Self-supervised learning and pseudo-labelling
Summary
TLDRThis video delves into self-supervised learning and pseudo-labeling, key concepts in machine perception. It highlights the limitations of supervised learning and explores how self-supervised learning, inspired by human multimodal learning, can improve model performance. The video discusses various pretext tasks and the instance discrimination approach, which leverages visual similarity for representation learning. Additionally, it covers pseudo-labeling in semi-supervised learning, demonstrating its effectiveness in tasks like word sense disambiguation and image classification, showcasing its potential in handling large unannotated datasets.
Takeaways
- 🤖 **Self-Supervised Learning Motivation**: The need for self-supervised learning arises from the limitations of supervised learning, where large annotated datasets are required, and models still make mistakes that humans wouldn't.
- 👶 **Inspiration from Human Development**: Human babies learn in an incremental, multi-modal, and exploratory manner, which inspires self-supervised learning methods that mimic these natural learning strategies.
- 🔄 **Redundancy in Sensory Signals**: Self-supervised learning leverages redundancy in sensory signals, where the redundant part of the signal that can be predicted from the rest serves as a label for training a predictive model.
- 🧠 **Helmholtz's Insight**: The concept of self-supervision is rooted in Helmholtz's idea that our interactions with the world can be thought of as experiments to test our understanding of the invariant relations of phenomena.
- 🐮 **Self-Supervised Learning Defined**: It involves creating supervision from the learner's own experience, such as predicting outcomes based on movements or changes in the environment.
- 🔀 **Barlow's Coding**: Barlow's work suggests that learning pairwise associations can be simplified by representing events in a way that makes them statistically independent, reducing the storage needed for prior event probabilities.
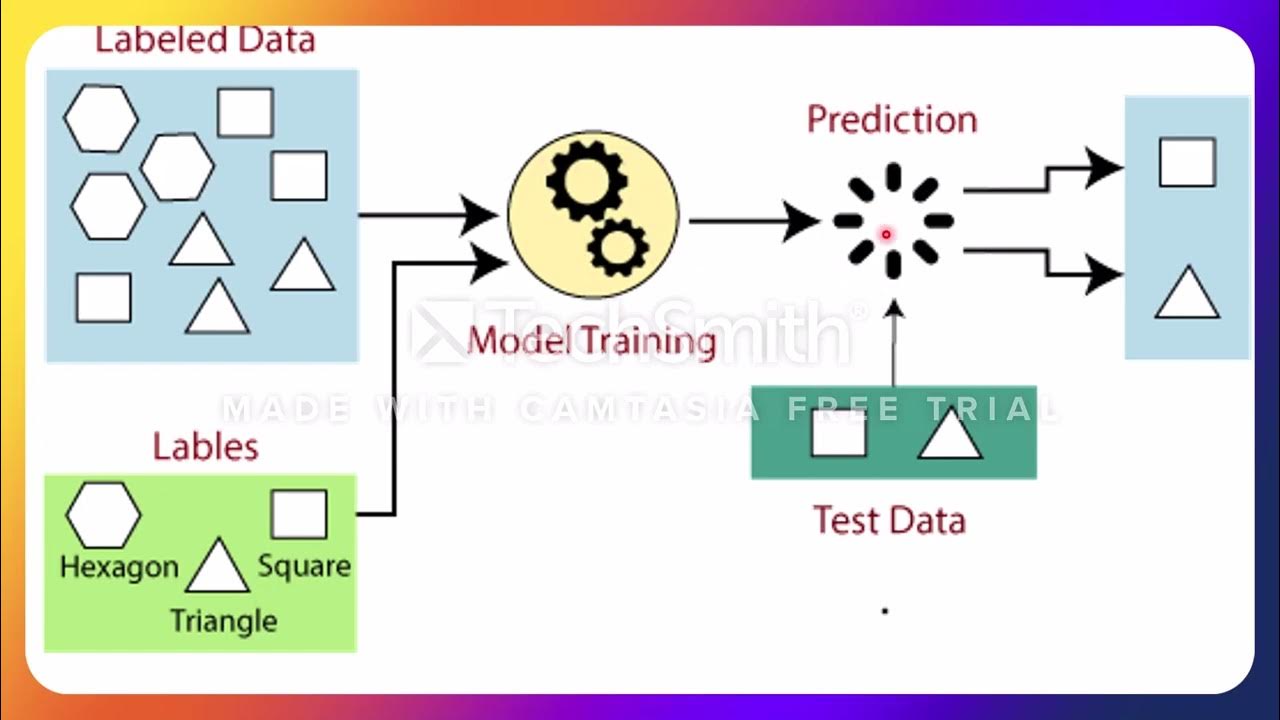
- 📈 **Pseudo-Labeling**: Pseudo-labeling is a semi-supervised learning technique where a model predicts labels for unlabeled data, which are then used to retrain the model, often leading to improved performance.
- 🎲 **Pretext Tasks**: In computer vision, pretext tasks like image patch prediction or jigsaw puzzles are used to train models without explicit labeling, hoping they learn useful representations of the visual world.
- 🔄 **Instance Discrimination**: A powerful self-supervised learning approach that trains models to discriminate between individual instances, leading to better visual similarity capture compared to semantic class discrimination.
- 🔧 **Practical Challenges**: There are practical challenges in creating effective pretext tasks, such as the risk of models learning to 'cheat' by exploiting unintended cues rather than understanding the task's underlying concepts.
Q & A
What are the two main topics discussed in the video?
-The two main topics discussed in the video are self-supervised learning and pseudo-labeling.
What is the motivation behind self-supervised learning?
-The motivation behind self-supervised learning is to improve machine perception by taking inspiration from early stages of human development, particularly the way humans learn in a multi-modal and incremental manner.
How does self-supervised learning differ from supervised learning?
-In self-supervised learning, the learner creates its own supervision by exploiting redundant signals from the environment, whereas in supervised learning, a model is trained using manually annotated data.
What is the role of redundancy in sensory signals in self-supervised learning?
-Redundancy in sensory signals provides labels for training a predictive model by allowing the learner to predict one part of the signal from another, thus creating a learning target without external supervision.
What is a pretext task in the context of self-supervised learning?
-A pretext task is a task that is not the final goal but is used to learn useful representations of the data. It is often a game-like challenge that the model must solve, which in turn helps it learn about the visual world.
What is pseudo-labeling and how does it work?
-Pseudo-labeling is a semi-supervised learning algorithm where a classifier is first trained on labeled data, then used to predict labels for unlabeled data. These predicted labels, or pseudo-labels, are then used to retrain the classifier, often iteratively.
Why is pseudo-labeling effective when large quantities of data are available?
-Pseudo-labeling is effective with large data sets because it leverages the unlabeled data to improve the classifier's predictions, leading to better performance, especially when combined with techniques like data augmentation.
What is the 'noisy student' approach mentioned in the video?
-The 'noisy student' approach is a method where an initial model trained on labeled data infers pseudo-labels for unlabeled data, and then a higher capacity model is trained on these pseudo-labeled data, often with heavy use of data augmentation.
How does self-supervised learning relate to human perception development?
-Self-supervised learning relates to human perception development by mimicking the way humans learn from their environment through exploration and interaction, without the need for explicit labeling.
What challenges are there in creating effective pretext tasks for self-supervised learning?
-Creating effective pretext tasks can be challenging because they need to be designed carefully to ensure the model learns useful representations rather than exploiting unintended shortcuts or low-level signals.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video





5.0 / 5 (0 votes)