Machine Learning Intro 4
Summary
TLDRThis video delves into the nuances of supervised learning, focusing on generalization and performance. It explains the importance of distinguishing between training error and generalization error, emphasizing that the latter is crucial for real-world model effectiveness. The script introduces techniques like train-test split and k-fold cross-validation to estimate and enhance model performance on unseen data, highlighting the goal of achieving a model that generalizes well beyond its training set.
Takeaways
- 📚 The video continues the discussion on supervised learning, focusing on generalization, performance, and techniques to measure estimator performance in real settings.
- 🔍 It introduces the concept of generalization performance, which is crucial for understanding how well a model will perform on unseen data.
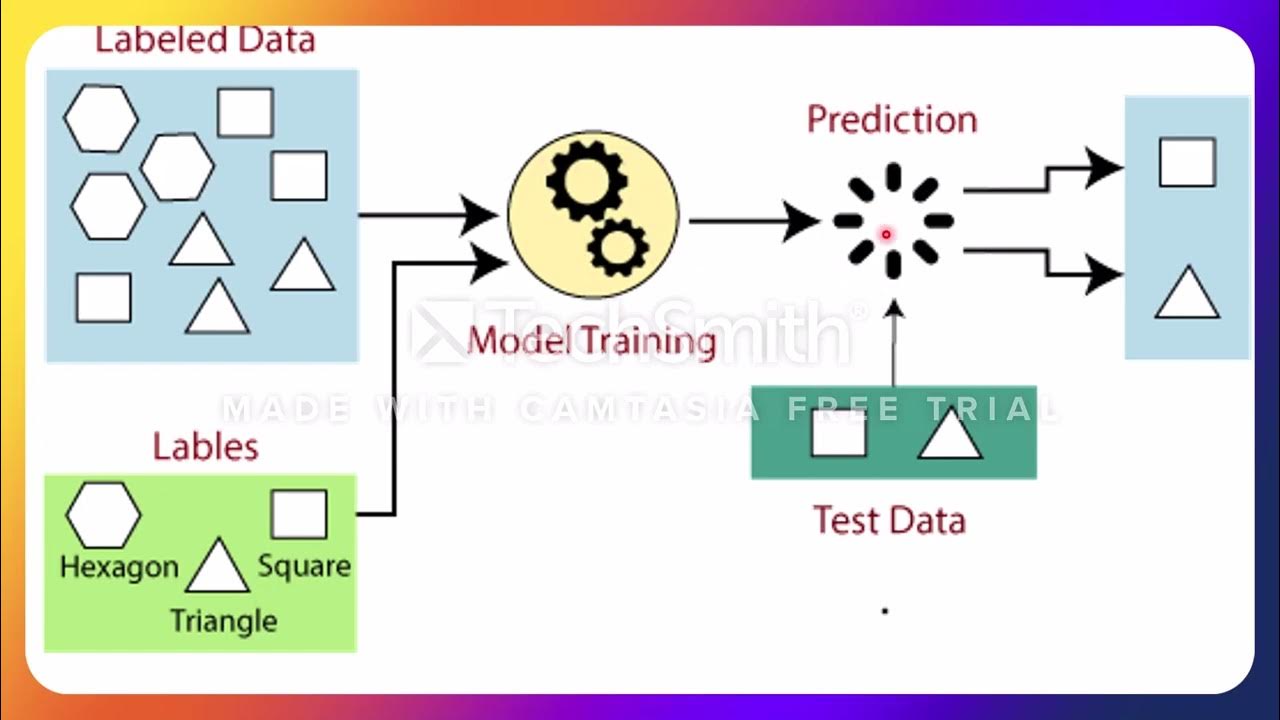
- 🔧 The training process in supervised learning involves selecting a tunable function that minimizes the training error through optimization.
- 📉 Training error is computed as the average discrepancy between the actual and predicted values in the training data, but it is often too optimistic to estimate real-world performance.
- 🚫 The script emphasizes that training data should not be reused to estimate the performance of the model on unseen data, as this leads to an overestimation of the model's capabilities.
- 📈 Generalization error, or out-of-sample performance, is the error rate on future or unseen examples and is a more accurate measure of a model's performance.
- 🔑 To estimate generalization performance, the script suggests dividing the original training data into a training set and a test set, also known as holdout data.
- 🔄 K-fold cross-validation is presented as a method to improve the estimation of generalization performance by dividing the data into 'k' blocks and using each block as a validation set in turn.
- 🔢 The script explains that the choice of 'k' in k-fold cross-validation typically ranges from 5 to 10, with leave-one-out cross-validation being a special case where 'k' equals the number of data points.
- 🛠 After estimating the generalization performance, the model should be retrained with the entire dataset to obtain the final, best-performing model.
- 📝 The video concludes by summarizing the importance of distinguishing between training performance and generalization performance in machine learning.
Q & A
What is the main focus of the video script?
-The main focus of the video script is to discuss the concepts of generalization, performance in supervised learning, and to introduce techniques for measuring how well estimators would perform in real-world settings.
What is the purpose of having a tunable box in supervised learning?
-The tunable box in supervised learning is used to select the function with parameters that minimize the training error from a collection of possible functions, given the input examples and their respective labels.
What is the training error and how is it calculated in a regression problem?
-The training error is the discrepancy between the actual values (y_i) and the predicted values (y_hat) for the training data. In a regression problem, it is calculated as the average of the squared differences between y_i's and y_hats, typically represented as 1/m * Σ(y_i - y_hat)^2.
How is the training error calculated in a classification problem?
-In a classification problem, the training error is calculated by counting the number of incorrectly classified inputs and dividing it by the total number of training examples, represented as n.
Why is the training error not a good measure of model performance on unseen data?
-The training error is not a good measure of model performance on unseen data because it is computed using the same data that was used to select the model parameters, making it usually too optimistic and not indicative of the model's performance on new, unseen data.
What is meant by generalization performance in the context of machine learning?
-Generalization performance, also known as out-of-sample performance, refers to the error rate of a machine learning model on future or unseen data, which is the true measure of how well the model is expected to perform in real-world scenarios.
How can the generalization performance of a model be estimated?
-The generalization performance can be estimated by using techniques such as the train-test partition or k-fold cross-validation, which involve using a portion of the data for training and another portion for validation to simulate unseen data.
What is the typical data split ratio for the train-test partition method?
-The typical data split ratio for the train-test partition method is 80% for training and 20% for testing, although other ratios like 70%-30% are also used.
Can you explain the concept of k-fold cross-validation?
-K-fold cross-validation is a technique where the training data is divided into 'k' blocks or folds. The model is trained k times, each time using k-1 folds for training and the remaining fold for validation. The average error from these k iterations provides an estimate of the model's generalization performance.
What is the final step after estimating the generalization performance using k-fold cross-validation?
-The final step is to retrain the model with the entire dataset to obtain the best tunable function, ensuring that all available data is used for training the final model.
Why is it important to retrain the model with the whole dataset after k-fold cross-validation?
-Retrain the model with the whole dataset to leverage all available data for training, which can potentially improve the model's performance, as the model has not been trained on this combined dataset before.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahora




5.0 / 5 (0 votes)
