructure scaling, supporting both Python and SQL.
- 🔧 Databricks Workflows is a managed orchestration service that simplifies the building of reliable data analytics and ML workflows on any cloud, reducing operational overhead.
- 🔮 The platform supports the data streaming workload, providing real-time analytics, machine learning, and applications in one unified platform, which is crucial for quick business decisions.
Q & A
What is the primary challenge traditional data warehouses face in today's business environment?
-Traditional data warehouses are no longer able to keep up with the needs of businesses due to their inability to handle the rapid influx of new data and the complexity of managing multiple systems for different tasks like BI and AI/ML.
How does the Databricks Lakehouse platform support data warehousing workloads?
-The Databricks Lakehouse platform supports data warehousing workloads through Databrick SQL and Databrick Serverless SQL, enabling data practitioners to perform SQL analytics, BI tasks, and deliver real-time business insights in a unified environment.
What are some key benefits of using the Databricks Lakehouse platform for data warehousing?
-Key benefits include the best price for performance, greater scale and elasticity, instant elastic SQL serverless compute, reduced infrastructure costs, and built-in governance supported by Delta Lake.
How does the Databricks Lakehouse platform address the challenge of managing data in a unified way?
-The platform allows organizations to unify all their analytics and simplify their architecture by using Databrick SQL, which helps in managing data with fine-grained governance, data lineage, and standard SQL.
What is the role of Delta Lake in the Databricks Lakehouse platform?
-Delta Lake plays a crucial role in maintaining a single copy of all data in existing data lakes, seamlessly integrated with Unity Catalog, enabling discovery, security, and management of data with fine-grained governance.
How does the Databricks Lakehouse platform support data engineering tasks?
-The platform provides a complete end-to-end data warehousing solution, enabling data teams to ingest, transform, process, schedule, and deliver data with ease. It automates the complexity of building and managing pipelines and running ETL workloads directly on the data lake.
What are the challenges faced by data engineering teams in traditional data processing?
-Challenges include complex data ingestion methods, the need for Agile development methods, complex orchestration tools, performance tuning of pipelines, and inconsistencies between various data warehouse and data lake providers.
How does the Databricks Lakehouse platform simplify data engineering operations?
-The platform offers a unified data platform with managed data ingestion, schema detection, enforcement, and evolution, paired with declarative auto-scaling data flow and integrated with a native orchestrator that supports all kinds of workflows.
What is the significance of Delta Live Tables (DLT) in the Databricks Lakehouse platform?
-Delta Live Tables (DLT) is an ETL framework that uses a simple declarative approach to building reliable data pipelines. It automates infrastructure scaling, supports both Python and SQL, and is tailored to work with both streaming and batch workloads.
How does the Databricks Lakehouse platform support streaming data workloads?
-The platform empowers real-time analysis, real-time machine learning, and real-time applications by providing the ability to build streaming pipelines and applications faster, simplified operations from automated tooling, and unified governance for real-time and historical data.
What are the main challenges businesses face in harnessing machine learning and AI?
-Challenges include siloed and disparate data systems, complex experimentation environments, difficulties in getting models served to a production setting, and the multitude of tools available that can complicate the ML lifecycle.
How does the Databricks Lakehouse platform facilitate machine learning and AI projects?
-The platform provides a space for data scientists, ML engineers, and developers to use data, derive insights, build predictive models, and serve them to production. It simplifies tasks with MLflow, AutoML, and built-in tools for model versioning, monitoring, and serving.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes
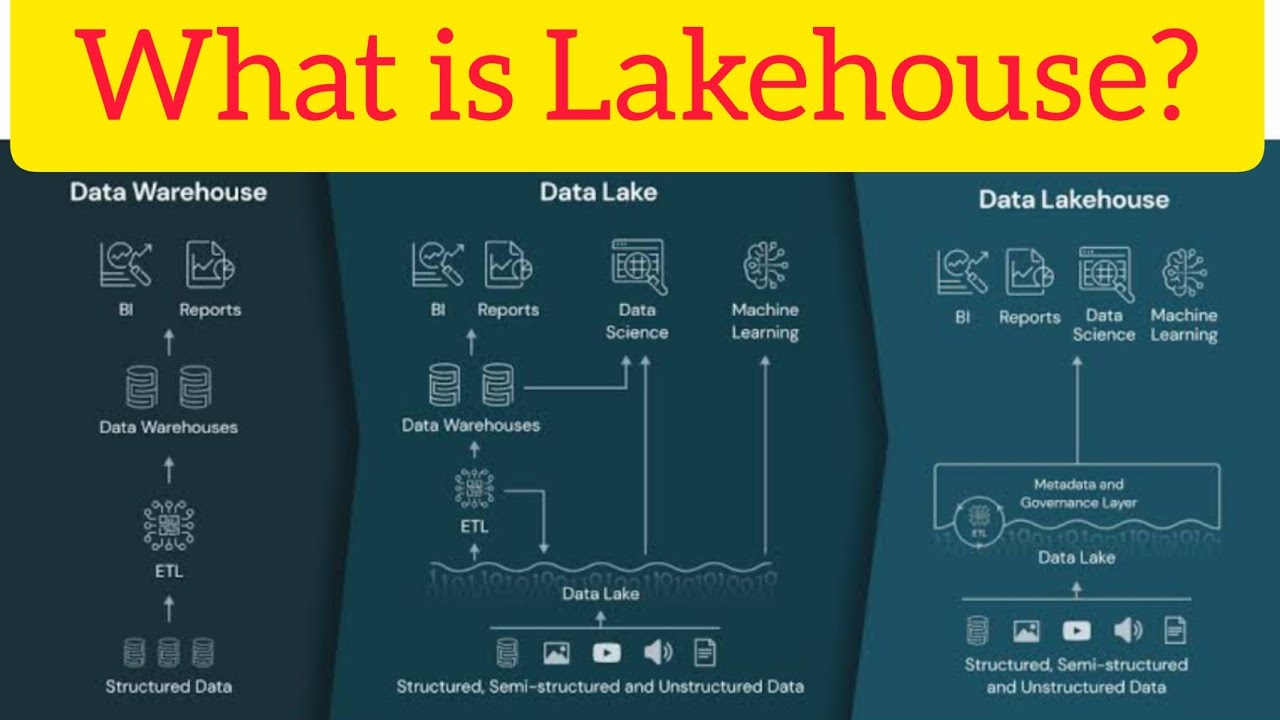
What is Lakehouse Architecture? Databricks Lakehouse architecture. #databricks #lakehouse #pyspark

02 What is Data Lakehouse & Databricks Data Intelligence Platform | Benefits of Databricks Lakehouse

Intro to Databricks Lakehouse Platform

🚀 GOOGLE Data Analyst Roadmap l For Absolute Beginners l 2 Months Strategy #dataanalytics #google
How I Would Learn SQL (If I Could Start Over in 2025) | #SQL Course 1

Intro To Databricks - What Is Databricks
5.0 / 5 (0 votes)
